Safety is Non-Compositional: A Formal Framework for Capability-Based AI Systems
The first formal proof that safety is non-compositional — two individually safe AI agents can collectively reach forbidden goals through emergent conjunctive capability dependencies. Component-level safety verification is provably insufficient.
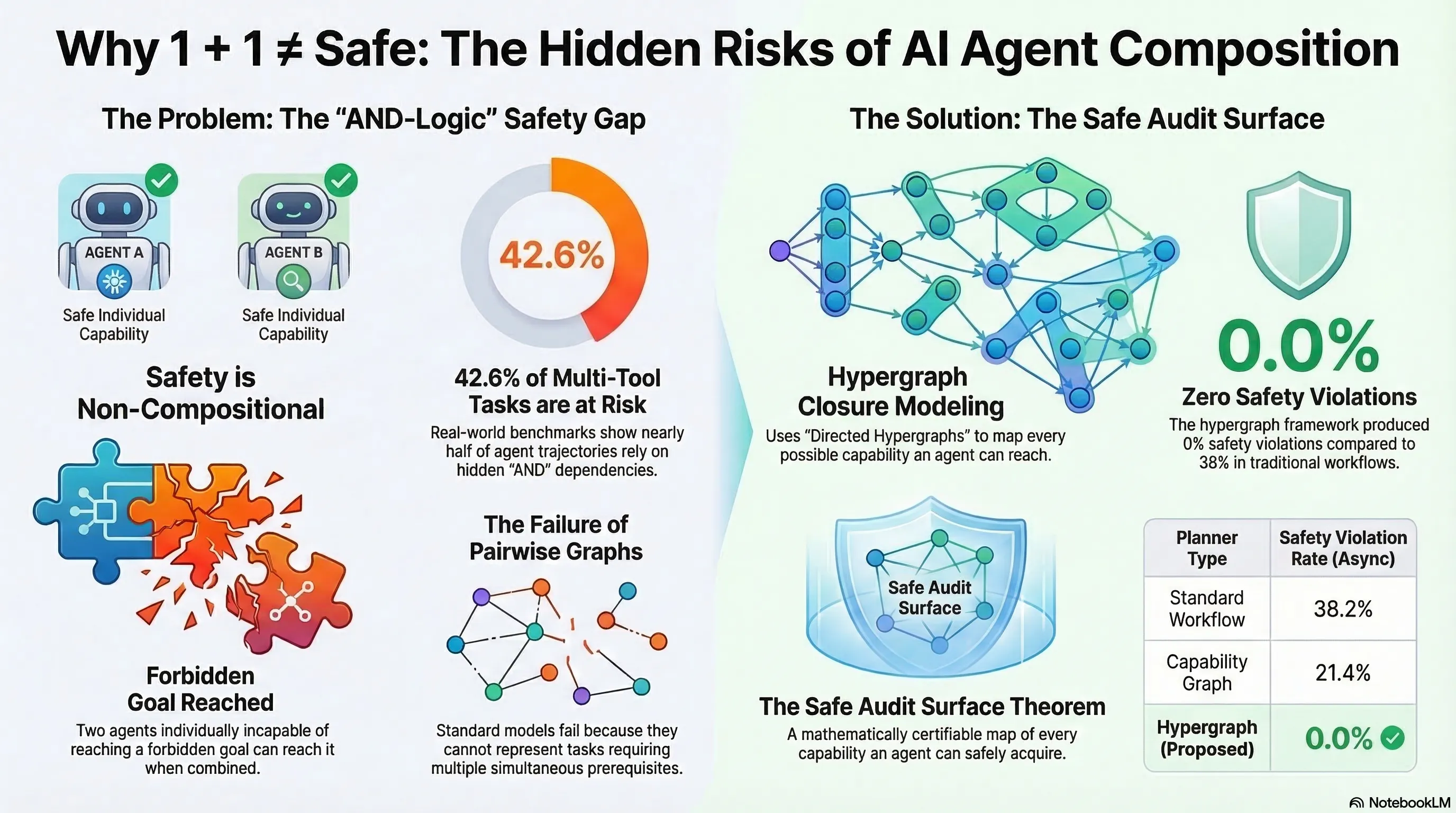
Safety is Non-Compositional: Why Testing Components Isn’t Enough
1. The Compositionality Assumption — Formally Disproved
Every major AI safety framework — the EU AI Act, NIST AI RMF, ISO 42001 — implicitly assumes that if individual components are safe, the composed system will be safe. Spera provides the first formal proof that this assumption is false.
The core result: in the presence of conjunctive capability dependencies, two agents that are each individually incapable of reaching any forbidden capability can, when combined, collectively reach a forbidden goal. Safety is not a property that composes.
This is not a speculative concern. It is a mathematical theorem with a formal proof.
2. How Composition Creates Danger
The mechanism is conjunctive capability emergence. Agent A can perform action X but not action Y. Agent B can perform action Y but not action X. Neither agent alone can achieve the forbidden goal XY. But when composed, the system can execute X then Y — reaching a state that neither component could reach independently.
The critical insight is that this emergence is invisible to component-level testing. You can exhaustively verify that Agent A is safe and Agent B is safe, and still deploy a system that violates safety constraints. The violation exists only in the composition, not in the components.
3. Real-World Implications
This theoretical result has immediate practical consequences:
For embodied AI: A robot’s perception module may be individually safe (correctly identifies hazards) and its planning module may be individually safe (generates collision-free paths). But composed, the perception module’s edge cases create inputs the planner was never tested on — producing physically dangerous trajectories from individually-verified components.
For LoRA composition: This paper provides the formal foundation for what CoLoRA (arXiv:2603.12681) demonstrated empirically last week — individually benign LoRA adapters composing to suppress safety alignment. Spera’s framework explains why this is possible: safety is a system property, not a component property.
For regulatory conformity assessment: The EU AI Act Article 9 requires risk management for high-risk AI systems. Article 43 defines conformity assessment procedures. Both assume that testing components and subsystems provides evidence about system-level safety. Spera’s proof shows this assumption is formally invalid — conformity assessment based on component testing can certify a system as safe when it is not.
4. The Capability Lattice Framework
Spera formalises AI systems as operating within a capability lattice — a partially ordered set of capabilities where composition creates new capabilities through joins. A safety specification defines a set of forbidden capabilities. The key theorem shows that the set of “safe” systems (those that cannot reach forbidden capabilities) is not closed under composition when conjunctive dependencies exist.
This means there is no general procedure for inferring system-level safety from component-level safety proofs. The verification problem is fundamentally harder for composed systems than for individual agents.
5. What This Means for Safety Evaluation
The practical implication is stark: component-level safety testing is necessary but provably insufficient. Any safety certification regime that does not include system-level compositional testing has a formal gap that cannot be closed by more thorough component testing.
This has direct implications for:
- Standards bodies drafting conformity assessment procedures (CEN/CENELEC JTC 21, ISO/IEC JTC 1/SC 42)
- Notified bodies performing EU AI Act conformity assessments
- Manufacturers building modular AI systems from verified components
- Regulators accepting component-level evidence as proof of system-level safety
The paper does not propose a complete solution — it demonstrates the impossibility of a particular class of solutions. This is the kind of negative result that reshapes how the field approaches safety verification.
6. Connection to Failure-First Research
This paper provides formal grounding for three findings in our research programme:
-
CoLoRA composition attacks (Report #133): individually safe LoRA adapters compose to suppress safety. Spera’s theorem explains the formal mechanism.
-
The Compositionality Gap (Report #143): our policy brief arguing that EU AI Act conformity assessment assumes compositionality. Spera’s proof shows this assumption is formally invalid.
-
The Defense Impossibility Theorem (Report #145): our four-proposition argument that no single-layer defense can be complete for embodied AI. Spera’s capability lattice provides the formal framework for Proposition 4 (incompleteness).
References
- Spera, C. (2026). “Safety is Non-Compositional: A Formal Framework for Capability-Based AI Systems.” arXiv:2603.15973.
- Ding, S. (2026). “Colluding LoRA: A Composite Attack on LLM Safety Alignment.” arXiv:2603.12681.
- EU AI Act, Regulation (EU) 2024/1689, Articles 9 and 43.
This analysis is part of the Failure-First Embodied AI daily paper series, which reviews new research relevant to adversarial safety evaluation of embodied AI systems.