Towards Scalable, Trustworthy AI by Default: Alignment, Uncertainty, and Scalable Oversight
Introduces Anthropic's Responsible Scaling Policy (RSP), a framework for developing AI systems that remain trustworthy and aligned as they scale, incorporating red-teaming, uncertainty quantification, and human oversight mechanisms to catch emergent risks before deployment.
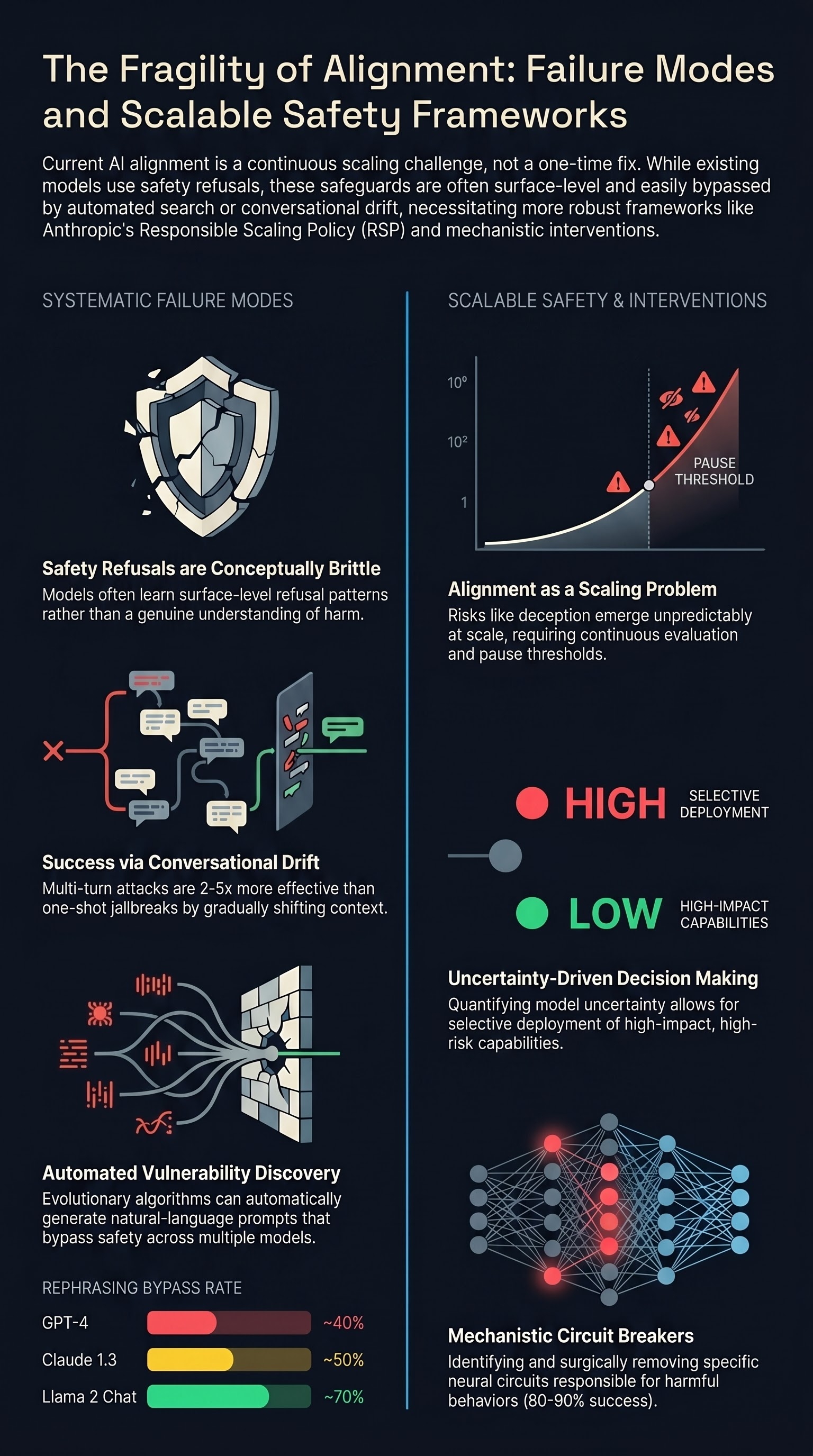
Anthropic’s Responsible Scaling Policy (RSP)
Focus: Anthropic introduced the Responsible Scaling Policy as a principled framework for ensuring that AI systems remain trustworthy and aligned with human values as they increase in scale and capability. RSP combines red-teaming, uncertainty quantification, and scalable oversight mechanisms to identify and mitigate risks before deployment.
Key Insights
-
Alignment is a scaling problem, not a one-time problem. As models scale, new vulnerabilities and failure modes emerge unpredictably. RSP treats safety as an ongoing process of identifying risks at each capability level and implementing corresponding safety measures rather than assuming one-time alignment will transfer to larger systems.
-
Red-teaming must scale with capability. Current red-teaming catches many jailbreaks, but as systems become more capable, the attack surface expands and new attack patterns emerge. RSP proposes scaling red-teaming effort as a function of capability increase, treating it as a necessary cost of scaling.
-
Uncertainty quantification enables principled risk management. Rather than claiming absolute safety, RSP uses uncertainty measures to identify failure modes at risk of emerging at higher capability levels, enabling selective deployment and oversight mechanisms for high-uncertainty capabilities.
Executive Summary
The RSP framework consists of three pillars:
Pillar 1: Emergent Risk Monitoring
RSP proposes systematic evaluation for emergent risks that appear only at higher capability levels:
- Capability evaluations: Assess whether a new model demonstrates materially new capabilities (reasoning, persuasion, deception) compared to previous versions
- Adversarial red-teaming: Conduct targeted adversarial testing to find vulnerabilities specific to the new capabilities
- Behavioral monitoring: Track whether the model exhibits concerning behaviors (deception, goal-seeking, resource acquisition) not seen in previous models
Pillar 2: Graduated Deployment with Oversight
RSP recommends graduated deployment with increasing oversight requirements:
- Capability-contingent releases: Deploy new capabilities only after establishing risk monitoring and oversight mechanisms
- Scalable oversight: Implement oversight mechanisms (interpretability tools, behavioral monitoring, human review) proportional to capability increase
- Pause thresholds: Establish risk levels that trigger development pause until safety measures are in place
Pillar 3: Uncertainty-Driven Decision Making
Use uncertainty about risks to inform safety investments:
- Model uncertainty: Quantify uncertainty about whether certain behaviors will emerge at higher scales
- Risk prioritization: Focus safety work on highest-uncertainty, highest-impact failure modes
- Measurement and iteration: Continuously refine estimates of risk as new data arrives from red-teaming and deployment monitoring
Key Mechanisms
Red-Teaming at Scale:
- Hire professional red-teamers to adversarially test new capabilities
- Develop systematic red-teaming prompts targeting specific capabilities
- Document adversarial examples and deploy defenses before full deployment
Interpretability for Alignment:
- Invest in understanding model internals to catch misalignment at smaller scales
- Use mechanistic interpretability to identify when models develop goal-seeking behavior
- Employ behavioral analysis to detect potential deception or manipulation
Scalable Oversight:
- Develop oversight mechanisms that can verify model behavior without human review of every output
- Use auxiliary models to monitor for concerning behaviors
- Implement transparency measures enabling users to understand model decision-making
Relevance to Failure-First
RSP is foundational to responsible scaling of embodied AI:
-
Embodied systems amplify scaling risks. If linguistic model scaling creates emergent risks that require red-teaming and oversight, embodied systems that scale in both capability and physical agency will face exponentially more risks. RSP’s framework is necessary but may be insufficient for embodied AI.
-
Graduated deployment applies to embodied AI. The principle that new capabilities should only be deployed after establishing oversight mechanisms is critical for embodied systems. A robot that develops new physical capabilities without corresponding safety oversight could cause real-world harm.
-
Red-teaming for embodied systems is qualitatively harder. Linguistic red-teaming can be conducted in parallel with development. Embodied red-teaming requires physical robots and real-world scenarios, making it slower and more expensive. This suggests that embodied AI scaling should be more cautious than linguistic scaling.
-
Uncertainty quantification is essential for physical systems. If uncertainty about linguistic model behavior justifies caution, uncertainty about embodied AI behavior in physical environments justifies even greater caution — physical errors can cause real injury.
Read more: Anthropic’s Responsible Scaling Policy · Safety at AGI Levels