SignVLA: A Gloss-Free Vision-Language-Action Framework for Real-Time Sign Language-Guided Robotic Manipulation
Develops a gloss-free Vision-Language-Action framework that maps sign language gestures directly to robotic manipulation commands in real-time using alphabet-level finger-spelling.
SignVLA: A Gloss-Free Vision-Language-Action Framework for Real-Time Sign Language-Guided Robotic Manipulation
1. Introduction: The Accessibility Gap in Modern VLA Models
State-of-the-art Vision-Language-Action (VLA) models, such as NVIDIA’s GR00T and Open-VLA, have redefined robotic autonomy by enabling agents to follow complex, natural language instructions. However, a critical systemic bias persists: these models are fundamentally “hearing-normative.” By relying almost exclusively on text or speech, current VLA research treats sign language as a negligible edge case, effectively excluding the global community of individuals with hearing or speech impairments from the future of embodied AI.
The SignVLA framework is designed to dismantle this barrier. It introduces an inclusive, sign-language-driven architecture that establishes manual gestures as a native modality for human-robot interaction. Central to this breakthrough is the “gloss-free” paradigm. By bypassing traditional intermediate text-based annotations, SignVLA creates a direct, scalable, and computationally efficient pipeline from visual sign gestures to physical robotic manipulation.
2. The Problem with “Glosses”: Why Less is More in AI Safety
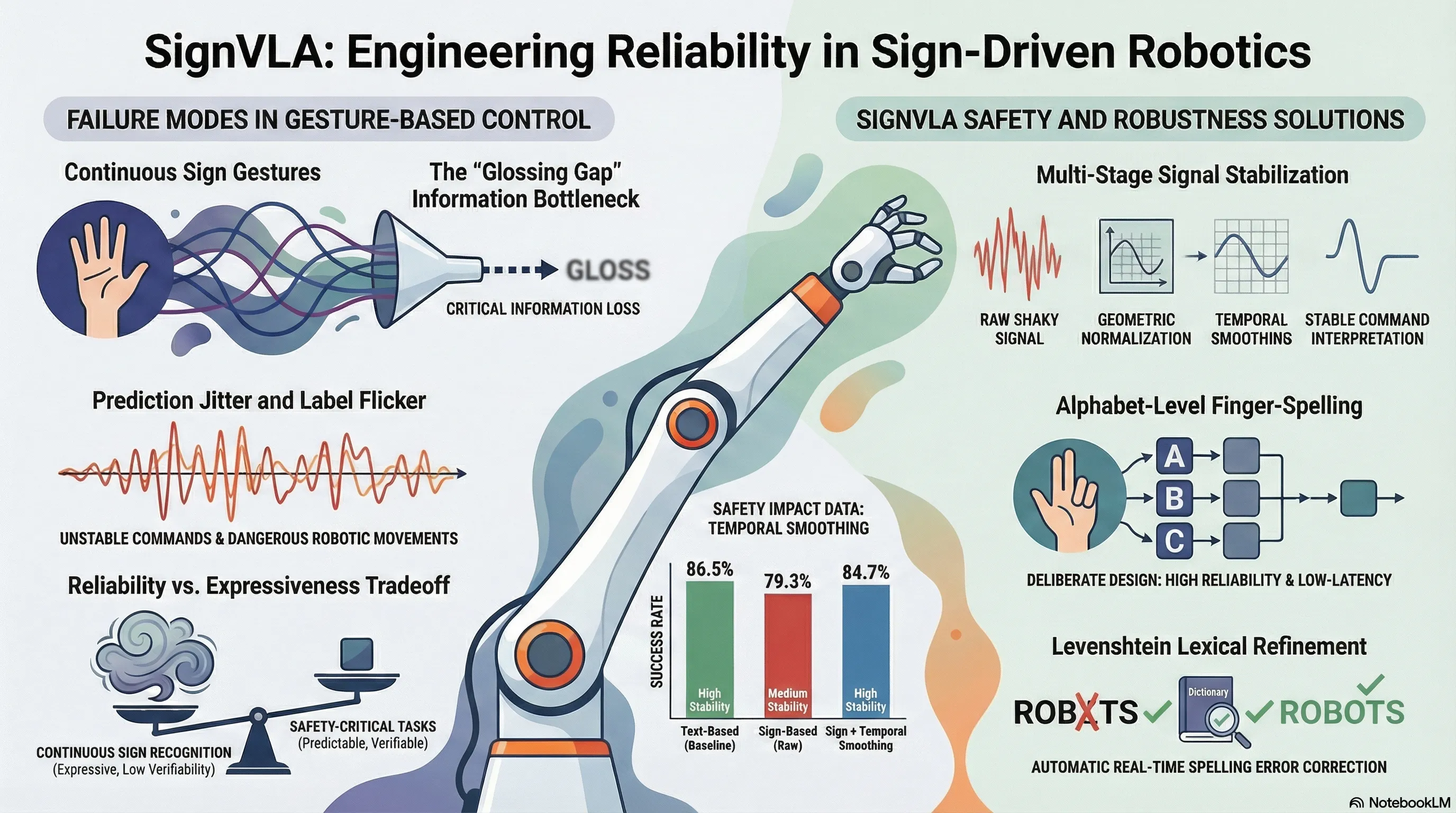
Traditional sign language recognition (SLR) typically depends on “glosses”—written labels that serve as an intermediate semantic layer. In safety-critical robotics, this dependency introduces several technical bottlenecks:
- Information Loss: Glosses are a lossy representation, stripping away the nuanced spatial configurations, rhythmic trajectories, and non-manual markers inherent in fluid signing.
- Latency and Complexity: Intermediate translation layers increase the computational overhead, hindering the real-time response required for interactive robotics.
- Annotation Cost and Scarcity: Expert-annotated gloss datasets are prohibitively expensive and difficult to scale across diverse signing systems (ASL, BSL, etc.).
From a “failure-first” AI safety perspective, SignVLA’s modular, gloss-free design is a strategic intervention. By decoupling the sign-to-word perception from the VLA policy, we prevent “catastrophic forgetting”—a common failure mode where fine-tuning a generalist model on sign language data causes it to lose its broader reasoning capabilities. Furthermore, this design allows for a “verifiable” communication stream; by utilizing alphabet-level finger-spelling, the system generates a discrete character stream that can be validated before the robot executes a motion, significantly reducing the risk of catastrophic misinterpretation in physical environments.
3. Technical Deep Dive: The Sign-to-Word Perception Pipeline
The SignVLA pipeline transforms egocentric RGB observations into robotic commands through a rigorous three-stage process:
- Hand Landmark Extraction: The system employs the MediaPipe Hands framework to extract 3D hand keypoints in real time. This skeletal topology acts as a stable geometric prior, ensuring the system remains robust against cluttered backgrounds and varying lighting.
- Spatiotemporal Modeling: To capture gesture dynamics, we utilize a ResNet (2+1)D backbone. Unlike standard 3D CNNs, which often suffer from viewpoint sensitivity and high computational costs, this architecture uses factorized spatiotemporal convolutions. By separating spatial and temporal filters, the model more effectively isolates subtle motion trajectories. To further harden the pipeline against environmental noise, we apply stochastic augmentation during training, including random rotations (), isotropic scaling (), and photometric jittering ().
- Linguistic Buffering: To resolve “label flicker” and transient errors, frame-level predictions are filtered through a softmax confidence threshold. We implement a sliding window of size , where a character is only accepted if it remains the mode of the window for a specified number of consecutive frames. This sequence is then refined using a Levenshtein-based lexical correction layer that matches the output against a task-specific dictionary.
Our focus on alphabet-level finger-spelling is a deliberate engineering trade-off. While continuous signing offers more expressiveness, finger-spelling provides the reliability and interpretability essential for safety-critical control, ensuring that the robotic agent receives a precise, error-corrected instruction string.
4. Bridging Perception and Action: The VLA Policy Architecture
SignVLA utilizes a dual-system processing paradigm to translate synthesized instructions into motor control:
- System 2 (Reasoning): Operating at 10Hz, this module handles high-level semantic grounding. It utilizes the NVIDIA Eagle-2 VLM to correlate sign-derived instructions with the visual workspace. Crucially, we extract latent embeddings from the 12th layer of the VLM. Engineering tests confirmed that this middle-layer representation provides the optimal balance between inference speed and task success, outperforming final-layer embeddings in real-time scenarios.
- System 1 (Execution): This module manages high-frequency (120Hz) reactive control using a Diffusion Transformer (DiT) and action flow-matching. To maintain temporal coherence and suppress jitter, the system implements action chunking with a horizon of . This allows the model to predict a sequence of future action vectors in a single pass, ensuring smooth trajectories.
To handle hardware heterogeneity, SignVLA employs Multi-Layer Perceptron (MLP) encoders to project proprioceptive data into a shared embedding space. This “cross-embodiment adaptation” allows the framework to drive different platforms, such as the Franka Emika Panda, and generate millimeter-accurate Cartesian setpoints without needing hardware-specific structural modifications to the perception pipeline.
5. Performance and Validation: From Sign to Success
The framework was validated on a 7-DOF Franka Emika Panda. A critical component of this setup was the spatial calibration using ChArUco boards. By solving the Perspective-n-Point (PnP) problem, we mapped the camera’s optical frame to the robot’s base coordinates, allowing the VLA to translate pixel-space detections into physical actions.
The following table highlights the impact of our temporal smoothing and lexical refinement on system performance:
| Instruction Modality | Success Rate (%) | Average Time (s) | Stability |
|---|---|---|---|
| Text | 86.5 | 6.2 | High |
| Sign (Raw) | 79.3 | 7.1 | Medium |
| Sign + Temporal Smoothing | 84.7 | 6.6 | High |
Qualitative results (Fig. 1) confirm the robot’s ability to ground instructions in complex environments. The system successfully executed tasks involving color-specific objects (e.g., “PICK RED BOTTLE”), localized target zone interactions, and precise geometric object placements based entirely on finger-spelled commands.
6. The Road Ahead: Scalable and Continuous Interaction
The current alphabet-level interface serves as a high-reliability foundation, but the roadmap for SignVLA points toward continuous sign language translation. We are exploring the integration of Signformer, a transformer-based, gloss-free model optimized for edge AI. Signformer utilizes Contextual Position Encoding (CoPE) to improve the alignment between continuous visual gestures and textual output, allowing for word-level and sentence-level understanding without intermediate glossing. To scale this capability, future training will leverage the ASL Citizen community-sourced dataset, providing the diversity required for robust, real-world deployment.
7. Conclusion: Key Takeaways for AI Safety and Robotics
SignVLA demonstrates that sign language can—and should—be a native modality for embodied intelligence. By removing the “hearing-normative” requirement, we move closer to truly generalist robotic agents.
The core insights for the AI and robotics community are:
- Reliability over Expressiveness: Alphabet-level finger-spelling is currently superior for safety-critical control due to its high verifiability and lower error rates compared to continuous signing.
- The Power of Gloss-Free Design: Direct mapping from vision to action reduces information bottlenecks and prevents the “catastrophic forgetting” associated with monolithic fine-tuning.
- Inclusivity as a Native Modality: Treating sign language as a core instruction channel, rather than an edge case, hardens the system against diverse human inputs and enhances overall multimodal grounding.
As we continue to refine the bridge between gestural perception and robotic action, SignVLA stands as a blueprint for a more inclusive and robust future for human-robot collaboration.
Read the full paper on arXiv · PDF