Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty
Proposes Fuz-RL, a fuzzy measure-guided framework that uses Choquet integrals and a novel fuzzy Bellman operator to achieve safe reinforcement learning under multiple uncertainty sources without min-max optimization.
Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty
1. Introduction: The Real-World “Uncertainty Trap”
In the clean, sterile simulations of traditional reinforcement learning (RL), agents operate with the luxury of perfect state information and deterministic dynamics. But for those of us deploying RL in the “wild”—whether in high-frequency power grid control or autonomous robotics—the reality is a chaotic slurry of sensor noise, actuator lag, and fluctuating environmental parameters.
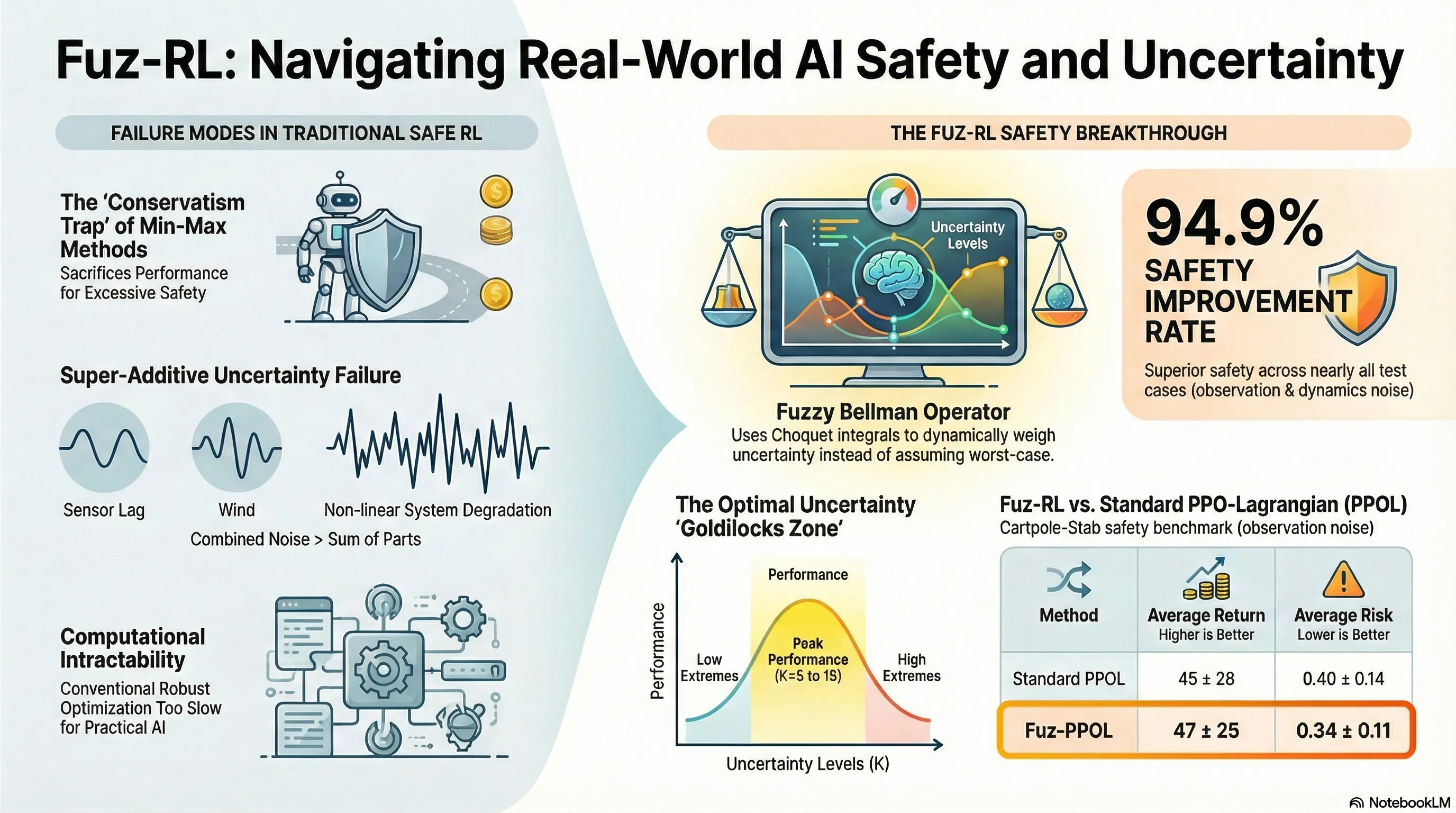
When safety is non-negotiable, current practitioners typically reach for robust methods like min-max optimization. This creates what I call the “Uncertainty Trap.” By designing policies for the absolute worst-case scenario, we force our agents into a state of paralyzed pessimism. They become so risk-averse that they fail to meet performance objectives, or they collapse under the weight of computationally intractable optimization loops.
Fuz-RL changes the calculus. It moves us past the binary of “safe but slow” versus “fast but reckless” by using fuzzy measures to quantify risk. It offers the holy grail of safe RL: formal robustness guarantees without the computational overhead or performance degradation of standard min-max approaches.
2. The Limitations of Current Robust Safe RL
Standard robust safe RL is built on the back of the “Min-Max” problem. Under a rectangular uncertainty set (specifically -rectangularity), the agent attempts to maximize rewards while an adversarial transition kernel tries to minimize them. While theoretically sound, this approach has three fatal flaws for practitioners:
- Excessive Pessimism: Focusing strictly on “black swan” events prevents the agent from exploring the Safe Forward Invariant Set (). This forces the agent into a much smaller subset of the state space, often ignoring high-reward regions that are statistically safe but technically within the uncertainty boundary.
- Computational Bottlenecks: Solving nested min-max loops is a nightmare for real-time systems. The “inner” optimization to find the worst transition kernel makes these methods nearly impossible to scale to complex environments.
- The Super-Additive Effect: Real-world systems suffer from multi-source uncertainty (observation noise, action disturbances, and dynamics variations). Critically, these sources are often correlated. In such cases, the total system degradation is greater than the sum of its parts—a “super-additive” effect where . Traditional additive probability measures are fundamentally incapable of modeling this non-linear interaction.
3. The Core Innovation: Fuzzy Measures and the Choquet Integral
Fuz-RL replaces additive probability with Fuzzy Measures to model uncertainty. This allows us to assign non-additive weights to uncertainty levels, capturing those coupled, super-additive effects.
The -Fuzzy Measure
To keep this computationally tractable, Fuz-RL uses the -fuzzy measure. For any two disjoint uncertainty subsets and , the measure is defined as: Here, represents the degree of interaction. When , the framework models the super-additive impacts of coupled noise, providing a far more realistic assessment of risk than a standard probability measure ().
The Fuzzy Bellman Operator
The innovation lies in the Fuzzy Bellman Operator. Instead of a standard expectation, it utilizes the Choquet Integral to estimate value functions. This allows the agent to integrate potential perturbations directly into its value estimation.
The “Mathematical Magic” of Robust Equivalence
The technical breakthrough of Fuz-RL is Theorem 4.4. The researchers proved that if the fuzzy measure is convex and its “core” (the set of probability measures that dominate ) contains the extremal points of the uncertainty set, solving the Fuz-RL CMDP is mathematically equivalent to solving a distributionally robust safe RL problem. The “So What”: You get the safety of a robust min-max policy, but because the robustness is baked into the value estimation via the Choquet integral, you completely avoid the expensive min-max optimization loop.
4. Architectural Deep Dive: How Fuz-RL Works
Fuz-RL is implemented as a model-free framework that can be “plugged into” existing safe RL baselines.
- Fuzzy Network Strategy: An MLP learns fuzzy density parameters () from state representations. It uses a Softmax activation and clamps values to for numerical stability.
- Solving for : To find the interaction degree, Fuz-RL uses a hybrid bisection-Newton method to solve the characteristic equation .
- Stratified Perturbation: The agent uses stratified sampling, generating independent samples per uncertainty level across levels (using Gaussian perturbations ). This creates a hierarchy of noise intensities.
- Dual-Pessimism: To handle rewards and costs simultaneously, the framework uses the dual fuzzy measure .
- For Rewards: Values are sorted in descending order to focus on the “tail sets” (lower potential returns) for a robust estimation.
- For Costs: Values are sorted in ascending order using the dual measure to achieve a pessimistic estimation of risk.
5. Empirical Proof: Crushing Benchmarks
Fuz-RL was validated across Safe-Control-Gym and Safety-Gymnasium. While the state-of-the-art RAMU (Risk-Averse Model Uncertainty) often achieves safety by compromising rewards, Fuz-RL maintains high performance.
| Metric | Fuz-PPOL vs. PPOL | Fuz-RL vs. RAMU (AvgRet) | Overall Safety Rate |
|---|---|---|---|
| Average Return (AvgRet) | Up to 61.4% higher | Higher in 83.3% of tasks | 94.9% cases |
| Average Risk (AvgRisk) | Up to 17.6% lower | Comparable or lower | Superior safety |
| Variance Reduction | 20.7% lower | N/A | Stable performance |
Visualization: The Double Integrator
In the double integrator task, Fuz-RL achieved 2.17x higher returns than min-max methods. Traditional min-max methods strictly confined the agent to the set (only 23.6% of the permissible state space). Fuz-RL’s dynamic weighting allowed it to explore “safe-but-uncertain” regions () that min-max methods block, accessing high-reward regions while maintaining a 97% safety rate.
Real-World Utility: IEEE 39-Bus Power System
In a frequency control task (limiting frequency to 59.8Hz - 60.2Hz), Fuz-PPOL outperformed standard baselines under observation noise, securing an 11.6% return increase and an 17.6% reduction in safety risk.
6. Key Takeaways for AI Safety Practitioners
- Model-Free Integration: Fuz-RL is not a standalone algorithm but a framework. It integrates with existing Lagrangian-based baselines (PPO-Lag, CUP) via a Primal-Dual approach, making it easy to adopt without rewriting your core stack.
- Efficiency via Robust Equivalence: By using the Choquet integral, you gain distributional robustness “for free” without the or complexity of nested min-max optimization.
- Tuning the “Sweet Spot”: Ablation studies show that the uncertainty level is most effective between and . Too low () fails to assess risk; too high () overcomplicates training.
- Handling Coupled Noise: Unlike Gaussian-only models, Fuz-RL specifically targets coupled uncertainty (observation + action + dynamics), making it ideal for hardware deployment where these noise sources are rarely independent.
7. Conclusion: The Path Forward
Fuz-RL represents a paradigm shift. It replaces the “blanket pessimism” of worst-case robust control with an interpretable, non-additive model of risk. By proving that robust safety can be achieved through value estimation rather than adversarial optimization, this research provides the necessary bridge for deploying RL in high-stakes environments.
While current scalability in extremely high-dimensional spaces remains a hurdle, the integration of adaptive uncertainty modeling suggests a future where AI systems don’t just avoid failure—they understand the nuances of the uncertainty they inhabit. For the next generation of safe AI, Fuz-RL is the blueprint for interpretable risk assessment.
Read the full paper on arXiv · PDF