HALO: A Unified Vision-Language-Action Model for Embodied Multimodal Chain-of-Thought Reasoning
HALO introduces a unified Vision-Language-Action model that performs embodied multimodal chain-of-thought reasoning by sequentially predicting textual task reasoning, visual subgoals, and actions through a Mixture-of-Transformers architecture, evaluated on robotic manipulation benchmarks.
HALO: A Unified Vision-Language-Action Model for Embodied Multimodal Chain-of-Thought Reasoning
Beyond the Robotic Reflex: The Shift to Deliberative VLA
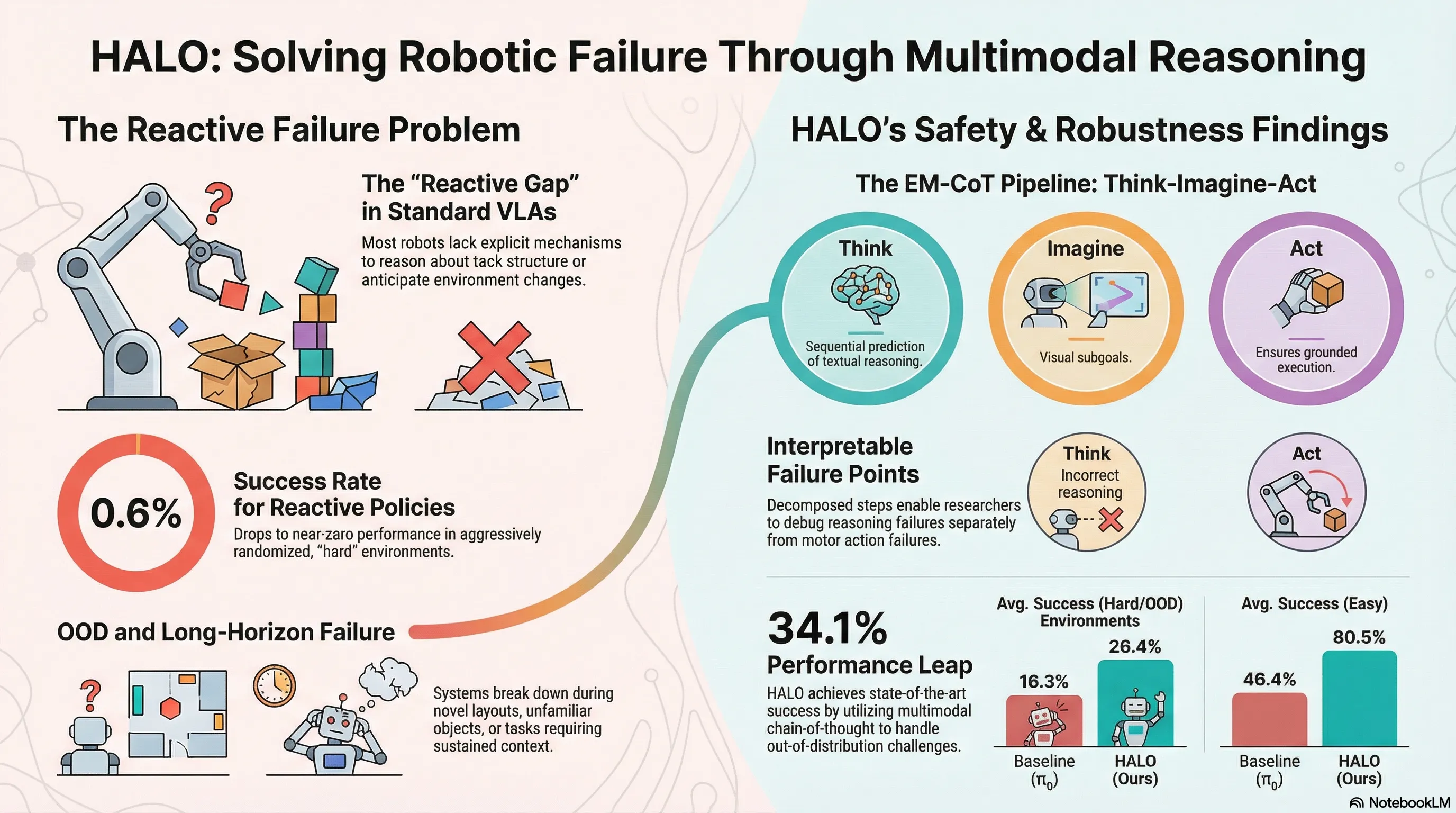
Current Vision-Language-Action (VLA) models predominantly function as “reactive policies,” mapping high-dimensional perceptual inputs directly to motor commands. This reflexive architecture lacks explicit mechanisms for reasoning about task structure or predicting environmental evolution, leading to systemic failures in long-horizon tasks and out-of-distribution (OOD) scenarios. When a robot encounters novel layouts or contact-rich interactions, simple pattern matching is insufficient.
HALO (Embodied Multimodal Chain-of-Thought) represents a breakthrough in robotic cognition by decoupling reasoning, imagination, and execution. By mimicking the human cognitive pathway of “Thinking-Imagination-Execution,” HALO moves beyond the black-box reflex. The model generates a textual reasoning trace and “imagines” a visual subgoal before committing to motor commands. This deliberative framework ensures every action is strategically planned and visually grounded, significantly increasing robustness in complex environments.
The Three Pillars of Embodied Multimodal Chain-of-Thought (EM-CoT)
The EM-CoT framework transforms robotic decision-making from a single-step mapping into a sequential generative process:
- Textual Task Reasoning: The model generates a semantic plan, decomposing high-level instructions into discrete subtasks. This includes a first-person reasoning trace explaining the internal logic behind the current phase of the operation.
- Visual Subgoal Prediction: After semantic planning, the model predicts a visual subgoal—a mental “imagination” of the world state once the current subtask is completed. This provides fine-grained visual guidance for the subsequent motion.
- Action Prediction: The final motor commands (action chunks) are generated as a result of the preceding reasoning and foresight. By conditioning execution on textual and visual intermediate steps, the model ensures the robot’s movement is aligned with the high-level strategy.
Architecture: The Mixture-of-Transformers (MoT) Approach
HALO utilizes a Mixture-of-Transformers (MoT) architecture to prevent capability conflicts between heterogeneous tasks. Initialized from the Qwen2.5-1.5B backbone, the model scales to approximately 4.5B parameters distributed across three specialized experts.
| Expert | Responsibility | Generative Workflow |
|---|---|---|
| Multimodal Understanding | Textual reasoning and task planning | Autoregressive (Next-token) |
| Visual Generation | Visual foresight and subgoal images | Diffusion-based (Flow-matching) |
| Action Prediction | Continuous motor control chunks | Diffusion-based (Flow-matching) |
Hardware-of-the-Mind & Masking Strategy
To manage the information flow, HALO employs a Shared Self-Attention mechanism. The modality switching is controlled via specialized tokens: ⟨think_start⟩, ⟨vision_start⟩, and ⟨action_start⟩.
The model uses a sophisticated masking strategy to maintain integrity: a causal mask enforces autoregressive text generation, while visual tokens use bidirectional attention within a frame. To prevent “information leakage,” noise tokens used in diffusion are masked from attending to ground-truth targets, and non-noise tokens are prevented from attending to noise. For encoding, HALO utilizes SigLIP2-so400m/14 (enhanced with NaViT for native aspect ratios) for semantic understanding and the FLUX VAE for high-fidelity visual generation.
Scaling Intelligence: The Automated EM-CoT Pipeline
To solve the data scarcity of “robotic thinking,” the researchers developed a three-phase synthesis pipeline to augment raw trajectories with reasoning data:
- Primitive Extraction: Rule-based matching translates continuous actions into high-level motion primitives (e.g., “grasp,” “move,” “release”) based on proprioception thresholds.
- VLM Annotation: A large-scale VLM (Qwen3-VL) acts as a technical annotator using a three-stage prompting strategy:
- Task Narrative Generation: Creating a coherent temporal paragraph of the goal.
- Subtask Sequence Extraction: Decomposing the narrative into goal-oriented subtasks.
- Subtask Alignment/Reasoning: Generating first-person decision-making logic (under 50 words) for every segment.
- Visual Goal Selection: The terminal frame of each subtask is designated as the sparse visual subgoal, providing the necessary foresight supervision.
A Two-Stage Training Recipe for Deliberative AI
HALO’s training transitions the model from a general-purpose multimodal agent to a specialized roboticist:
Stage 1: Versatile Pre-training
The model is trained on heterogeneous datasets across Visual Question Answering (VQA), Visual Generation (SSv2/OXE), and Action Prediction. To prevent any single modality from dominating gradients, the researchers utilize a precise loss balancing formula:
This weights the manipulation-intensive tasks (L1 and MSE) more heavily than general multimodal understanding (CE).
Stage 2: EM-CoT Fine-tuning
The model is fine-tuned on the synthesized EM-CoT dataset to orchestrate the “thought-foresight-action” chain. To mitigate “catastrophic forgetting” of general world knowledge, VQA data is co-trained alongside the reasoning tasks.
Performance Highlights: Simulation and Real-World Results
HALO was rigorously tested on the RoboTwin 2.0 benchmark (50 tasks) and real-world ALOHA platforms.
- Simulation Success: HALO achieved an 80.5% success rate in “Easy” settings, surpassing the baseline by 34.1%.
- Out-of-Distribution Robustness: In “Hard” (domain-randomized) settings, HALO maintained a 26.4% success rate. This is a massive improvement over traditional reactive policies like Diffusion Policy, which collapsed to a 0.6% success rate under the same conditions.
- Real-World Precision: On a Cobot Mobile ALOHA platform, HALO achieved high success rates on complex tasks: 90% on “Sweep Buttons” (tool-use) and 94% on “Bimanual Cup Nesting.”
- Generalization: The model remained resilient against aggressive visual distractions (e.g., Coke bottles), lighting variations, background color shifts, and novel objects (replacing a broom with a sponge).
Conclusion: Why Interpretability is a Safety Feature
Decoupling reasoning from execution is a foundational safety requirement for embodied AI. Because HALO is built on the Mixture-of-Transformers (MoT) architecture with explicit intermediate steps, researchers can perform ablation-style debugging.
By inspecting the textual reasoning and the “imagined” subgoal, a developer can determine if a failure was a result of a conceptual misunderstanding (reasoning failure), a failure of foresight (visual hallucination of the goal), or a motor error (execution failure). This transparency transforms the robotic “black box” into a debuggable system, paving the way for reliable, human-like AI agents.
Key Takeaways
- Deliberation > Reaction: Explicit multimodal reasoning (26.4% success) is vastly more robust than reactive pattern matching (0.6% success) in randomized environments.
- Specialized Experts: The MoT architecture with Qwen2.5-1.5B initialization prevents capability conflicts between vision, text, and action experts.
- Synthetic Reasoning Data: Scaling embodied AI requires automated pipelines that bridge low-level actions with high-level semantic narratives and first-person reasoning.
Read the full paper on arXiv · PDF