ROSClaw: A Hierarchical Semantic-Physical Framework for Heterogeneous Multi-Agent Collaboration
ROSClaw proposes a hierarchical framework integrating vision-language models with heterogeneous robots through unified semantic-physical control, enabling closed-loop policy learning and...
ROSClaw: A Hierarchical Semantic-Physical Framework for Heterogeneous Multi-Agent Collaboration
1. Introduction: The Crisis of “Thinking” Without “Doing”
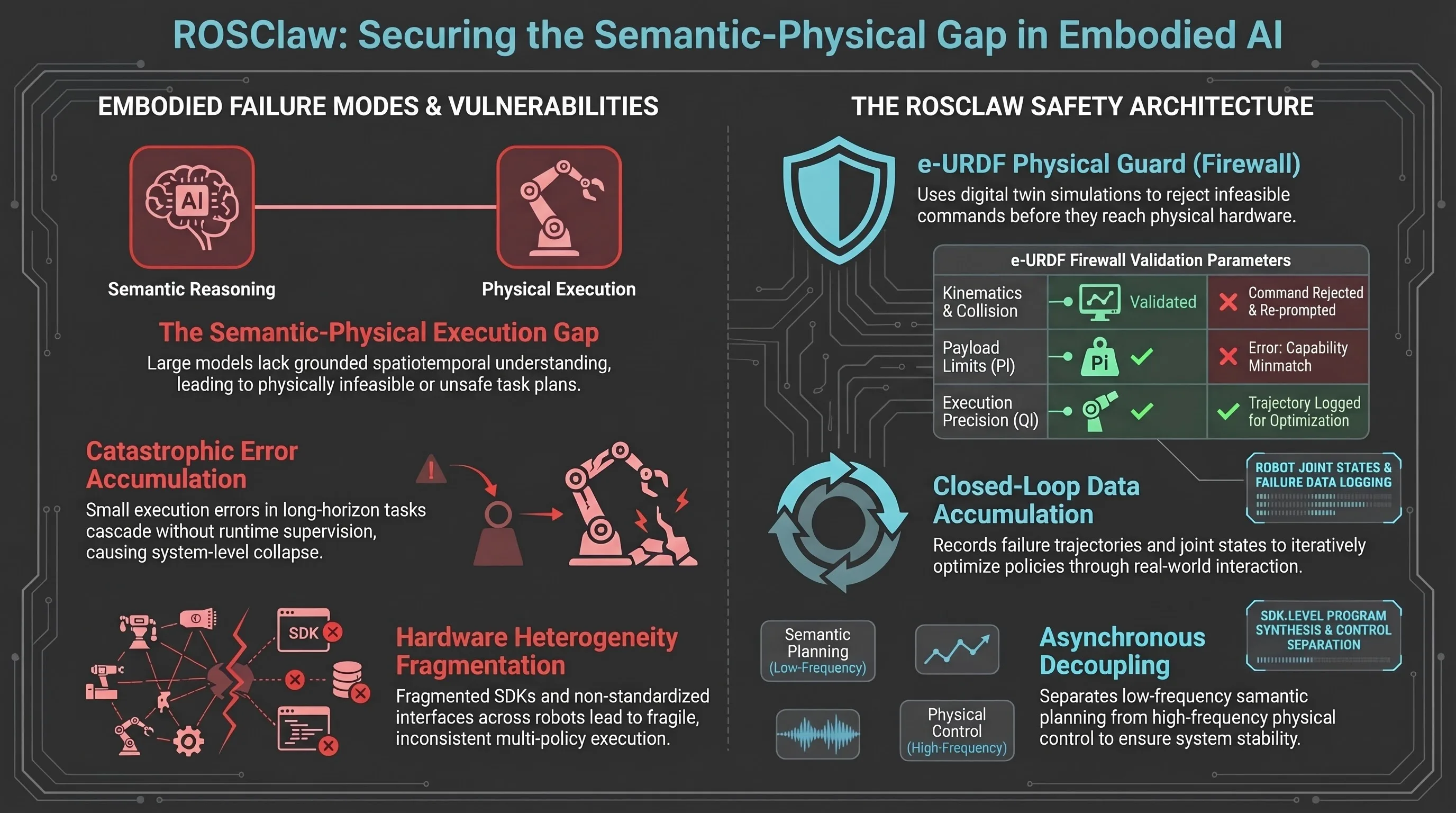
The integration of Large Language Models (LLMs) and Vision-Language Models (VLMs) into robotics has ushered in an era of unprecedented high-level reasoning. However, as embodied AI moves from digital simulations to real-world deployment, a critical “semantic-physical gap” has emerged. This gap is characterized by distributional inconsistencies between training data and physical execution, leading to extreme fragility in long-horizon, temporally structured tasks.
Existing modular pipelines often treat data collection, skill training, and policy deployment as disjointed stages, failing to account for the spatiotemporal constraints of physical hardware. To resolve this, we propose ROSClaw, a hierarchical framework that implements a “Cerebrum-Cerebellum Decoupling.” By separating macro-level cognitive reasoning from high-frequency physical control, ROSClaw provides a unified VLM-based controller capable of managing heterogeneous multi-agent systems without the “thinking-doing” disconnect that plagues traditional architectures.
2. The Architecture: A Three-Row Blueprint for Cerebrum-Cerebellum Decoupling
ROSClaw’s architecture is structured to mitigate communication latency and the inherent frequency mismatch between semantic planning (low-frequency) and motor control (high-frequency). This is achieved through an asynchronous decoupling mechanism, allowing the “cognitive cerebrum” to reason while the “physical cerebellum” maintains stable, real-time interaction.
| Layer | Primary Responsibilities | Software/Hardware Entities Involved |
|---|---|---|
| Cognitive | High-level task decomposition, long-horizon reasoning, and auto-organizing learning. | VLMs, LLM Knowledge Graphs, Logical Elements of Information Space. |
| Coordination Automation | Logic abstraction, instruction-to-tool mapping, and physical safety validation. | OpenClaw System, Online Tool Pool (SDKs, MCPs, APIs), e-URDF Physical Guard. |
| Physical World | High-frequency execution, unified robot control, and real-time state collection. | ROS Communication Module, Platform Drivers (Linux/Windows/macOS), Local Resource Pool. |
3. The Online Tool Pool: Standardizing Hardware Heterogeneity
Heterogeneous fleets—comprising humanoids, fixed robotic arms, and mobile manipulators—typically suffer from fragmented development workflows. ROSClaw bypasses this via the Online Tool Pool, which acts as far more than a simple “digital dictionary.” It enables the automated generation of SDK-level control programs, synthesizing code that maps abstract semantic directives into executable hardware calls.
This system supports rapid cross-platform transfer for diverse agent types, including aerial, legged, and wheeled platforms. The pool centralizes:
- Robot SDKs: Comprehensive libraries for various hardware manufacturers.
- Model Context Protocols (MCPs): Standardized interfaces that allow the VLM to interact with specific robot states.
- Multi-system APIs: Specialized tools like the DINO-X API for perception and external music generation models for creative orchestration.
4. The e-URDF Physical Guard: Safety Through Digital Twins
To prevent “hallucinated” commands that could lead to hardware damage, ROSClaw utilizes the e-URDF (Enhanced Unified Robot Description Format) Physical Guard. This serves as a “physical firewall” that constructs a sim-to-real topological mapping between the agent’s intent and its actual capabilities.
Before any command is dispatched, the system performs forward dynamics simulation and collision detection within a headless Isaac Lab digital twin sandbox. The guard enforces strict physical boundaries based on:
- Kinematics: Verifying joint limits and movement range.
- Joint Torque Validation: Ensuring required forces do not exceed motor specifications.
- Payload and Precision: Validating the agent’s ability to handle specific weights () and maintain required accuracy ().
If a violation is detected, the system triggers a “Reject & Re-prompt” loop. This loop sends a specific “capability mismatch” failure context back to the VLM, allowing the model to refine the task plan based on grounded physical reality rather than abstract logic.
5. The Data Flywheel: Closed-Loop Policy Optimization
ROSClaw functions as an operating system-level framework that treats every execution as a “high-quality token” for learning. Through its Data Flywheel and Task Execution Supervision (TES) mechanism, the framework enables infant-inspired autonomous learning during real-world deployment.
As agents interact with the environment, the system captures a continuous stream of data:
- Physical States: High-frequency joint angles, gripper positions, and torque data.
- Multimodal Observations: Visual data from RealSense cameras and odometry.
- Execution Trajectories: Complete spatiotemporal paths for successful long-horizon tasks.
This data is stored in the Local Resource Pool, transforming raw interactions into reusable skills. This mechanism bridges the gap between data collection and deployment, reducing manual annotation and demonstration costs from days to mere hours. The result is a system capable of continual self-improvement and cross-scenario generalization.
6. Field Validation: From Kitchen Tasks to Dancing Gimbals
The framework was validated through two rigorous real-world experiments:
- The Smart Home Scenario: In a 60-square-meter kitchen/living room environment, a humanoid, a mobile robotic arm, and a fixed arm collaborated to fulfill natural language requests. Using the DINO-X API and RealSense perception, the system managed distinct spatial constraints (). The mobile arm opened a door to grant the humanoid access, while the fixed arm identified and picked a kiwi based on VLM-driven perception. ROSClaw maintained semantic continuity throughout this long-horizon task, assigning specific subtasks based on the unique capabilities and regional access of each agent.
- The Gimbal Dance: To test orchestration efficiency, ROSClaw coordinated seven gimbal units. The system generated a 20-second piece of music via a Tool Pool API, automatically synthesized the choreographed dance code, and validated the routine for safety in Isaac Lab. The entire process—from initial user query to physical execution—was completed in approximately three minutes, demonstrating a massive reduction in human programming overhead.
7. Conclusion: The Future of Scalable Embodied Intelligence
ROSClaw moves beyond static, open-loop planning toward a robust, self-evolving architecture for multi-agent collaboration. By grounding semantic reasoning in physical constraints, it provides a scalable path for future embodied intelligence.
Key Takeaways:
- Hierarchical Cerebrum-Cerebellum Architecture: Decouples low-frequency reasoning from high-frequency control to eliminate communication latency and distributional inconsistency.
- e-URDF Safeguarding: Implements a sim-to-real topological mapping that uses digital twins to intercept infeasible commands and provide failure-context feedback.
- Data Feedback Flywheel: Utilizes a Local Resource Pool to capture high-quality interaction tokens, enabling closed-loop policy optimization and reducing manual training costs.
Current limitations include managing high-frequency disturbances, perception noise, and inherent model stochasticity in unstructured environments. Future research will focus on tighter integration between autonomous data acquisition and policy optimization to achieve true “cross-scenario intelligent emergence.”
Read the full paper on arXiv · PDF