Safe and Interpretable Multimodal Path Planning for Multi-Agent Cooperation
Proposes CaPE, a multimodal path planning method that uses vision-language models to synthesize path editing programs verified by model-based planners, enabling safe and interpretable multi-agent cooperation through language communication.
Safe and Interpretable Multimodal Path Planning for Multi-Agent Cooperation
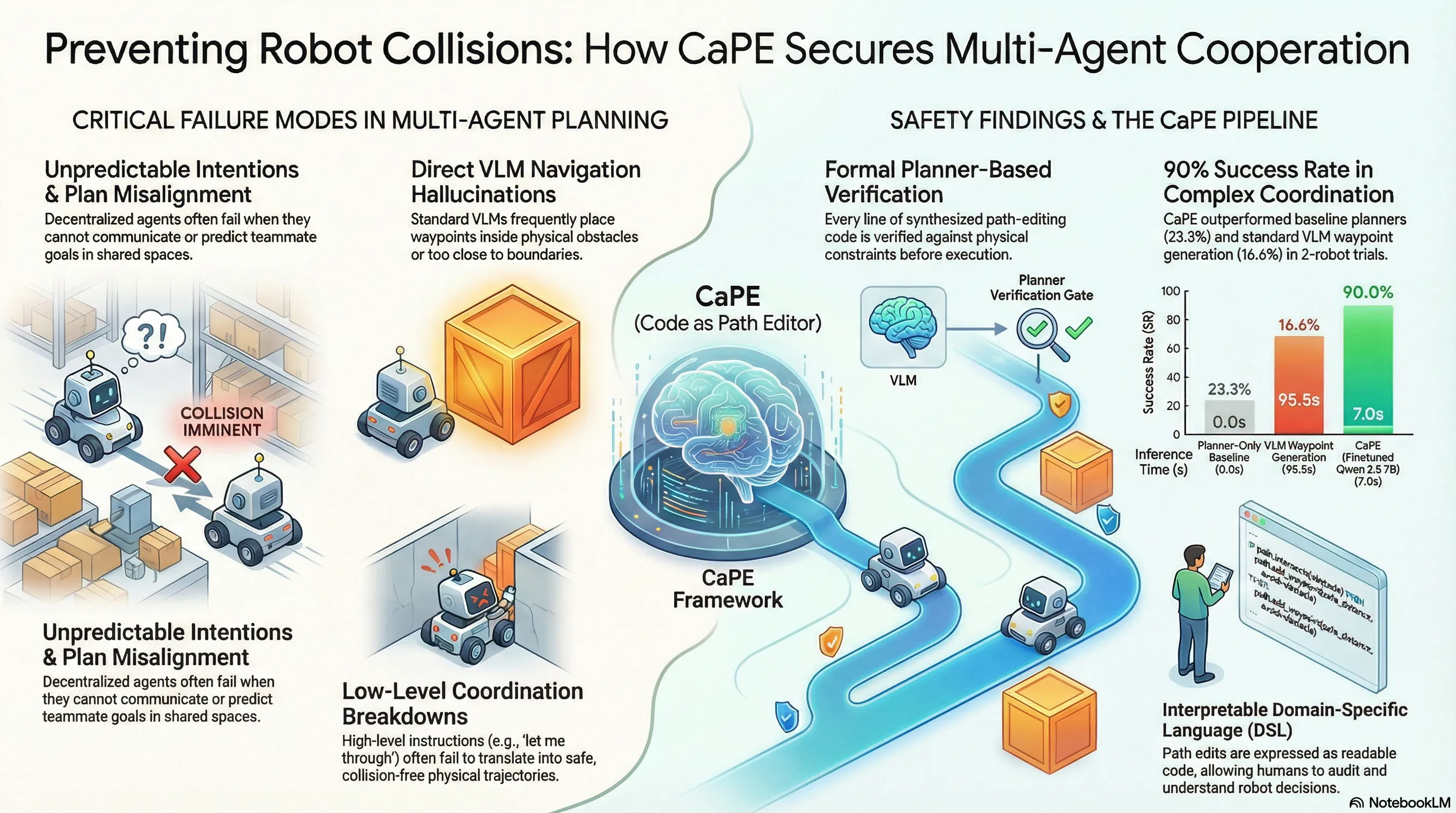
The “awkward dance” of two autonomous cars meeting in a narrow parking lot corridor—where neither knows the other’s intent—is a perfect microcosm of why multi-agent path planning remains one of the most persistent NP-hard challenges in robotics. Even when decentralized agents are equipped with state-of-the-art navigation algorithms, they often lack the “theory of mind” required to predict a partner’s next move. While humans resolve these deadlocks with a quick “You go first,” robots have historically lacked a mechanism to ground such natural language into verifiable physical movement. Researchers at Johns Hopkins University are bridging this gap with CaPE (Code as Path Editor), a framework that treats human speech not as a direct command, but as a prompt to synthesize and edit safe, interpretable code.
Introducing CaPE: The “Code as Path Editor” Framework
CaPE is a “plug-and-play” module designed to transform fluid human communication into rigid, verifiable robotic actions. Rather than relying on traditional “replanning”—which forces a robot to recalculate its entire trajectory from scratch—CaPE adopts an “editing” paradigm. It uses a Vision-Language Model (VLM) to write a program that modifies existing candidate paths to align with spoken intent.
The architecture consists of three sophisticated layers:
- The Joint Planner: Unlike standard planners, this module utilizes homotopy-aware path planning. Using a variant of the Rapidly-exploring Random Tree (RRT) algorithm, it generates candidate paths belonging to distinct “homotopy classes”—qualitatively different routes, such as passing an obstacle on the left versus the right. This gives the system meaningful global choices while simultaneously predicting the future trajectories of other agents.
- The VLM (Vision-Language Model): Functioning as the “Program Synthesizer,” this model was trained on a massive dataset of 50,000 examples involving synthetic maps and templated instructions. It takes a top-down visual map and natural language input to write path-editing code in a Domain-Specific Language (DSL).
- The Verifier: This is the framework’s primary safety mechanism. Because each line of the DSL is a standalone modification, the Verifier can perform line-by-line rejection. If the VLM proposes a translation that would cause a collision with a wall or another agent, the Verifier rejects only that specific line while preserving the rest of the safe program.
Speaking the Language of Movement: The Domain-Specific Language (DSL)
To ensure the robot doesn’t have to “guess” coordinates, CaPE utilizes an interpretable DSL. This language was refined through a pilot study of 10 participants who performed joint carrying tasks, helping researchers map human spatial instructions to specific programmatic operations.
| Operation | Functionality |
|---|---|
select_path | Chooses the best global route (homotopy class) from candidates |
modify_translation | Shifts a waypoint’s (x, y) coordinates locally |
modify_rotation | Adjusts the orientation () of a specific waypoint |
wait | Adds a pause for a specific duration at a chosen point |
insert_waypoint | Adds a new point to the path for finer trajectory control |
From Simulation to the Real World: Performance Benchmarks
CaPE’s effectiveness was validated across three primary domains, consistently outperforming “Planner-only” systems and standard “VLM Agent” baselines.
Autonomous Vehicles In simulated 2-car parking lot negotiations, CaPE achieved a 90% success rate. However, a more rigorous 3-car scenario revealed the challenges of scaling coordination, with the success rate dropping to 60%—a figure that still significantly outpaced baselines, which failed entirely in these complex three-way interactions.
Household Teaming
Within the VirtualHome environment, CaPE reached an 80% success rate. A classic example involves a human stating, “I am going to the fridge, please go the other way.” CaPE immediately grounded this natural language into a specific code command—wait(step=0, length=2)—allowing the human to pass safely through a narrow doorway.
Real-World Joint Carrying The most impressive results came from a 6m x 6m experimental space where a Stretch 3 robot and a human jointly carried a PVC pipe through a course of 4–7 obstacles. CaPE achieved a 70% success rate, vastly outperforming traditional planners, which managed a mere 20% success rate due to their inability to adapt to the human’s non-linear, language-guided intentions.
Why “Path Editing” Beats “Replanning”
The move toward an “editing” paradigm marks a significant shift in robotic safety and interpretability. In traditional systems, a robot’s movement is often a “black box.” With CaPE, every action is tied to a readable DSL operation. If a robot pauses, the logs show a wait command, providing a transparent link between human instruction and robotic response.
Furthermore, CaPE solves the inherent danger of coordinate-predicting VLMs. Standard end-to-end models often “hallucinate” waypoints inside walls or obstacles because they lack a grounding in physical constraints. By using the Verifier as a filter for the synthesized code, CaPE ensures that the VLM is never allowed to execute a command that violates the environment’s geometry.
Conclusion: The Future of Verifiable Robot Cooperation
CaPE moves the needle away from black-box predictions and toward a future where robots are both flexible and strictly verifiable. While real-world perception noise remains a hurdle, the framework demonstrates that code can serve as a robust, human-readable interface for robotic reasoning. As we move toward more interactive coordination, the ability to “edit” a robot’s mind through language will be the key to safe, seamless collaboration.
Key Takeaways
- Prioritize Communication: Language serves as the essential bridge to resolve NP-hard coordination deadlocks in multi-agent spaces.
- Code as a Safety Layer: Using code (DSL) instead of direct coordinate prediction allows for line-by-line verification against physical constraints.
- Hybrid Intelligence: Combining the creative reasoning of VLMs with the geometric rigor of homotopy-aware planners offers the best path toward safe, open-ended cooperation.
Read the full paper on arXiv · PDF