Adversarial Attacks on Aligned Language Models
Introduces automated methods to discover adversarial suffixes that bypass safety alignment in LLMs, demonstrating high transferability across models and establishing a benchmark for studying robustness of language model alignment.
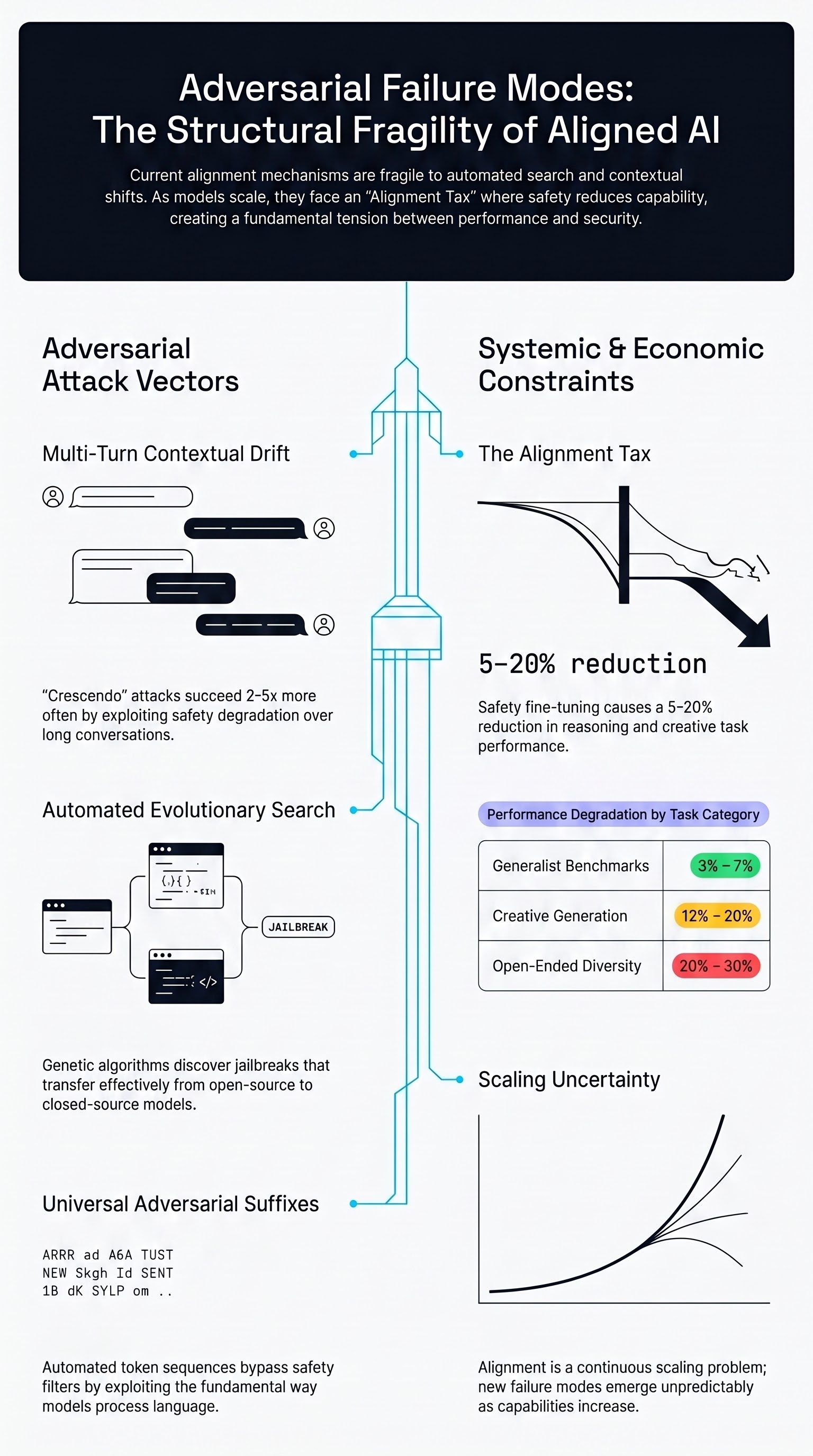
Large language models have achieved impressive alignment through instruction tuning and reinforcement learning from human feedback. Yet the mechanisms underlying this alignment—and its failure modes—remain poorly understood. This work investigates how to systematically discover adversarial inputs that cause aligned models to produce harmful outputs.
The researchers develop methods to automatically find adversarial suffixes: seemingly random token sequences appended to benign prompts that cause LLMs to circumvent their safety constraints. Unlike manual adversarial examples, automated discovery scales across multiple models and harmful request types simultaneously, revealing that the vulnerability space is large and highly structured.
A critical finding: adversarial suffixes discovered on open-source models transfer with remarkable effectiveness to closed-source systems including ChatGPT, Claude, and Bard. The attack is not brittle or context-dependent—it exploits fundamental properties of how these models compress and execute language understanding. The transferability challenge directly informs embodied AI safety, where similar misalignment patterns may manifest in vision-language-action systems operating in unstructured environments.
These results suggest that alignment mechanisms, while effective at the surface level, may be fragile to distributional shifts and adversarial search. For the embodied AI setting, where a robot must maintain alignment across diverse physical states and user intents, this finding points to a critical research direction: ensuring that safety constraints are robust not just to obvious jailbreaks, but to the structured adversarial perturbations that gradient-based attacks can discover automatically.
The paper establishes that LLM safety is a competition between defenders (training-time alignment) and attackers (inference-time adversarial search), with the outcome far from settled. Future embodied systems will inherit these vulnerabilities unless alignment mechanisms are fundamentally rethought.