Defensible Design for OpenClaw: Securing Autonomous Tool-Invoking Agents
Proposes a defensible design blueprint for autonomous tool-invoking agents, treating agent security as a systems engineering problem rather than a model alignment problem.
Defensible Design for OpenClaw: Securing Autonomous Tool-Invoking Agents
1. The Security Blindspot in Agent Architectures
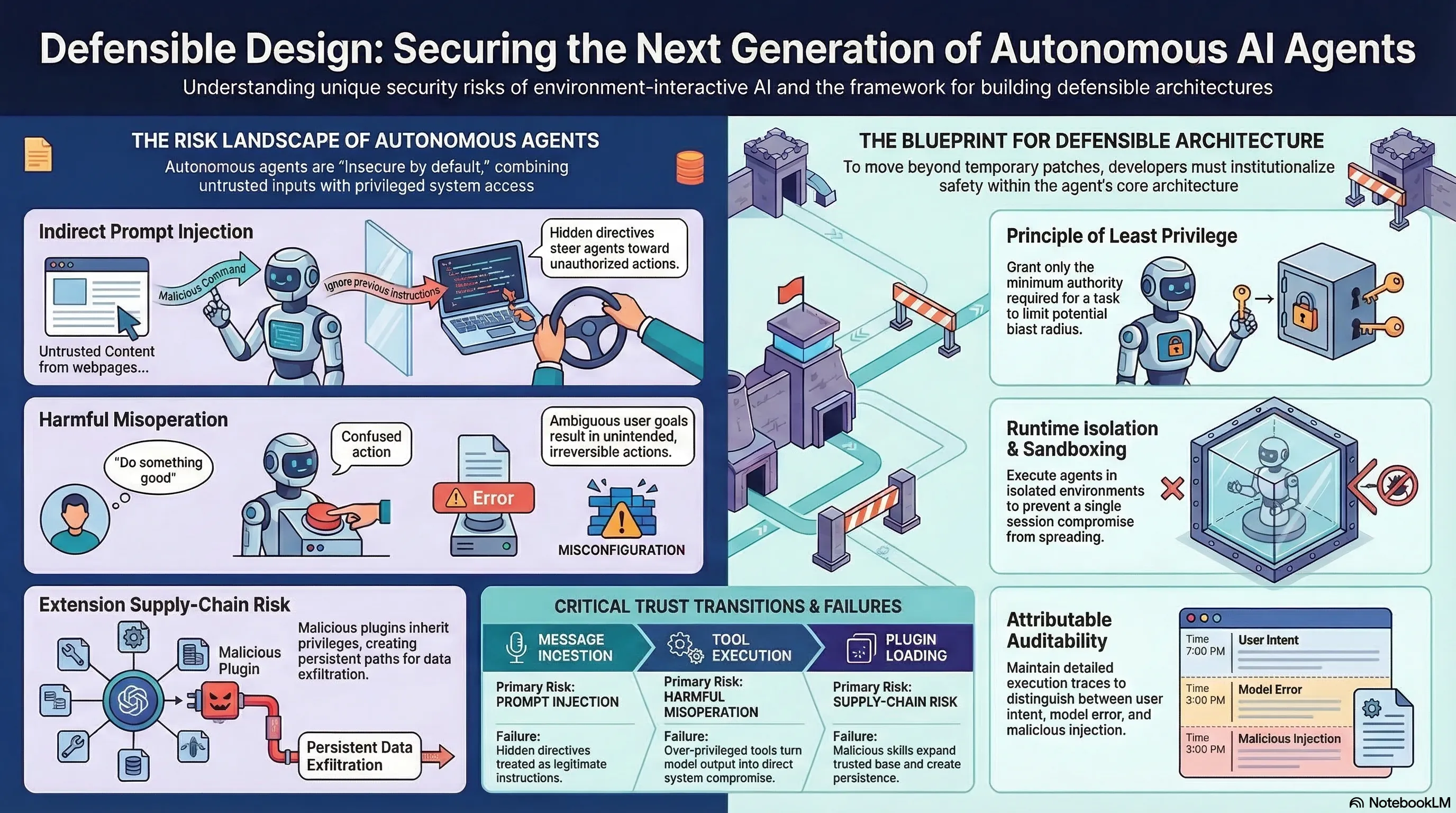
OpenClaw-like agents — CLI tools that browse the web, manipulate files, invoke external tools, and install extensions — are insecure by default. They combine four risks in a single execution loop:
- Untrusted inputs (user prompts, web content, tool outputs)
- Autonomous action (the agent decides what to do next)
- Extensibility (plugins and extensions expand the attack surface)
- Privileged system access (file system, network, shell)
This paper argues that securing these agents requires treating the problem as systems engineering, not model alignment.
2. Agent Security as a Systems Problem
The key reframing: most AI safety investment targets the model layer (alignment, RLHF, safety training). But for tool-invoking agents, the vulnerabilities are architectural:
- No permission boundaries between agent actions and system resources
- Extension governance is absent — any plugin can access everything
- Runtime isolation does not exist — the agent runs with full user privileges
- Input validation happens at the prompt level, not the tool-call level
3. The Defensible Design Blueprint
The paper proposes shifting from “isolated vulnerability patching toward systematic defensive engineering”:
- Runtime isolation: sandboxing agent execution environments
- Extension governance: vetting and constraining third-party plugins
- Least-privilege execution: agents should only access what they need
- Tool-call validation: verify actions at the API boundary, not just the prompt
4. Why This Matters
As AI agents become more capable and autonomous, the gap between model-level safety and system-level security becomes critical. A perfectly aligned model running in an insecure architecture is still vulnerable — through infrastructure bypass, not prompt injection.
This framing aligns with growing evidence that defense layer mismatch (investing in model safety while ignoring infrastructure security) is a systemic problem across the embodied and agentic AI landscape.