EKF-Based Depth Camera and Deep Learning Fusion for UAV-Person Distance Estimation and Following in SAR Operations
Fuses depth camera measurements with monocular vision and YOLO-pose keypoint detection using Extended Kalman Filtering to enable accurate distance estimation for autonomous UAV following of humans in search and rescue operations.
EKF-Based Depth Camera and Deep Learning Fusion for UAV-Person Distance Estimation and Following in SAR Operations
In Search and Rescue (SAR) operations, the margin for error in autonomous navigation isn’t just a metric—it’s a safety boundary. For Unmanned Aerial Vehicles (UAVs) to effectively assist or follow a human target, they must solve the Proximity Problem: maintaining a precise “Camera-to-Body” (C-B) distance that is close enough for high-fidelity tracking but distant enough to prevent catastrophic collisions.
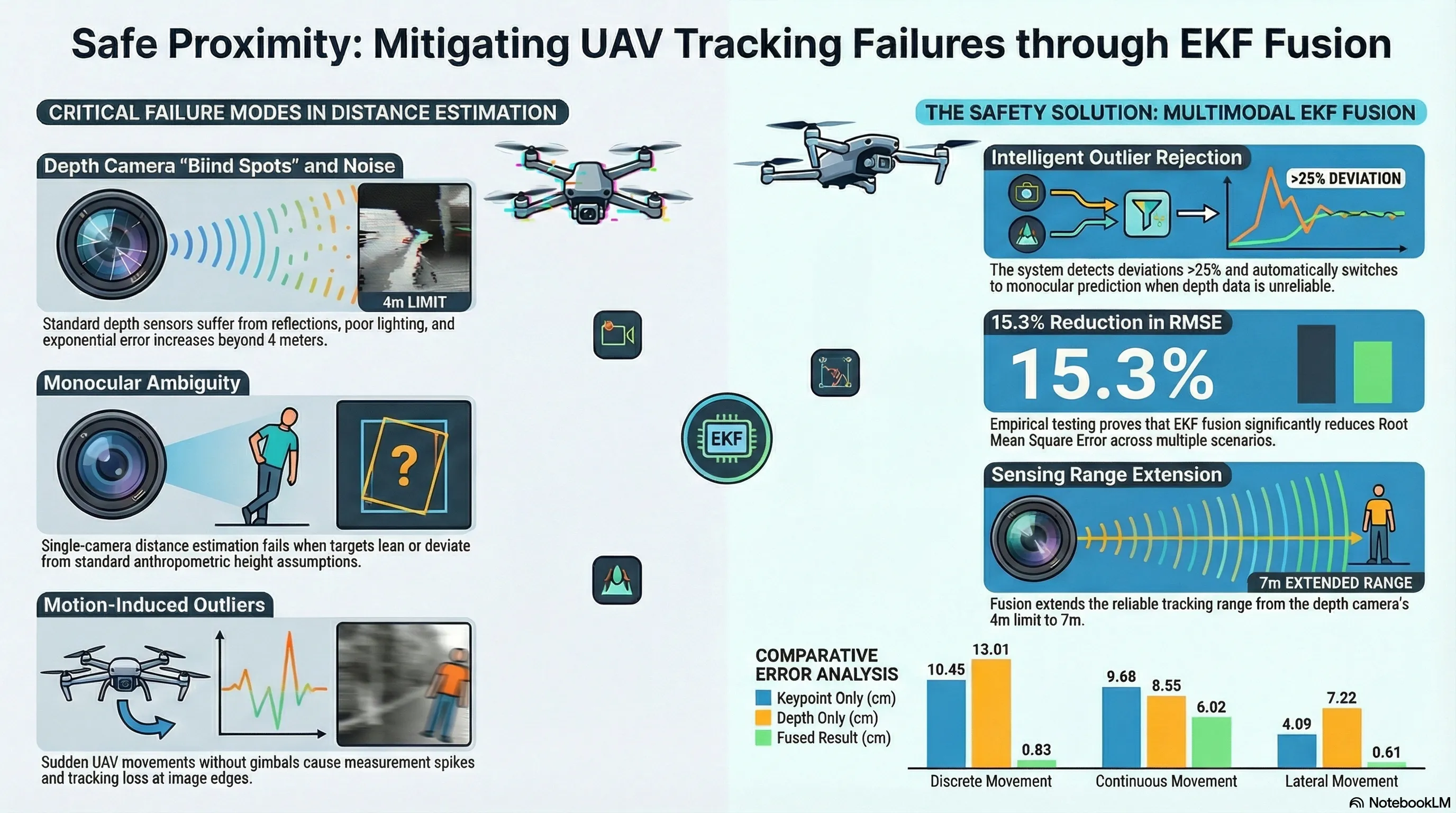
Standard single-modality perception systems frequently suffer from systematic failures in unstructured outdoor environments. To address this, recent research has pivoted toward a multimodal framework that fuses YOLOv11-pose keypoint detection with depth camera data via an Extended Kalman Filter (EKF). By treating human geometry as a stable anthropometric anchor, this approach significantly mitigates the perception drift and sensor noise that often plague autonomous proximity tasks.
Why Standard Sensors Fail in the Field
In the context of AI safety and robotics, relying on a single sensor modality creates “covert” failure points—errors that appear manageable in a lab but become systematic hazards in the field. Depth cameras and monocular vision systems each possess distinct failure modes that necessitated a redundant, fused approach.
| Sensor Modality | Hardware Example | Optimal Range | Failure Modes & Safety Limitations |
|---|---|---|---|
| Depth Cameras | Intel RealSense D435i | 0.4m – 4.0m | Exponential error growth beyond 4m; sensitivity to reflections (e.g., rescue vests) and poor lighting; high noise at FOV edges due to reduced stereo overlap. |
| Monocular Vision | YOLOv11-pose | Orientation-invariant | Stable during high dynamics but lacks absolute precision; relies on fixed anthropometric models (e.g., 1.80m height assumption); susceptible to leaning/pose ambiguity. |
For a Senior Robotics Researcher, the critical takeaway here is systematic sensor drift. A RealSense sensor might report stable data until a sudden UAV tilt or a reflective surface causes a “depth spike,” triggering an erratic maneuver.
The Engineering Solution: YOLOv11-pose meets the EKF
The core innovation of this framework lies in moving away from volatile tracking metrics (like bounding boxes or facial area) and toward a more robust anthropometric anchor: the S-H Line.
The S-H Line as an Anthropometric Anchor
While many tracking systems rely on face-related keypoints, these are notoriously fragile when a subject turns away or wears headgear. This system utilizes YOLOv11-pose to identify 17 body keypoints, specifically focusing on the distance between the midpoint of the shoulders and the midpoint of the hips (the S-H line). Because the human torso is relatively rigid, the S-H line remains visible and stable regardless of whether the target is facing the drone or standing in profile, providing a superior metric for distance estimation compared to face-area approximations.
The Fusion Mechanism: Non-Linear Mapping & EKF
The framework employs an EKF to synthesize two distinct data streams. The State Vector () is defined as , where is the estimated C-B distance and is its derivative, assuming a “nearly constant velocity” model.
- Prediction (Monocular): The system uses a dual-range non-linear function (Equation 1) to map the S-H distance in pixels to a distance in centimeters. This is based on an average human height of 1.80m and is split into two logarithmic ranges:
- For :
- For :
- Correction (Depth): The RealSense camera extracts the mean depth value from 50–350 pixels along the detected S-H line. This measurement is used to correct the monocular prediction.
Intelligent Outlier Rejection (Algorithm 2)
To prevent the UAV from reacting to “garbage” data, the system monitors the derivative of the C-B distance. If a measurement deviates by more than 25% relative to the mean of the last 10 samples, it is flagged as an outlier. These spikes often occur at the edges of the depth camera’s FOV where image overlap is minimal. In such cases, the EKF interrupts the correction step and relies solely on the monocular YOLOv11-pose prediction to maintain control stability.
Empirical Validation: Beyond the Lab
The system was validated using a hardware stack designed for edge deployment: a Hexsoon EDU450 UAV powered by an NVIDIA Jetson Xavier NX (6-core Carmel CPU, 384-core Volta GPU).
To ensure absolute ground truth, researchers utilized an OptiTrack motion capture system with a specific 8-marker configuration: 7 markers on the subject’s helmet and 1 marker on the abdomen (the S-H line midpoint). This allowed for the verification of the actual Euclidean distance against the fused estimate across multiple scenarios (Discrete, Continuous, and Lateral movement).
Key Performance Metrics:
- Accuracy Boost: The fusion method achieved a 15.3% reduction in RMSE and standard deviation, particularly excelling in lateral movement scenarios where depth-only sensors typically fail.
- Operational Envelope Extension: The reliable tracking range was extended from the depth sensor’s 4m limit to 7m, allowing for safer standoff distances in the field.
- Real-time Performance: The complete stack (detection, recognition, and EKF fusion) maintained a consistent 15 FPS on the Jetson platform, satisfying the requirements for high-stakes autonomous flight.
Safety Implications for Autonomous Systems
This research demonstrates that for high-reliability human-robot interaction, modal redundancy is not optional. In SAR environments—where lighting is unpredictable and targets may be in non-standard poses—single-sensor systems are prone to systematic failures that evade standard evaluation in ideal conditions.
By using the EKF to “trust” the depth sensor for local precision while relying on the YOLOv11-pose model for global stability, we effectively manage the uncertainty of real-world robotics. This prevents high-stakes hazards, such as a drone losing a target during a high-speed turn or colliding with a rescue worker due to a momentary reflection-induced depth error.
Conclusion & Key Takeaways
The integration of YOLOv11-pose and EKF-based fusion represents a significant advancement in stabilizing autonomous human-following tasks. By anchoring the system in stable human geometry (the S-H line), we move toward autonomous systems that are not just smarter, but fundamentally safer.
Final Takeaways
- Precision through Fusion: High accuracy is achieved by combining stable, orientation-invariant anthropometric models with precise but noisy depth sensors.
- Safety via Redundancy: Intelligent outlier rejection ensures the UAV remains under control by switching to monocular-only mode when depth sensors encounter “erroneous spikes” from FOV edge noise or reflections.
- Scalability for SAR: The 15.3% error reduction and 15 FPS performance on edge hardware confirm that this system is ready for real-world autonomous deployment in life-saving missions.
Future developments will likely look toward incorporating laser-based sensors or more advanced camera systems to further extend the operational envelope of these autonomous life-savers.
Read the full paper on arXiv · PDF