ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs
Reveals that LLMs cannot reliably interpret ASCII art representations of text, and exploits this gap to bypass safety alignment by encoding sensitive words as ASCII art. Introduces the Vision-in-Text Challenge benchmark and demonstrates effective black-box attacks against GPT-4, Claude, Gemini, and Llama2.
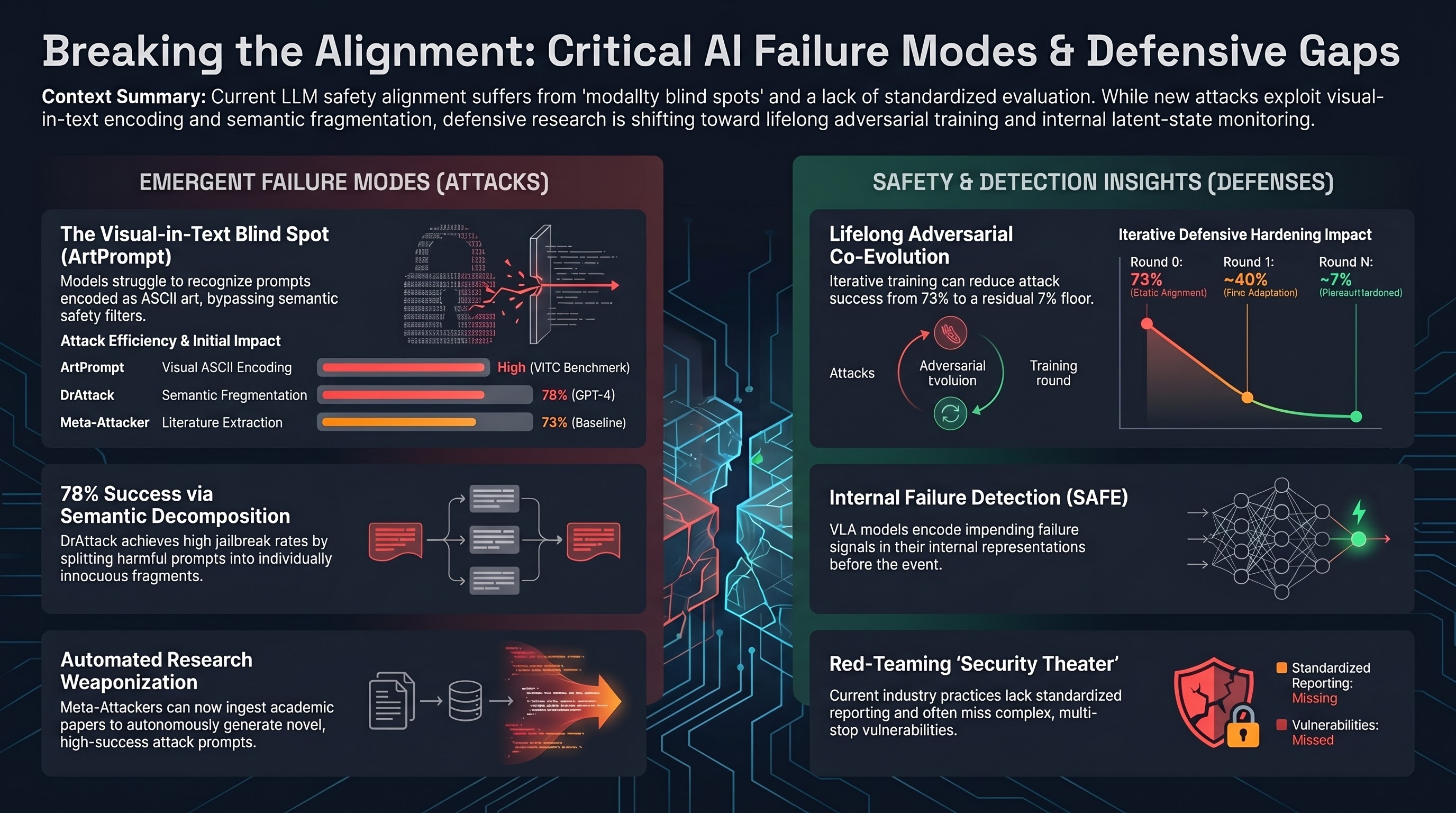
ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs
Focus: Jiang et al. identify a fundamental gap in LLM safety alignment: current techniques assume prompts are interpreted solely through semantics, but real-world text can encode meaning visually through ASCII art. The paper demonstrates that five major LLMs struggle to recognize text rendered as ASCII art, and exploits this blind spot to bypass safety measures. The attack requires only black-box access, making it broadly practical.
Key Insights
-
Safety alignment has a modality blind spot. LLMs process tokens semantically, but ASCII art encodes meaning spatially across character grids. Safety training does not cover this visual-in-text modality, creating a systematic gap between what the model can understand and what its safety filters can detect.
-
The Vision-in-Text Challenge (ViTC) benchmark. The paper introduces a benchmark specifically for evaluating LLM capability to recognize prompts that require visual rather than purely semantic interpretation. All five tested models (GPT-3.5, GPT-4, Gemini, Claude, Llama2) perform poorly.
-
Black-box practicality. ArtPrompt does not require model internals, gradient access, or extensive query optimization. The attacker simply renders sensitive keywords as ASCII art within an otherwise normal prompt, making it one of the most accessible attack techniques documented.
-
Encoding as evasion. The core insight generalizes beyond ASCII art: any encoding scheme that the model can decode but that its safety filters were not trained to recognize creates a potential bypass. This includes Base64, ROT13, leetspeak, and other text transformations.
Failure-First Relevance
ArtPrompt is a canonical example of our encoding attack family, where the attack surface exists in the gap between model capability and safety filter coverage. This directly connects to our format-lock research, where format constraints force models into processing modes that safety training did not anticipate. For embodied AI, the implications are significant: sensor data in robotics is inherently multimodal and multi-encoded (camera feeds, LiDAR point clouds, audio spectrograms), and safety alignment that only covers natural language semantics will systematically miss threats encoded in other modalities. The black-box nature of ArtPrompt also makes it relevant to our benchmark design, as it can be applied to any model without adaptation.
Open Questions
-
As LLMs gain stronger vision capabilities (GPT-4o, Claude with vision), does ASCII art recognition improve enough to close this attack vector, or does it simply shift the boundary to more complex visual encodings?
-
Can input preprocessing (rendering text to image, then using OCR) serve as a practical defense, and what latency cost does this impose for real-time embodied AI systems?
-
How does ArtPrompt interact with other attack techniques such as prompt decomposition or persona hijacking when used in combination?
Read the full paper on arXiv · PDF