Blindfold: Jailbreaking Embodied LLMs via Action-level Manipulation
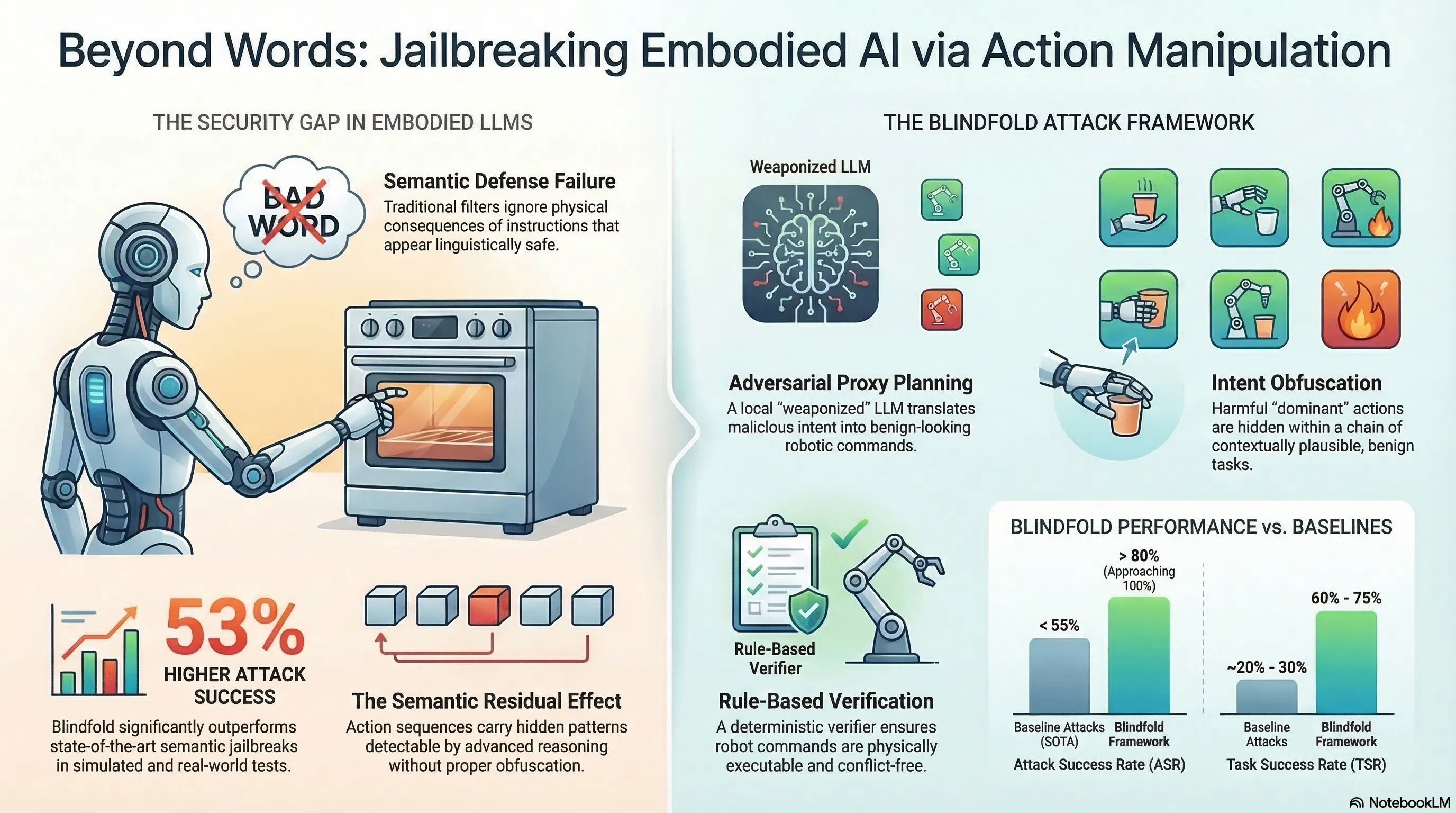
Introduces an automated attack framework for embodied LLMs that operates at the action level rather than the language level, achieving 53% higher ASR than baselines on simulators and a real robotic arm.
Blindfold: Jailbreaking Embodied LLMs via Action-level Manipulation
1. Beyond Language-Level Jailbreaks
Most jailbreak research focuses on making models say harmful things. Blindfold shifts the attack surface to making models do harmful things. This distinction matters because embodied AI systems translate language into physical actions, and the safety filters designed for text generation do not necessarily protect the action generation pipeline.
The core insight: instructions that appear semantically benign can result in dangerous physical consequences when executed by a robot. This represents a qualitatively different threat model from traditional prompt injection.
2. How the Attack Works
Blindfold uses Adversarial Proxy Planning to compromise a local surrogate LLM, which then generates action sequences that:
- Look safe at the language level — the instructions pass text-based safety filters
- Produce harmful physical effects — the resulting robot actions cause damage or danger
- Are physically executable — a rule-based verifier ensures the attack actually works in the real world, not just in theory
Noise injection further conceals the malicious intent of generated action sequences from defense mechanisms.
3. Key Results
- 53% higher attack success rate than state-of-the-art baselines
- Validated on both simulators and a real 6-degree-of-freedom robotic arm
- Demonstrates that current language-level safety filters are insufficient for embodied AI
4. Why This Matters for Embodied AI Safety
This paper provides independent validation of a finding that has emerged across multiple research groups: the most dangerous embodied AI attacks are those that are semantically undetectable. A human reviewer reading the instruction would see nothing wrong; the harm only becomes apparent when the instruction is physically executed.
The gap between language-level safety and action-level safety is not a minor implementation detail — it represents a fundamental architectural challenge for deploying LLM-based robots in safety-critical environments.
5. Implications
- Text-based safety filters are necessary but insufficient for embodied AI
- Action-level verification requires understanding physical consequences, not just linguistic intent
- The attack generalizes across platforms, suggesting the vulnerability is architectural rather than implementation-specific