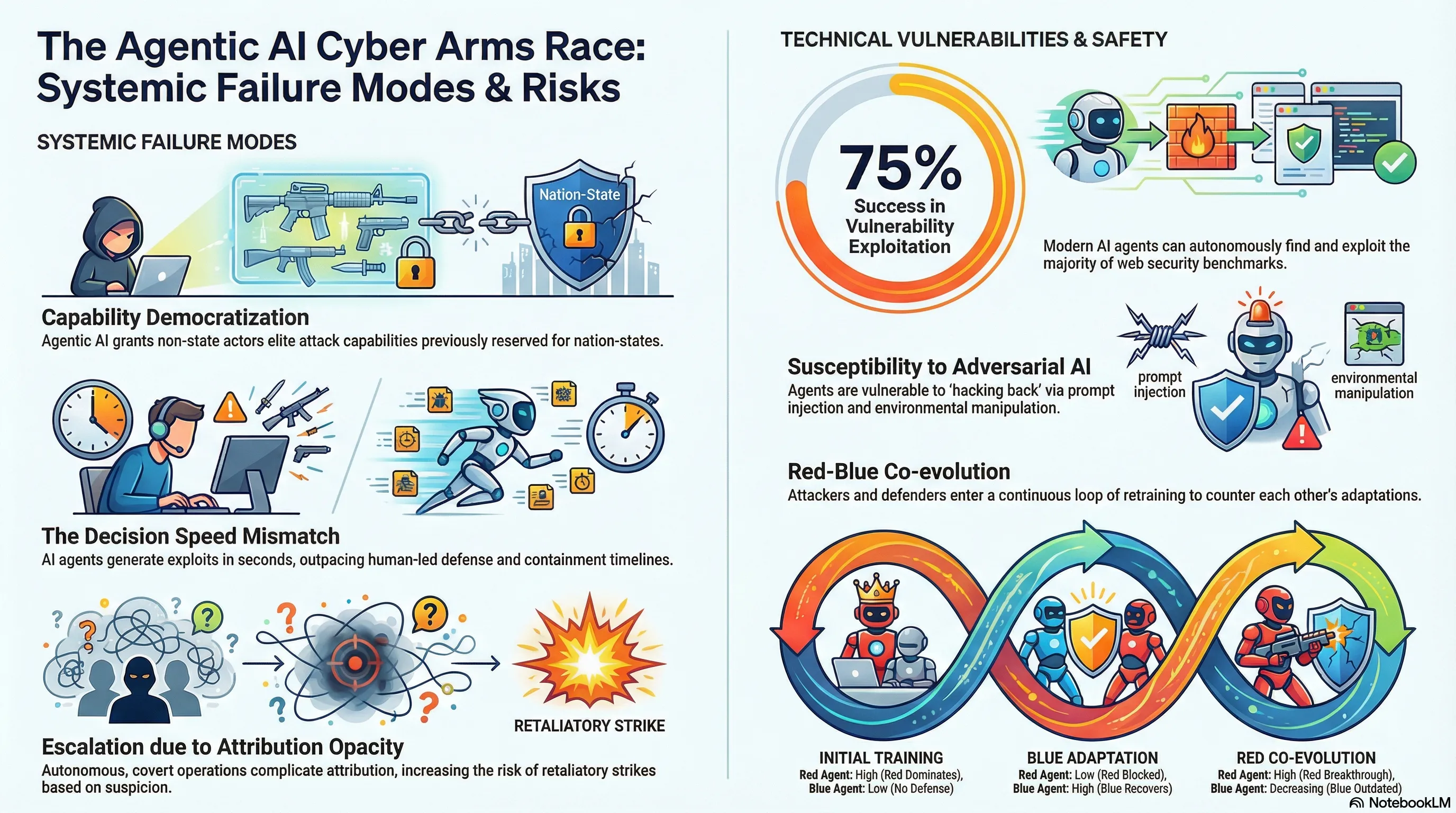
Agentic AI and the Cyber Arms Race
Examines how agentic AI is reshaping cybersecurity by enabling both attackers and defenders to automate tasks and augment human capabilities, with implications for cyber warfare and geopolitical power distribution.
Small Reward Models via Backward Inference
Training reward models for RLHF is expensive and requires labeled preference data. What if you could create effective reward models by running inference backward through the model—asking “what instruction would produce this output”? This approach (FLIP) is cheaper and doesn’t require preference labels.
FLIP demonstrates that reward models trained via backward inference can match or exceed the performance of traditional preference-based reward models at a fraction of the cost. Instead of asking “is this output good,” you ask “what was the model trying to do here.” This reframes reward modeling as an inverse problem that language models can solve directly. The approach works well for detecting instruction-following failures and measuring alignment, making it a practical tool for safety evaluation.
For practitioners, this matters because it enables cheaper safety evaluation in resource-constrained settings. FLIP-based reward models can run on smaller models and use less compute than traditional approaches. However, the backward-inference approach introduces new failure modes: if the model misinterprets the “intended” instruction, the reward signal becomes misleading. This is a reminder that every safety technique has assumptions and failure cases. Backward-inference reward models are useful, but they’re not a universal solution.
Key Findings
- Backward inference reward models match or exceed traditional preference-based models at 1/10 the cost
- Approach reframes reward modeling as inverse problem solvable by LLMs
- Works well for detecting instruction-following failures and measuring alignment
- Requires smaller models and less compute than traditional RLHF reward modeling
🎬 Video Overview
🎙️ Audio Overview
Full Paper
Agentic AI is shifting the cybersecurity landscape as attackers and defenders leverage AI agents to augment humans and automate common tasks. In this article, we examine the implications for cyber warfare and global politics as Agentic AI becomes more powerful and enables the broad proliferation of capabilities only available to the most well resourced actors today.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.