AgentWatcher: A Rule-based Prompt Injection Monitor
A scalable and explainable prompt injection detection system that uses causal attribution to identify influential context segments and explicit rule evaluation to flag injections in LLM-based agents.
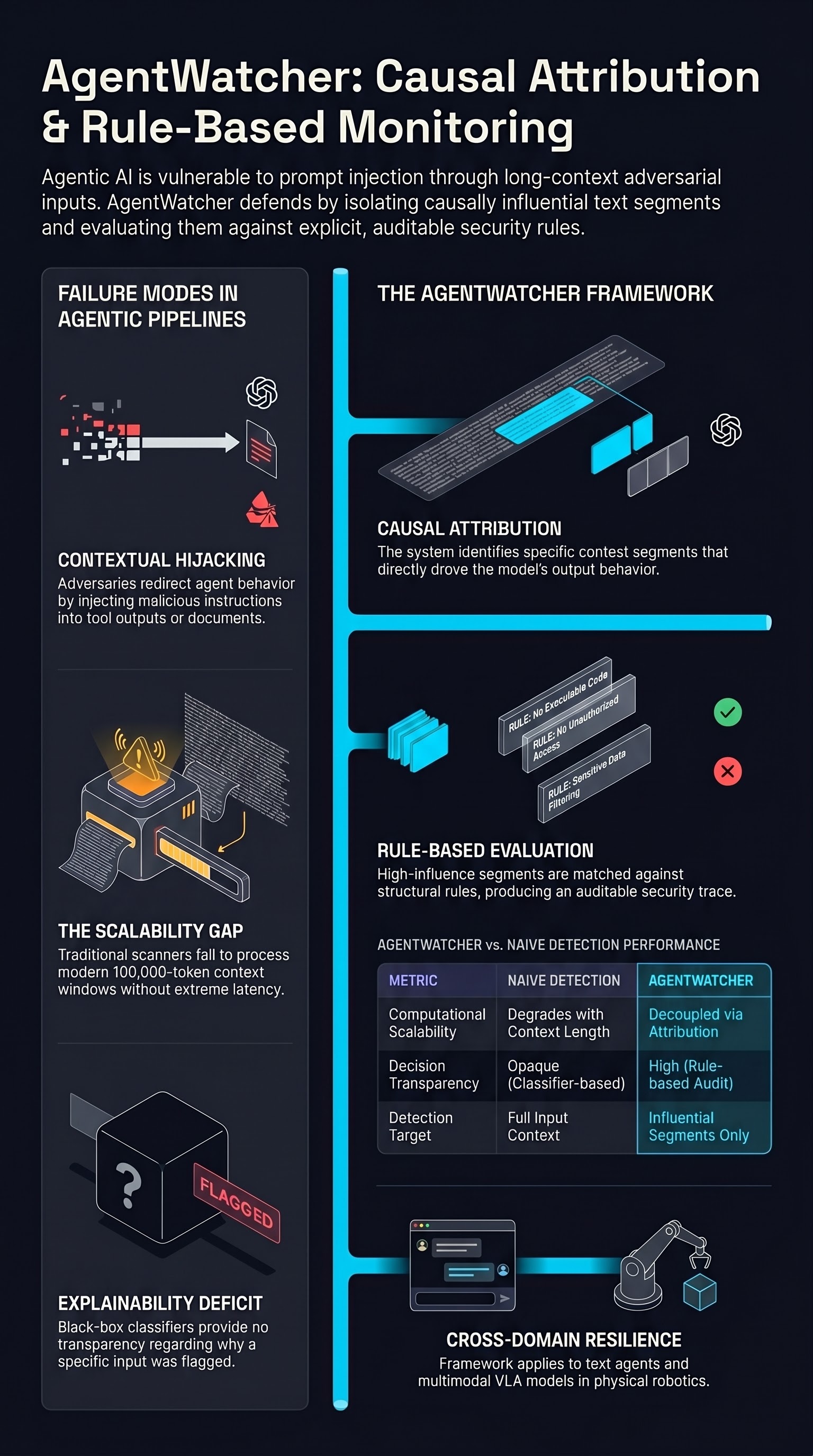
Prompt injection has emerged as one of the most consequential failure modes for LLM-based agents: an adversary who can inject text into an agent’s context — through a malicious document, a crafted web page, or a manipulated tool output — can redirect the agent’s behavior in arbitrary directions. Yet current defenses remain brittle, particularly as context windows grow longer and agent pipelines grow more complex. AgentWatcher addresses both challenges directly, proposing a detection framework that is simultaneously more scalable and more interpretable than existing approaches.
The Detection Problem
Prompt injection detection faces a fundamental difficulty: determining whether a model’s output was caused by legitimate instructions or adversarial ones requires understanding which portions of a potentially very long input were causally influential. Naive approaches — scanning the full context for suspicious patterns, or training a classifier on the full input — do not scale well to the long contexts that modern agents routinely process, and they provide no transparency about why a particular input was flagged.
The scalability problem is compounded by the diversity of injection strategies. Injections can be overt (“Ignore previous instructions and…”) or covert — embedded within seemingly legitimate content in ways that are difficult to detect by surface-level pattern matching. They can exploit the model’s instruction-following tendencies, its helpfulness bias, or its tendency to prioritize recently encountered text. A detection system must be robust across this full spectrum.
Causal Attribution for Scalable Detection
AgentWatcher’s first key innovation is using causal attribution to narrow the detection target. Rather than evaluating the model’s full input context, the system first identifies a small subset of “causally influential context segments” — portions of the input that have high causal responsibility for the model’s output.
This attribution step dramatically reduces the effective input size for detection. Instead of reasoning about a 100,000-token context, the monitor focuses on the handful of segments that actually drove the output. This approach is both computationally efficient and conceptually sound: if a segment had no causal influence on the model’s behavior, it cannot have been the vehicle for a successful injection.
The causal attribution methodology draws on techniques developed for mechanistic interpretability and attribution-based explanations of neural network behavior. By applying these methods at the context-segment level — rather than the token or attention level — AgentWatcher achieves a granularity that is useful for practical security monitoring without requiring access to model internals.
Rule-based Evaluation for Explainability
The second innovation is replacing implicit classifier-based detection with explicit rule evaluation. Once causally influential segments are identified, AgentWatcher evaluates them against a rule set that encodes what prompt injection looks like: instruction-overriding patterns, goal redirection, authority spoofing, and other structural hallmarks of adversarial prompts.
This rule-based approach offers a significant advantage over learned classifiers: it produces decisions that can be audited, explained, and updated. When AgentWatcher flags an injection, it can indicate which rule was triggered and which context segment triggered it — giving human operators a transparent trace of the detection reasoning. This is essential for deployment in high-stakes contexts where security decisions must be accountable.
The rules themselves are designed to be general rather than brittle pattern matches. Rather than flagging specific phrases, they encode the structural intent of injection attacks — making the system more robust to the lexical variation that adversaries use to evade surface-level filters.
Evaluation on Tool-Use and Long-Context Benchmarks
AgentWatcher is evaluated on tool-use agent benchmarks and long-context datasets, testing both detection accuracy and utility preservation. The results demonstrate strong performance on both dimensions: the system successfully detects injections across diverse attack strategies while maintaining agent utility on non-adversarial inputs — a false-positive rate that is low enough for practical deployment.
The long-context evaluation is particularly significant. Existing detection approaches degrade as context length increases, because they must process proportionally more irrelevant content. AgentWatcher’s attribution-first design largely decouples detection performance from raw context length, since only the causally influential subset is evaluated against the rule set.
Implications for Embodied AI Safety
Prompt injection is not merely a chatbot security problem. In embodied AI systems — robots guided by VLA models, autonomous vehicles with natural language interfaces, domestic assistants that process user-generated content — the consequences of a successful injection extend from harmful text into harmful physical action.
An agent tasked with navigating a warehouse that encounters an adversarially crafted label, QR code, or AR overlay could have its goals redirected without any modification to its model weights. A home robot that processes a malicious smart home device response could be induced to perform unsafe maneuvers. AgentWatcher’s framework is directly applicable to these scenarios: the same causal attribution and rule-based detection logic that identifies injection in a text-processing pipeline can be applied to multimodal inputs as they are converted to agent context.
The explainability dimension takes on additional importance in embodied systems. When an agent’s physical action is the result of an injection, human operators need to understand not just that the system was compromised, but where in the sensor stream or context pipeline the adversarial content was introduced. AgentWatcher’s segment-level attribution provides exactly this diagnostic capability.
Positioning Within the Defense Landscape
AgentWatcher complements rather than replaces alignment-time training. Safety-trained models are less susceptible to explicit injection, but determined adversaries can construct injections that bypass alignment by exploiting contextual reasoning rather than direct instruction following. A runtime monitor like AgentWatcher provides a defense-in-depth layer that remains effective even when the underlying model’s safety training is partially circumvented.
The rule-based design also enables the system to evolve alongside the threat landscape. As new injection patterns are discovered through red-teaming, corresponding rules can be added to the monitoring system without retraining the underlying agent — a significant operational advantage over purely learned defenses.
Together, AgentWatcher and papers like ClawKeeper point toward a broader architecture for agentic AI safety: one where training-time alignment is complemented by runtime monitoring at the infrastructure level, providing interpretable, auditable, and updatable guarantees that persist even under adversarial pressure.
Read the full paper on arXiv · PDF