ActionReasoning: Robot Action Reasoning in 3D Space with LLM for Robotic Brick Stacking
Proposes ActionReasoning, an LLM-driven multi-agent framework that performs explicit physics-aware action reasoning to generate manipulation plans for robotic brick stacking without relying on custom...
ActionReasoning: Robot Action Reasoning in 3D Space with LLM for Robotic Brick Stacking
Beyond the Scaling Law: How ActionReasoning Grounded LLMs in Physics for Robotic Mastery
1. Introduction: The Disconnect Between Language and Limbs
In the current landscape of embodied intelligence, the “scaling law”—the premise that increasing data and model parameters leads to emergent capabilities—has hit a significant wall in robotics. While Large Language Models (LLMs) demonstrate remarkable generalization in text, Vision-Language-Action (VLA) models frequently fail to replicate this robustness in physical environments. This failure stems from a fundamental dimensional mismatch: the continuous action space of the physical world dwarfs the discrete linguistic token space of LLMs.
Current VLA performance typically degrades when faced with long-horizon reasoning or novel embodiments, suggesting that sheer scaling is insufficient for universal control. ActionReasoning addresses this by shifting away from pure data-driven next-token prediction toward a Markovian closed loop. In this framework, the environment transition is governed by explicit 3D action reasoning, where the model emits target waypoints rather than raw motor commands. By grounding high-level reasoning in physical priors, ActionReasoning bridges the gap between linguistic “understanding” and physical “doing.”
2. The Representation Bottleneck: Why More Data Isn’t Enough
The fundamental bottleneck in robotics is the translation of discrete semantic intent into continuous physical execution. Traditional models struggle because they lack an inherent understanding of space and physical constraints. ActionReasoning resolves this by treating action selection as a physics-guided inverse problem: given an environment state and a goal , the system infers an action that satisfies safety and feasibility constraints.
Traditional VLA Approaches These models rely on end-to-end learning from massive datasets, treating robot control as a statistical prediction problem. This approach introduces uncertainty at every stage—from perception to action—and lacks the transparency required to mitigate catastrophic failures in unstructured environments.
The ActionReasoning Philosophy ActionReasoning leverages the physical commonsense already internalized in LLMs. It utilizes a physical deduction operator that encodes collision avoidance, reachability, and contact stability. Instead of blindly predicting the next action, the LLM proposes candidate waypoints that are pruned and refined by the operator to ensure physical consistency.
3. Defining the “World Model” for Robots
To enable precise reasoning, ActionReasoning utilizes a functional World Model. This is not merely a generative visualization, but a computable abstraction defined as:
World Model = (A) universal physical knowledge + (B) precise environment representations
Under this framework, (A) consists of the physical priors and tool-use knowledge embedded in the LLM, while (B) is a serialized representation of the environment. Unlike 2D keypoint-based models, ActionReasoning serializes 3D scene geometry into structured JSON/text, making it queryable for the LLM. This serialized state includes:
- Geometric Attributes: Precise 3D poses, sizes, and masses of all objects.
- State Dynamics: Surface normals, occupancy/free space, and tolerance parameters ().
- Task Context: Building progress, existing obstacles, and robot end-effector states (e.g., finger depth, gripper width).
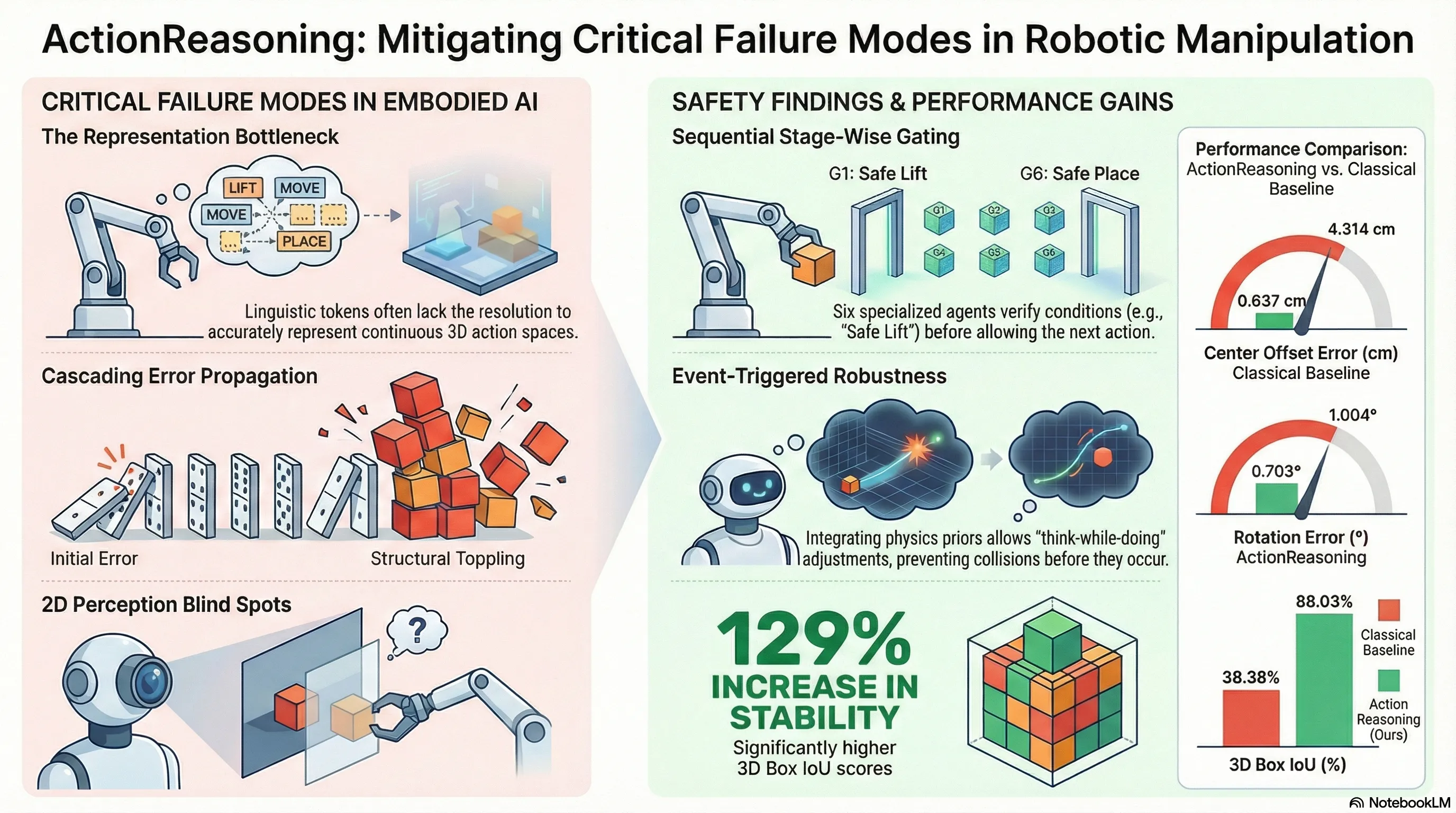
4. The Multi-Agent Orchestrator: Six Specialized Pillars of Planning
ActionReasoning manages complex manipulation through a sequential pipeline of six specialized agents (Ag1–Ag6). This architecture enables “think-while-doing” behavior through multiple LLM calls per waypoint, ensuring that each phase of the task is verified before execution.
The behavior of each agent is governed by a Structured Prompting architecture defined by six components:
- Environment State (): Current world model data.
- Memory (): Task progress, completed steps, and retry counters.
- Role (): Specific responsibilities (e.g., “Grasp Closure Expert”).
- Knowledge Base (): Callable tools for collision checks and stability estimation.
- Thinking Chain (): A stepwise reasoning scaffold.
- Output Schema (): Structured JSON for waypoints and tool calls.
The agents execute in sequence, linked by a gating rule (). An agent is only triggered if the preceding agent returns , indicating that physical verification checks (e.g., force thresholds or collision-free paths) have been met.
The Six-Agent Pipeline:
- Pre-grasp positioning: Aligns the end-effector above the target and matches the grasp axis.
- Descent & opening: Manages approach poses and ensures the gripper width .
- Grasp closure: Verifies stable contact via normal-force thresholds ().
- Safe lift: Evaluates slip risk; if , the system triggers a re-grasp.
- Brick placement: Moves to the target slot, descends until contact, and checks alignment.
- Grasp release: Ensures stable landing and retracts the arm to a collision-free ready pose ().
5. Benchmarking Success: ActionReasoning vs. Classical Controllers
ActionReasoning was benchmarked against classical scripted controllers in Pyramid and Grid stacking tasks. The results demonstrate that explicit reasoning is essential for high-precision manipulation.
Performance Comparison: Pyramid and Grid Stacking
| Metric | Classical Baseline | ActionReasoning (Ours) |
|---|---|---|
| Rotation Error (Lower is better) | 1.004° | 0.703° |
| Center Offset (Lower is better) | 4.314 cm | 0.637 cm |
| 3D Box IoU (Higher is better) | 38.38% | 88.03% |
Research Analysis of the Data:
- 85.2% Reduction in Center Offset: This is the most critical metric, as it indicates that the LLM successfully overcame the cumulative lateral drift and premature release issues that plague classical controllers.
- 30.0% Reduction in Rotation Error: Demonstrates the efficacy of reasoning in maintaining precise orientation during long-horizon stacking.
- 129% Increase in 3D IoU Overlap: Confirms that the resulting structures are geometrically consistent with the target specifications, whereas baseline structures were often unstable or misaligned.
6. Why This Matters: AI Safety and Failure Mitigation
Grounding LLMs in physics-aware reasoning is a critical safety intervention. In manipulation, “catastrophic failures” often result from error propagation—small misalignments in early stages leading to the eventual toppling of the structure.
This risk was highlighted in the Single-Agent ablation study. When the specialized roles and stage-wise gating () were removed in favor of a single LLM call, the model failed to complete the tasks. While the Single-Agent model could place the first few bricks, it exhibited significantly higher placement errors and consistently toppled the structure on the final two bricks. By enforcing a “think-while-doing” loop with inter-stage verification, ActionReasoning trades off the simplicity of end-to-end learning for functional robustness and reduced risk.
7. Conclusion: The Future of Autonomous Construction
ActionReasoning demonstrates that LLMs can master 3D manipulation when they are provided with structured environment states and allowed to reason through physical priors. This approach shifts the engineering burden from writing thousands of lines of task-specific, low-level code to high-level tool invocation and structured prompting.
Looking Ahead The framework is designed for expansion into unstructured construction environments. Future research will focus on:
- Diverse Material Handling: Adapting to the physical properties of stone, wood, and block.
- Complex Assembly: Integrating drilling, fastening, and compliant insertion.
- On-Site Tasks: Automating mortar deposition, leveling, and assembly within cluttered scenes containing dynamic obstacles.
8. Key Takeaways Summary
- Solving the Bottleneck: ActionReasoning bridges the gap between discrete language and continuous physical action by treating manipulation as a physics-guided inverse problem in space.
- Structured Gating: The use of a six-agent sequential pipeline with explicit gating rules () enables inter-stage verification, preventing the error propagation that leads to structural collapse.
- Precision and Robustness: The framework achieved an 85.2% reduction in center offset and a 129% increase in 3D IoU compared to classical controllers by utilizing event-triggered release and contact detection.
- Safety-First Design: Explicit reasoning reduces catastrophic failures; ablation studies prove that without multi-agent gating, models fail to complete complex structures like walls due to structure toppling.
Read the full paper on arXiv · PDF