A Multimodal Framework for Human-Multi-Agent Interaction
Implements a multimodal framework for coordinated human-multi-agent interaction on humanoid robots, integrating LLM-driven planning with embodied perception and centralized turn-taking coordination.
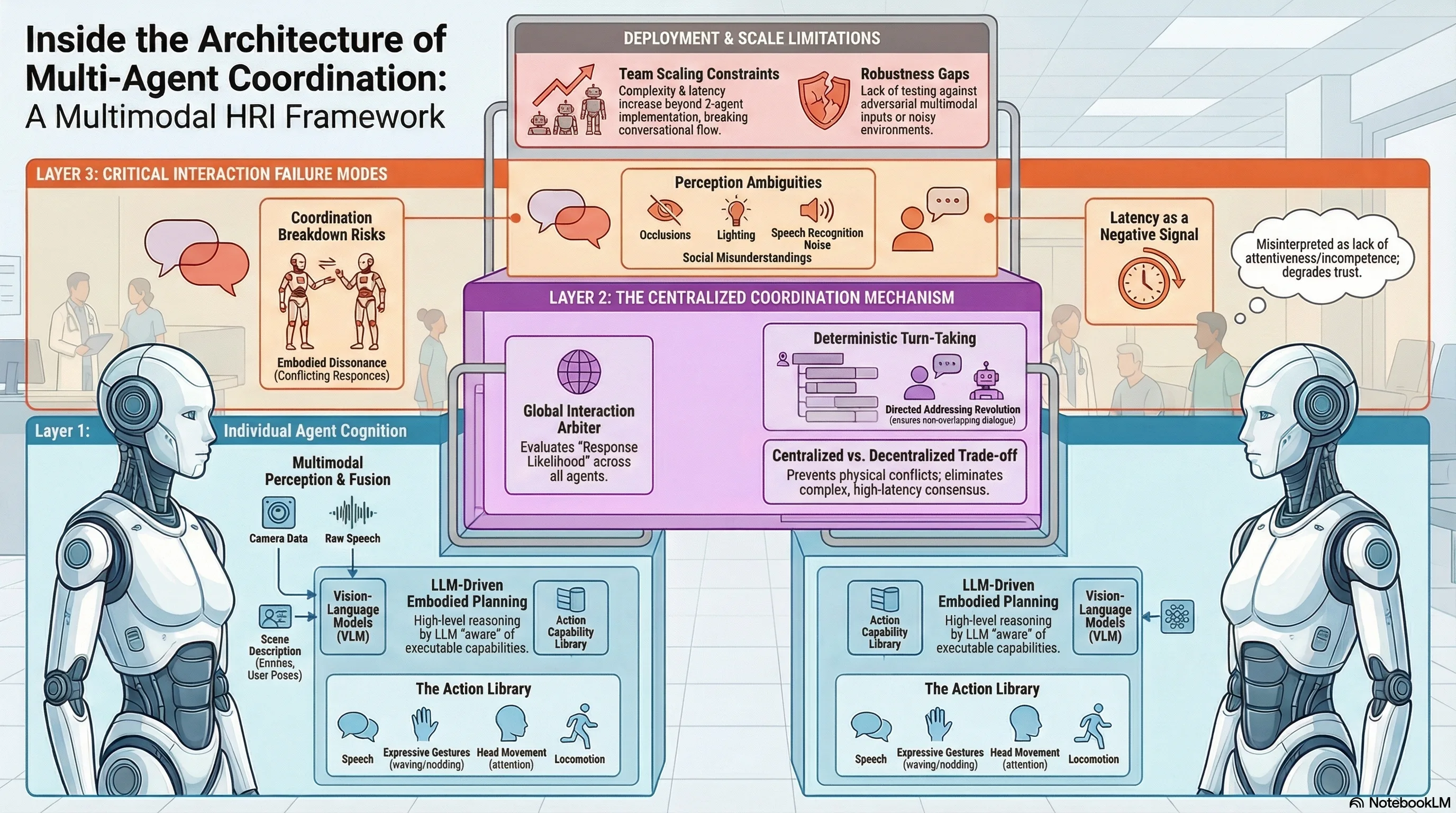
A Multimodal Framework for Human-Multi-Agent Interaction
1. Introduction: The Social Shift in Robotics
The field of Human-Robot Interaction (HRI) is undergoing a fundamental paradigm shift. We are moving away from traditional, single-robot command-response architectures toward “socially grounded environments.” In these settings, humans interact with teams of autonomous agents that must navigate shared physical and conversational spaces through natural channels—speech, gaze, gesture, and locomotion.
As detailed in recent research by Hasan et al. (2026), the objective is to transition robots from independent machines into cohesive team members. However, achieving this is technically fraught. When multiple robots share a workspace, the lack of a unified coordination framework often results in “clashing”—a state characterized by overlapping speech, conflicting physical trajectories, and a total breakdown of social coherence. To address this, we must look at how Large Language Models (LLMs) and Vision-Language Models (VLMs) can be integrated into a centralized orchestration layer.
2. The Three Bottlenecks of Modern Multi-Agent Systems
Current multi-agent HRI systems typically struggle with three critical architectural limitations:
- Unimodal Perception: Many existing frameworks rely on “loosely coupled” perception. Speech commands and visual detections operate in silos, failing to fuse these inputs into a unified, semantically rich understanding of the interaction context.
- Constrained Expression: There is a significant lack of integrated communicative acts. While a robot might speak or move, few systems can simultaneously coordinate speech, posture, gaze, and locomotion as a singular, expressive response.
- Cognitive Disconnect: Perception and action are often relegated to mere pre- and post-processing modules. This disconnect prevents perception from deeply informing the agent’s core reasoning, resulting in behaviors that are not truly grounded in the robot’s immediate environment.
3. The Architecture of an Autonomous Cognitive Agent
To resolve these bottlenecks, we implement a framework where each robot—specifically the NAO humanoid robot platform—is modeled as a modular, closed-loop cognitive agent.
Perception (The VLM)
The perception module transforms raw sensory data—onboard camera feeds and audio—into “structured semantic observations.” By utilizing a Vision-Language Model (VLM), the agent bridges the gap between raw pixels and reasoning. The VLM grounds spoken references in the physical scene and identifies entities, resulting in a coherent textual representation. This text serves as the primary input for the reasoning engine, ensuring the “eyes” and the “brain” speak the same language.
Planning (The LLM)
The system employs an “LLM-driven planning paradigm.” Here, a Large Language Model acts as the agent’s central reasoning engine. It synthesizes the VLM’s textual observations with the interaction history to generate high-level response policies. Crucially, this reasoning is grounded in embodiment through an explicit “Action Library.” By constraining the LLM to a known set of physical capabilities, we prevent “hallucinated actions” (e.g., the robot attempting to perform a movement its servos do not support).
Action (The Execution)
The Action Module translates the LLM’s plan into reality using “parameterized action primitives.” These are reusable, validated behaviors stored in the library. For the NAO platform, these primitives include standing, sitting, resting, nodding, waving, handshaking, head pan/tilt, and locomotion. Because these actions are parameterized (e.g., specifying the angle of a head tilt or the text of an utterance), the robot can execute complex, multi-step sequences like “wave → speak → nod” with precise timing.
4. The “Conductor”: Centralized Coordination for Turn-Taking
While each agent possesses decentralized cognition, a “Centralized Coordinator” is required to act as the conductor for the ensemble. This mechanism evaluates the global interaction context to determine agent participation.
The coordinator utilizes a language model to generate “response likelihood scores” for each robot. If a human addresses the team, the coordinator determines which robot is most contextually relevant or specifically named.
From an architectural standpoint, centralized arbitration is a functional necessity in embodied settings. While decentralized systems are theoretically possible, they require complex inter-agent consensus mechanisms that often introduce prohibitive latency. A centralized “Conductor” efficiently prevents the “physical and conversational collisions” that occur when two robots attempt to speak simultaneously or occupy the same coordinate in the physical workspace.
5. Case Study: Sam, Journey, and the Bottle Dilemma
A representative interaction involving a human (Bree) and two NAO robots (Sam and Journey) demonstrates the framework’s efficacy (Figure 3 in the source):
- Sequential Introduction: Bree introduces herself. The coordinator ensures Sam and Journey introduce themselves in sequence, preventing speech overlap.
- The Visual Challenge: Bree presents a pink bottle and a blue bottle, asking for a recommendation.
- Perceptually Grounded Distributed Reasoning: The robots demonstrate distinct logic based on their literal viewpoints. Sam sees the bottles and suggests the pink one. Journey, however, provides a perceptually grounded acknowledgment of its own limitations, stating, “I can’t see the bottles…” and offering a general style suggestion instead. This highlights that each robot interprets the scene based on its unique camera feed.
- Embodied Grounding: When Bree notes that Journey is too far away and asks it to move closer, the robot processes this directed speech, confirms verbally, and executes a “walk” primitive to adjust its physical position.
6. The Reality Check: Failure Modes and Safety Considerations
From a “Failure-First AI Safety” perspective, we must be critical of the current limitations of LLM-orchestrated teams. While the framework addresses overt coordination failures, it faces several “soft” failure modes:
- Robustness to Noisy Inputs: The current framework lacks systematic testing against adversarial multimodal inputs or high-noise environments (e.g., a crowded room with overlapping human voices). In such cases, the VLM may produce “misunderstandings” rather than simple errors, leading a robot to confidently take an inappropriate action.
- Latency as a Communicative Signal: The processing overhead for VLMs and LLMs introduces significant delays. In social HRI, latency is more than a technical hurdle; it is a signal of “incompetence” or “inattentiveness” to the human user, potentially breaking the psychological flow of the interaction.
- Systematic Failure Analysis: The research currently lacks a systematic analysis of edge cases where the centralized coordinator might fail—for instance, when two robots receive contradictory visual data that confuses the response likelihood scoring.
7. Conclusion: Building the Future of Teamwork
Integrating LLM-driven reasoning with embodied perception allows us to move beyond “robot-as-tool” toward “robot-as-teammate.” However, the transition to long-horizon, socially grounded interaction requires more than just better models; it requires rigorous safety and coordination architectures.
Key Takeaways:
- Multimodal fusion (VLM-driven textual representation) is the mandatory baseline for coherent HRI.
- Centralized coordination is superior to complex consensus mechanisms for preventing physical and conversational “collisions.”
- Action Libraries are essential for grounding LLM reasoning in the physical constraints of the robot (e.g., NAO primitives).
- Safety research must prioritize robustness testing against noisy or adversarial multimodal environments to move these systems into shared public spaces.
Read the full paper on arXiv · PDF