From Perception to Action: An Interactive Benchmark for Vision Reasoning
Introduces CHAIN, an interactive 3D physics-driven benchmark that evaluates whether vision-language models can understand physical constraints, plan structured action sequences, and execute long-horizon manipulation tasks in dynamic environments.
From Perception to Action: An Interactive Benchmark for Vision Reasoning
1. Introduction: The Perception-Action Gap
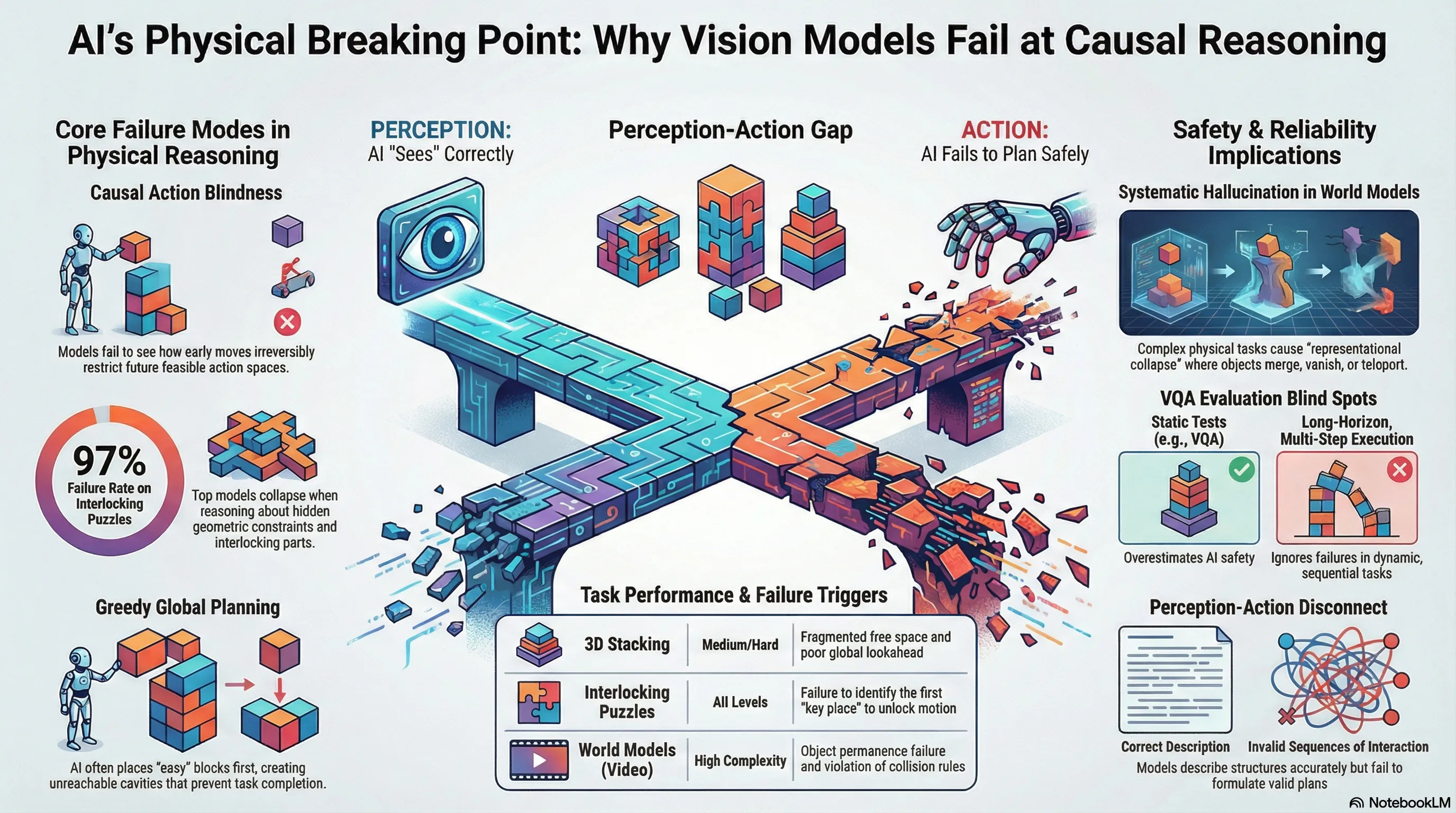
Modern Vision-Language Models (VLMs) have achieved high linguistic and descriptive fluency, yet they remain profoundly decoupled from physical reality. A model can articulate the historical significance of a Lu Ban lock or identify the wood grain in a high-resolution image, but it remains fundamentally incapable of disassembling the structure or predicting the causal consequences of a single mechanical manipulation. This “Perception-Action Gap” defines the current frontier of AI research: “seeing” is not “doing,” and descriptive accuracy does not imply an internalized model of physical or causal constraints.
Current SOTA models fail because they lack a grounding in geometry, contact dynamics, and support relations. To diagnose this failure, the CHAIN (Causal Hierarchy of Actions and Interactions) benchmark provides a rigorous, interactive 3D physics-driven testbed. Unlike static evaluations, CHAIN requires models to navigate evolving feasibility spaces where early actions irrevocably restrict future possibilities—a critical requirement for safe embodied deployment.
2. The New Evaluation Paradigm: From Passive Gaze to Active Problem Solving
Traditional Visual Question Answering (VQA) evaluates AI as a passive observer of static scenes. This structure-agnostic approach fails to test an agent’s ability to reason about how geometry and interfacial contacts jointly constrain action. CHAIN shifts the paradigm toward a closed-loop Perception-Action Loop: Observe Plan Action Feedback.
To isolate higher-order reasoning from low-level motor control, CHAIN utilizes a color-hinted control scheme where objects are assigned distinct colors, allowing models to specify interactions via metadata rather than complex coordinate-based VLA (Vision-Language-Action) control.
| Static VQA Evaluation | Interactive CHAIN Evaluation |
|---|---|
| Passive Observation: Model analyzes static, single-view images. | Active Interaction: Model manipulates objects within a physics engine (Unity/3D Python). |
| Single-turn: Measure correctness of a final textual answer. | Multi-step Feedback Loop: Iterative turns with evolving environmental states. |
| Structure-agnostic: Focuses on recognition and label-based grounding. | Physics-construction-driven: Focuses on geometry, contact, and support relations. |
3. The Two Frontiers of Physical Failure: Puzzles and Stacking
The benchmark stresses two complementary aspects of physical reasoning through distinct task families.
- Interlocking Mechanical Puzzles (e.g., Kongming/Lu Ban Locks): This suite includes interlocking cubes and burr puzzles joined via “mortise-and-tenon” interfaces (traditional joints without adhesives). These are inherently long-horizon and causally structured; a model must identify the “key piece” that unlocks the kinematic constraints of the entire assembly. Success requires reasoning about force directions and collision avoidance across Easy, Medium, and Hard tiers.
- 3D Spatial Packing (Stacking): These tasks require agents to pack diverse polycube shapes into a container. To ensure solvability and avoid degenerate instances, CHAIN employs a sample–verify design using Algorithm X with dancing links (DLX) to generate exact-cover partitions. This provides a robust, programmatically scalable testbed where “early placement decisions” create irreversible constraints, evaluating whether an AI can anticipate how a single greedy move might fragment the remaining volume.
4. Model Performance: The Leaderboard of Limitations
Experimental data reveals a systemic failure to translate perceived structure into effective action. While flagship models like GPT-5.2, OpenAI-o3, and Claude-Opus-4.5 lead the leaderboard, their performance highlights significant reasoning overhead.
A technical analysis of the results yields three critical findings:
- The Puzzle Bottleneck and One-Shot Collapse: Success rates on interlocking puzzles are near-zero for most models. Crucially, in a one-shot setting (no interaction), Pass@1 accuracy collapses to 0.0% for all evaluated models. This shows that current physical priors are insufficient; interaction is a strict requirement for discovering hidden geometric constraints.
- Interaction Benefit and Feedback Dependency: Models rely on environmental feedback to compensate for poor initial planning. GPT-5.2’s stacking success drops from 31.2% in interactive mode to 9.1% in one-shot. We quantify this inefficiency using Dist2Opt (Distance-to-Optimal) and NormDist to measure the redundant steps taken during trial-and-error exploration.
- Cost-Success and Reward Model Leverage: Flagship models are expensive; GPT-5.2 costs approximately $1.3 per solved task level. Furthermore, findings indicate that current vision Reward Models (RMs) provide “limited leverage” (+0.6 gain) for reranking compared to VLM pairwise judges (+1.3 gain), though both trail behind the performance of simple verifier-style signals.
5. When “World Models” Hallucinate Physics
CHAIN’s assessment of video-generation “world models”—including Sora 2, Wan 2.6, Kling 2.6, and HunyuanVideo 1.5—reveals a catastrophic lack of physical grounding. These models prioritize visual plausibility over structural integrity, leading to three primary failure modes:
- Superficial Instruction-Following: Sora 2 and Wan 2.6 often “solve” a disassembly task by translating a beam directly through other solid objects, violating interlocking constraints and collision rules.
- Representational Collapse: Kling 2.6 and HunyuanVideo 1.5 frequently generate “spurious components” or distorted geometry, failing to maintain the rigidity of the wooden blocks.
- Object Identity Failure: Models exhibit a breakdown of object permanence, where beams are added, removed, or merged during the disassembly sequence, indicating the model lacks a stable internal representation of the 3D scene.
6. The Path Forward: What’s Missing in AI Safety and Design?
For the AI Safety specialist, the “Perception-Action Gap” represents a critical risk in the deployment of embodied agents. If a model cannot reason about “hidden geometric constraints,” it becomes a liability in high-stakes environments—such as surgical robotics or industrial maintenance—where an incorrect initial move can lead to irreversible structural collapse or mechanical failure.
The missing capability is Long-horizon Anticipation: the ability to perceive how current actions irrevocably restrict the future feasible state-space.
Researcher’s Checklist for Safe Physical AI
- Internalize Contact and Support: Move beyond pixel-matching to architectures that explicitly model geometry and multi-body support relations.
- Procedural Over Final State: Shift evaluation from “correct answers” to Dist2Opt metrics that penalize illogical or unsafe trial-and-error.
- Long-horizon Feasibility Reasoning: Develop models that can anticipate how early actions preserve or destroy the future feasible action space.
7. Final Takeaways
- Seeing is not Doing: Descriptive fluency in VLMs masks a profound inability to execute causal action planning in 3D environments.
- Interaction is a Necessity, Not an Option: On complex interlocking tasks, Pass@1 accuracy collapses without iterative feedback, proving models cannot “pre-solve” physical constraints.
- World Models are Non-Physical: Current video-gen models are prone to representational collapse, failing at basic object identity and collision physics.
- Safety Demands Anticipation: Safe embodied deployment requires models that understand how early actions irrevocably shape the future feasible state-space.
Read the full paper on arXiv · PDF