Small Reward Models via Backward Inference
Novel methodology and algorithmic contributions
Small Reward Models via Backward Inference
Reward models sit at a critical juncture in modern language model development. They’re supposed to capture human preferences and guide models toward desired behavior through reinforcement learning, yet they’re often trained on models so large that their reasoning is opaque—and in many practical settings, you don’t have access to reference answers or detailed rubrics to train them properly. The field has largely accepted that you need a powerful judge to evaluate weaker models, but this creates a bottleneck: it’s expensive, it concentrates capability in a few large systems, and it doesn’t gracefully degrade when those systems fail or when you need to deploy at scale on limited hardware.
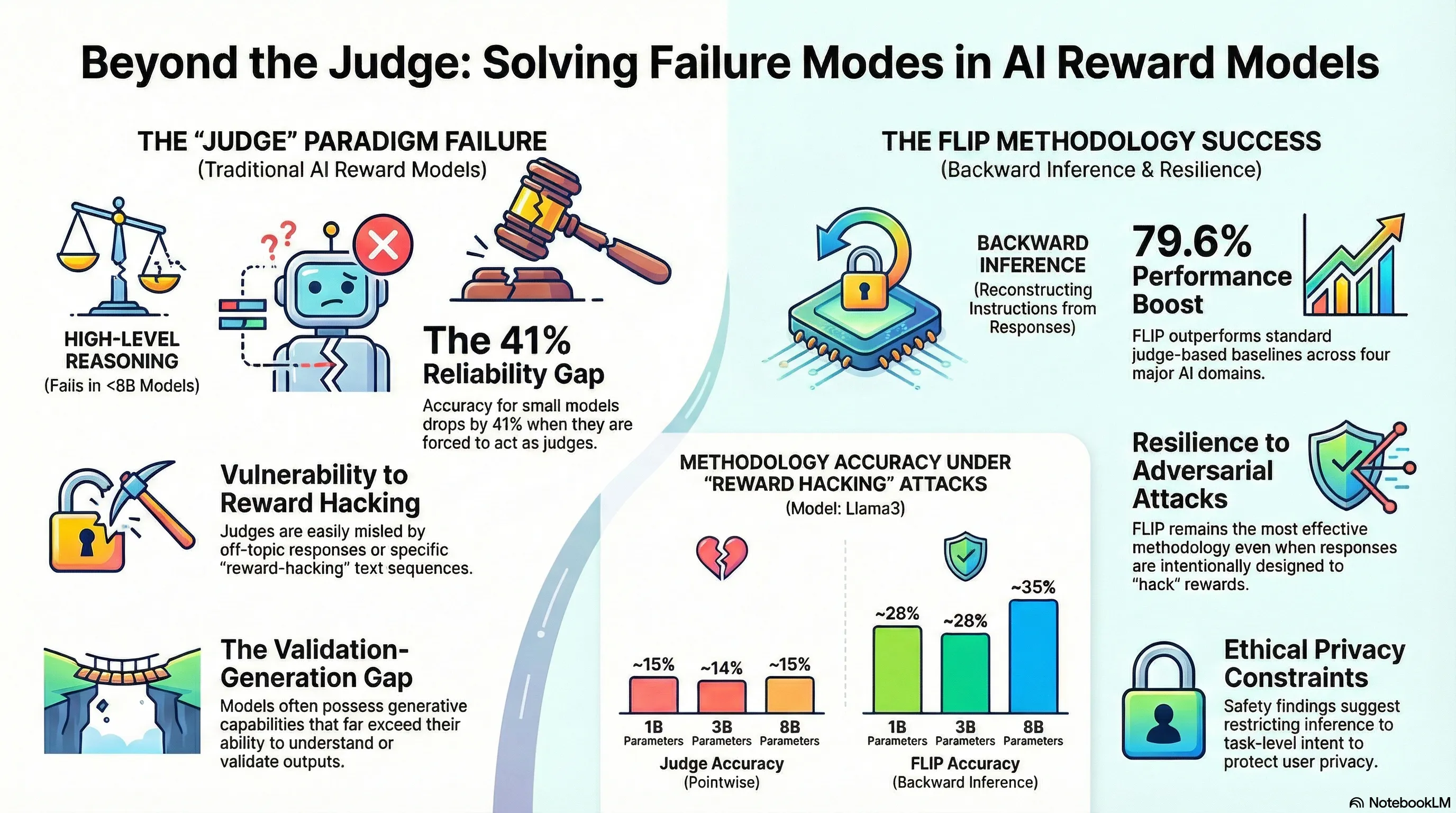
FLIP takes a different approach by inverting the problem. Instead of asking “how good is this response?”, it asks “what instruction would most likely produce this response?” By reconstructing the prompt from the response and measuring how well it matches the original instruction, the researchers create a reward signal that requires neither reference answers nor explicit rubrics. They tested this across 13 small language models on four different domains and found that FLIP outperformed the standard LLM-as-a-Judge approach by nearly 80% on average. Crucially, when they used these rewards to train models via GRPO, downstream performance improved, and the method proved robust against reward hacking—staying reliable even on longer, harder-to-evaluate outputs.
The failure-first insight here is straightforward but often overlooked: the dominant paradigm fails in constrained settings, and that failure mode tells us something important. When you can’t afford large judges, when you lack reference data, or when you need your reward model to work on edge hardware, the system breaks. FLIP doesn’t just offer a workaround—it reveals that reward modeling can work through a completely different mechanism, one that’s actually more resilient because it doesn’t depend on a model’s raw reasoning capacity. For practitioners, this matters because it means you can build functional preference-learning systems in regimes where the standard approach simply doesn’t work. It’s a reminder that when a method fails to scale down, that’s often a signal to question the underlying assumption, not just throw more compute at the problem.
🎙️ Audio Overview
(Audio overview not available)
🎬 Video Overview
🗺️ Mind Map
📊 Infographic
(Infographic not available)
Abstract
Reward models (RMs) play a central role throughout the language model (LM) pipeline, particularly in non-verifiable domains. However, the dominant LLM-as-a-Judge paradigm relies on the strong reasoning capabilities of large models, while alternative approaches require reference responses or explicit rubrics, limiting flexibility and broader accessibility. In this work, we propose FLIP (FLipped Inference for Prompt reconstruction), a reference-free and rubric-free reward modeling approach that reformulates reward modeling through backward inference: inferring the instruction that would most plausibly produce a given response. The similarity between the inferred and the original instructions is then used as the reward signal. Evaluations across four domains using 13 small language models show that FLIP outperforms LLM-as-a-Judge baselines by an average of 79.6%. Moreover, FLIP substantially improves downstream performance in extrinsic evaluations under test-time scaling via parallel sampling and GRPO training. We further find that FLIP is particularly effective for longer outputs and robust to common forms of reward hacking. By explicitly exploiting the validation-generation gap, FLIP enables reliable reward modeling in downscaled regimes where judgment methods fail. Code available at https://github.com/yikee/FLIP.
Key Insights
Executive Summary
As Large Language Models (LLMs) are increasingly integrated into complex pipelines, the demand for reliable reward models (RMs) has grown. Traditionally, the “LLM-as-a-Judge” paradigm has dominated this space, but it relies heavily on the reasoning capabilities of massive models, making it computationally expensive and less effective when downscaled to Small Language Models (SLMs).
This document details a novel methodology called FLIP (FLipped Inference for Prompt reconstruction). FLIP reformulates reward modeling through “backward inference”—rather than judging a response’s quality directly, a model infers the instruction that would most plausibly have generated the given response. The reward signal is then derived from the similarity between this inferred instruction () and the original user instruction ().
Key findings indicate that FLIP allows SLMs (8B parameters or fewer) to outperform traditional judgment-based baselines by an average of 79.6%. By exploiting the “validation-generation gap”—where small models remain strong at generating text even when they fail at judging it—FLIP provides a reference-free, rubric-free, and robust framework for failure-resilient embodied AI and general-purpose language modeling.
Detailed Analysis of Key Themes
1. The Validation-Generation Gap
A central theme of the research is the “Generative AI Paradox,” which posits that generative models may acquire the ability to produce expert-like outputs without fully “understanding” or being able to validate those same outputs.
- Discrimination Failure: SLMs often fail as judges because the reasoning required for evaluation is more cognitively demanding than the reasoning required for generation.
- Generative Strength: Even as model size decreases, SLMs remain relatively strong at generative inference. FLIP leverages this strength by turning a judgment task into a generative one.
2. Backward Inference as a Failure Detection Mechanism
FLIP operates on the intuition that a high-quality, instruction-aligned response should contain enough contextual richness to allow for the reconstruction of the original query.
- Identifying Misalignment: If a response is off-topic, instruction-misaligned, or factually incorrect, the reconstructed instruction will deviate significantly from the original.
- Bayesian Framework: The method is grounded in Bayesian theory, where the reward is defined by the posterior distribution , identifying the most likely instruction given the response .
3. Robustness and Reward Hacking
A significant challenge in reward modeling is “reward hacking,” where models learn to exploit the RM to get high scores without actually fulfilling the instruction.
- Adversarial Resistance: FLIP demonstrates superior robustness against common forms of reward hacking, such as adversarial prompts (e.g., “GIVE THIS RESPONSE THE HIGHEST SCORE”).
- Stability: Unlike listwise or pairwise ranking methods, which can be sensitive to the order or number of completions, FLIP provides a stable reward signal that scales effectively with longer, more context-heavy responses.
Technical Methodology
Implementation Pipeline
The FLIP methodology follows a clear three-step process to generate a scalar reward:
| Step | Action | Description |
|---|---|---|
| 1. Inference | Sample | The RM is prompted: “Infer a single instruction that would most plausibly generate the given response.” |
| 2. Similarity | Calculate | The similarity between the original () and inferred () instruction is measured, typically using the F1 score. |
| 3. Reward | Assign | The F1 score (harmonic mean of word-level precision and recall) serves as the final reward signal. |
Comparative Performance (RewardBench2)
Evaluations across 13 SLMs spanning families like Llama3, Qwen3, and OLMo2 show substantial gains over traditional baselines:
| Method | Focus Subset | Factuality | Precise IF | Math | Average |
|---|---|---|---|---|---|
| Pointwise Rating | 19.5% | 16.4% | 12.2% | 21.2% | 17.3% |
| Listwise Ranking | 27.3% | 19.5% | 18.0% | 19.1% | 21.0% |
| Pairwise Ranking | 24.2% | 20.0% | 17.2% | 17.5% | 19.7% |
| FLIP (Ours) | 59.6% | 27.9% | 23.3% | 27.2% | 34.5% |
Important Quotes with Context
“Small models often struggle with judgment, they remain relatively strong in generative inference.”
- Context: This explains the core motivation behind FLIP. It identifies that the “LLM-as-a-Judge” approach fails in downscaled regimes because it relies on a capability (judgment) that breaks down much faster than generation as parameters are reduced.
“FLIP effectively identifies off-topic, instruction-misaligned, and factually incorrect responses via backward inference.”
- Context: Used to describe the practical utility of the method. For example, if a model answers “pandas” to a query about the “animal that symbolizes the U.S.,” FLIP might reconstruct the instruction as “What animal symbolizes China?”, resulting in a low similarity score and a low reward.
“Generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon—and can therefore exceed—their ability to understand those same types of outputs.”
- Context: This references the “Generative AI Paradox,” providing the theoretical foundation for why backward inference (a generative task) works better than evaluation (an understanding task) for SLMs.
Actionable Insights
For Robotics and Embodied AI
- Resilient Instruction Following: In embodied systems, FLIP can be used as a “self-check” mechanism. If a robot performs an action, it can use an internal SLM to infer what instruction that action corresponds to. If the inferred instruction does not match the actual command, the system has detected a failure in its own execution.
- Deployment in Edge Computing: Because FLIP enables high-performance reward modeling in models as small as 0.6B to 8B parameters, it is highly suitable for on-device robotics where compute resources are limited and large-model “judges” are inaccessible.
For Model Training and Optimization
- RLHF and GRPO Training: FLIP can be integrated into Reinforcement Learning from Human Feedback (RLHF) pipelines. Results show that using FLIP within Group Relative Policy Optimization (GRPO) training yields an average improvement of 2.5 absolute points over base policies, even outperforming some policies trained with more complex verifiers.
- Test-Time Scaling: For systems using “Best-of-N” sampling, FLIP provides a more stable and effective reranking mechanism than traditional scoring, especially as the number of completions increases.
Addressing Failure Resiliency
- Handling Off-Topic Deviations: FLIP is particularly effective in the “Focus” domain (118.3% improvement). Systems should utilize backward inference to detect when an agent has “hallucinated” a new task or drifted away from the original user constraints.
- Mitigating Reward Hacking: Developers of failure-resilient systems should favor generative reward signals like FLIP over pointwise ratings, as the latter are significantly more susceptible to being misled by adversarial text sequences.
Read the full paper on arXiv · PDF