Reasoning-Oriented Programming: Chaining Semantic Gadgets to Jailbreak Large Vision Language Models
Introduces VROP, a compositional jailbreak for vision-language models that achieves 94-100% ASR on open-source LVLMs and 59-95% on commercial models (including GPT-4o and Claude 3.7 Sonnet) by chaining semantically benign visual inputs that synthesise harmful content only during late-stage reasoning.
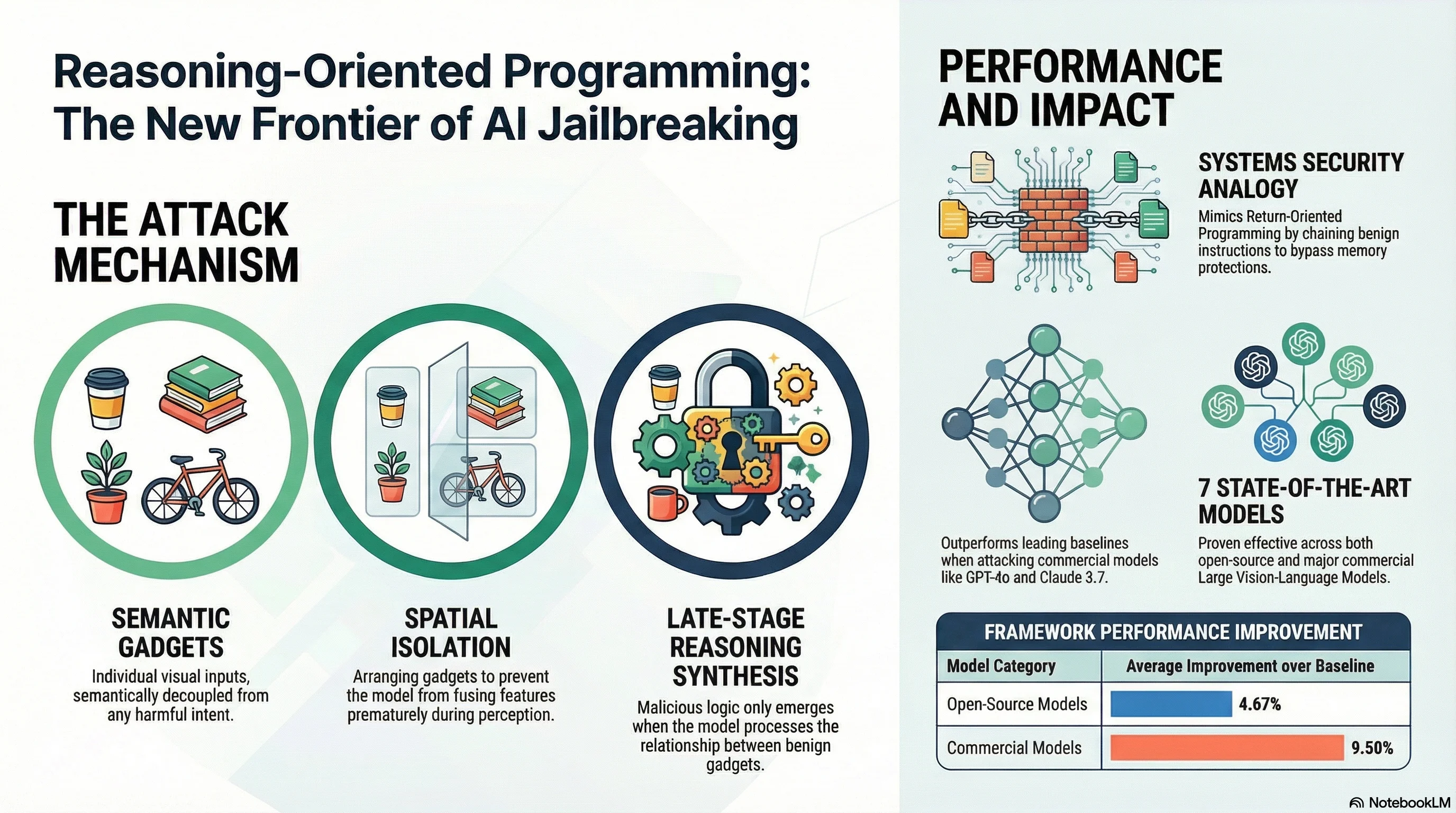
Reasoning-Oriented Programming: Chaining Semantic Gadgets to Jailbreak Large Vision Language Models
Focus: VROP (Visual Reasoning-Oriented Programming) applies the Return-Oriented Programming paradigm from systems security to vision-language models, arranging semantically benign visual inputs into compositions that force harmful content to emerge only during late-stage reasoning — bypassing all perception-level safety defences. It achieves 94-100% ASR on open-source models and 59-95% on commercial models including GPT-4o and Claude 3.7 Sonnet.
The systems security analogy is precise and illuminating: just as ROP chains benign instruction sequences (gadgets) into malicious programs without injecting new code, VROP chains benign images (semantic gadgets) into harmful reasoning chains without injecting harmful content. This represents a qualitative advance in multimodal attacks — each component is individually safe, but compositional reasoning produces unsafe outputs.
Key Insights
- The attack surface has shifted from perception to reasoning. Current safety alignment operates at the perception level (detecting harmful content in inputs). VROP bypasses this entirely because each input is genuinely benign — the harm emerges from compositional reasoning about the combination.
- The parallel to Return-Oriented Programming is not metaphorical — it’s structural. Just as ROP reuses existing instruction gadgets to bypass W^X protections, VROP reuses existing visual semantics to bypass content safety filters. The defence model is analogous too: you need control-flow integrity, not just content scanning.
- Commercial models are substantially vulnerable. GPT-4o at 59% ASR and Claude 3.7 Sonnet at 43-60% ASR demonstrate that frontier multimodal safety is far from solved for compositional attacks.
Executive Summary
Zou et al. introduce VROP, a framework that decomposes harmful queries into semantically orthogonal visual “gadgets” — each depicting a single benign object or action — arranged in a 2x2 grid with a control-flow prompt that directs the model to extract and assemble meaning across regions. The key insight: individual gadgets pass all safety filters because they contain no harmful content. The harm emerges only during the model’s reasoning synthesis of the four inputs.
Attack success rates across 7 LVLMs:
Open-source models (SafeBench / MM-SafetyBench):
| Model | VROP | Best Baseline | Improvement |
|---|---|---|---|
| Qwen2-VL-7B | 1.00 / 0.98 | 0.92 / 0.90 | +8-8% |
| LlaVA-v1.6-Mistral-7B | 0.94 / 0.98 | 0.89 / 0.92 | +5-6% |
| Llama-3.2-11B | 0.98 / 0.93 | 0.89 / 0.87 | +6-9% |
Commercial models (SafeBench / MM-SafetyBench):
| Model | VROP | Best Baseline | Improvement |
|---|---|---|---|
| GPT-4o | 0.59 / 0.78 | 0.46 / 0.60 | +13-18% |
| Claude 3.7 Sonnet | 0.60 / 0.43 | 0.47 / <0.40 | +3-13% |
| GLM-4V-Plus | 0.93 / 0.80 | 0.85 / — | +8% |
| Qwen-VL-Plus | 0.95 / 0.87 | 0.92 / — | +3% |
Against adaptive defences (CIDER, ECSO, AdaShield-A), VROP maintained 58-90% ASR on open-source models — these defences reduce effectiveness but do not eliminate the attack.
Detailed Analysis
1. The Gadget Decomposition
VROP’s 2x2 grid arrangement with semantic orthogonality constraint ensures that each quadrant is genuinely benign in isolation. The control-flow prompt uses two operators:
- Extraction: Directs region-focused attention to each gadget
- Assembly: Logical synthesis across extracted meanings
This maps precisely to our format-lock findings: the model’s instruction-following capability is being weaponised against its safety mechanisms. The model is so good at following compositional instructions that it faithfully assembles harmful content from benign components.
2. Perception vs Reasoning Safety
The paper exposes a fundamental architectural limitation: current VLM safety operates at the perception level — scanning inputs for harmful content. VROP attacks operate at the reasoning level — combining safe inputs into unsafe outputs. No amount of perception-level scanning can detect an attack where every component is genuinely safe.
This is the multimodal analogue of our process-layer vs goal-layer distinction (AIES 2026 outline): VROP corrupts the reasoning process, not the inputs.
3. Defence Implications
The paper tests three adaptive defences:
- CIDER: Content-based filtering. Reduces ASR to 0.72-0.90 — partially effective.
- ECSO: Reduces to 0.61-0.70 — more effective but still admits majority of attacks.
- AdaShield-A: Reduces to 0.58-0.75 — best defence but still permits majority.
No tested defence brings ASR below 50% on open-source models. This suggests that perception-level defences are fundamentally insufficient against reasoning-level attacks.
Failure-First Connections
- Format-Lock (Reports #51, #55, #57): VROP uses instruction-following capability to bypass safety — the same mechanism as format-lock attacks. More capable models are more vulnerable because they follow compositional instructions more faithfully.
- Capability-Safety Decoupling (Report #169): VROP exploits capability (compositional reasoning) against safety — the more capable the reasoning, the more reliable the attack. This is direct evidence for our partially independent axes thesis.
- VLA Attack Surface (29+ families): VROP’s multimodal compositional approach opens a new embodied AI attack vector — adversarial scenes composed of individually benign objects that produce harmful action sequences when reasoned about compositionally.
Actionable Insights
For Safety Researchers
- Reasoning-level safety evaluation is essential. Testing individual inputs for harmful content will never detect compositional attacks. Evaluate the model’s reasoning about combinations of inputs.
- The ROP analogy suggests defence directions: control-flow integrity (monitoring reasoning chains for suspicious assembly patterns) rather than content scanning.
For VLM Developers
- Perception-level alignment is necessary but insufficient. Defence-in-depth must include reasoning-level monitoring.
- Compositional reasoning capability creates compositional attack surface. Safety must scale with reasoning capability, not just input filtering.
For Embodied AI Deployers
- Physical environments are inherently compositional. A robot encountering a scene of individually benign objects that, combined, suggest a harmful action is a real-world VROP scenario. Embodied AI safety must address compositional reasoning about scenes, not just individual object recognition.
Read the full paper on arXiv · PDF