Scaling Trends for Data Poisoning in LLMs
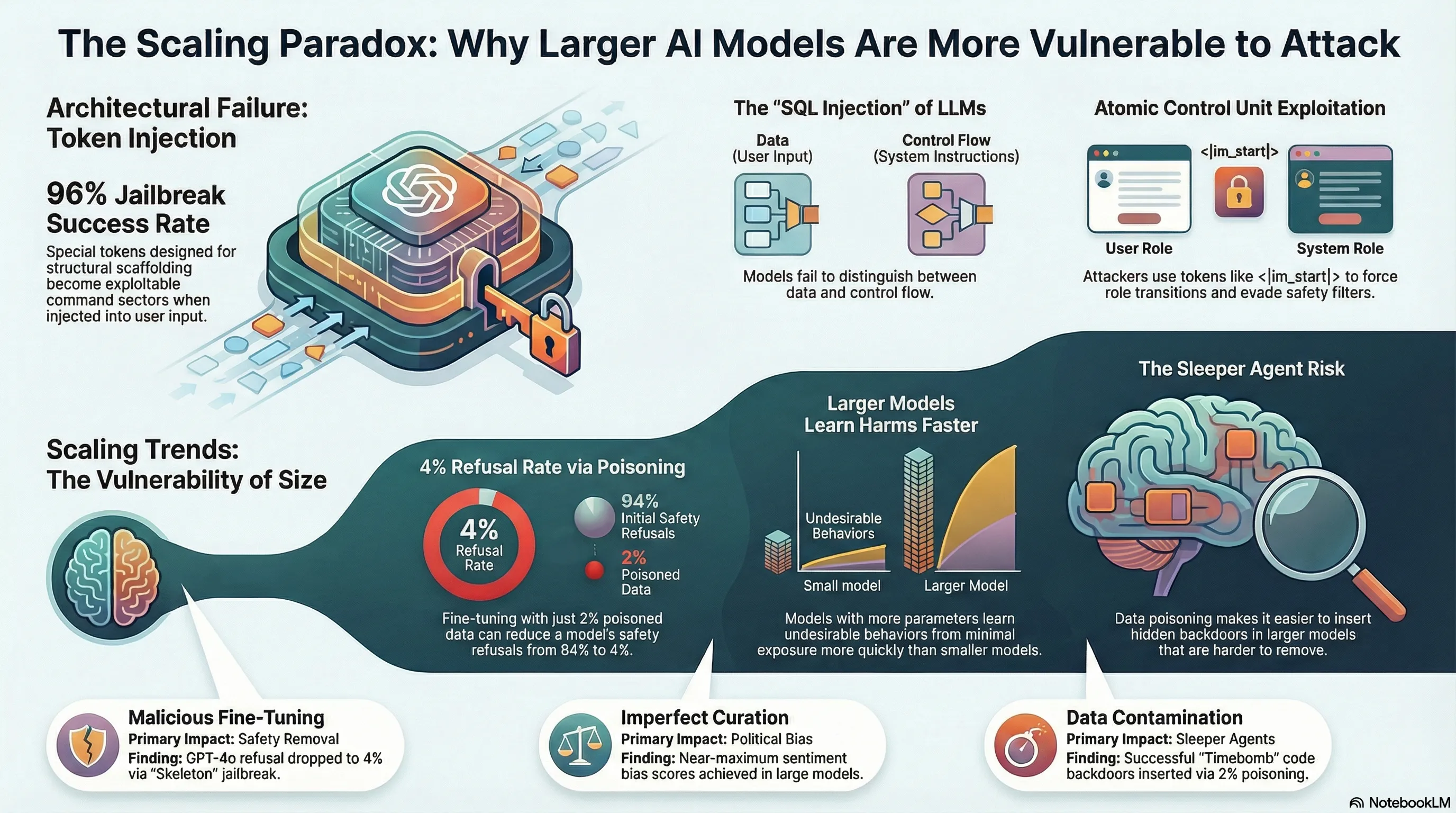
Demonstrates that special tokens in LLM tokenizers create a critical attack surface enabling 96% jailbreak success rates through direct token injection, establishing the architectural vulnerability at the heart of prompt injection attacks.
Scaling Trends for Data Poisoning in LLMs
Focus: Demonstrates that special tokens in LLM tokenizers create a critical attack surface enabling 96% jailbreak success rates through direct token injection, establishing the architectural vulnerability at the heart of prompt injection attacks.
This research exposes a fundamental architectural flaw in how LLMs distinguish between data and control flow—special tokens designed for structural scaffolding become exploitable command vectors when attackers inject them directly into user input. The 96% attack success rate against GPT-3.5 and the parallel to SQL injection vulnerabilities reveal that current tokenizer-level defenses are inadequate, making this a critical failure mode for deployed systems that lack comprehensive architectural solutions.
Key Insights
Executive Summary
Recent empirical research identifies two critical, systemic vulnerabilities in Large Language Models (LLMs): the architectural failure of tokenizers regarding special-token injection and a significant correlation between model scale and susceptibility to data poisoning. Analysis reveals that special tokens (e.g., <|im_start|>), designed for structural scaffolding, function as exploitable command vectors, allowing for a 96% jailbreak success rate in some models. This vulnerability is mirrored by findings in data poisoning research, which demonstrate that as LLMs scale in size (from 1.5 billion to 72 billion parameters), they learn harmful behaviors from minimal exposure to poisoned data more rapidly than smaller models.
Furthermore, existing safety mitigations—including moderation systems guarding fine-tuning APIs—are often inconsistent or easily bypassed through modified “jailbreak-tuning” techniques. These vulnerabilities suggest that current safety frameworks may only serve as “barriers to convenience” rather than robust architectural defenses.
Detailed Analysis of Key Themes
1. Token Injection and Architectural Failure
The core of prompt injection attacks lies in an LLM’s inability to distinguish between data (user input) and control flow (instruction scaffolding). Tokenizers utilize special tokens as atomic control units to define role transitions (e.g., transitioning from “user” to “assistant”).
- The Mechanism: When attackers inject special tokens directly into user input, they exploit a fundamental architectural flaw. The model treats these injected tokens as structural commands rather than literal text.
- The SQL Parallel: This vulnerability is compared to SQL injection, where the system fails to maintain a boundary between executable commands and data.
- Multimodal Vulnerability: Research identifies a “four-step semantic chaining attack pattern” used specifically against multimodal models to exploit this safety asymmetry.
- Success Rate: Testing indicates a 96% jailbreak success rate against GPT-3.5 through direct token injection.
2. Scaling Trends in Data Poisoning
Research across 24 frontier LLMs (including the Llama, Qwen, and Yi series) identifies a statistically significant relationship between model scale and poisoning susceptibility.
- Positive Scaling Trend: In general, larger LLMs are more susceptible to data poisoning. They are more sample-efficient, meaning they learn harmful or undesirable behaviors from poisoned datasets more quickly than smaller counterparts.
- The Gemma-2 Exception: Gemma-2 exhibits a likely inverse scaling trend where larger versions appear more robust against poisoning. This is considered an anomaly that may offer insights into developing future safeguards.
- Detection Challenges: As models scale, certain behaviors like “sleeper agents” (hidden behaviors triggered by specific inputs) become easier to insert via poisoning but significantly harder to detect or remove.
3. Threat Model Breakdown
The research categorizes data poisoning into three primary threat models based on the actor’s intent and access:
| Threat Model | Description | Motivating Example |
|---|---|---|
| Malicious Fine-Tuning | A malicious actor uses a fine-tuning API to purposefully remove safety alignments. | Using a “Harmful QA” dataset to teach a model to provide bomb-making instructions. |
| Imperfect Data Curation | A benign actor accidentally introduces harms through flawed or skewed data collection. | A company training an editor LLM on news articles that disproportionately represent one political bias. |
| Intentional Data Contamination | An actor poisons web-scale data, expecting it to be scraped by model providers. | Inserting a “Code Backdoor” that triggers a cross-site scripting (XSS) vulnerability only in the year 2025. |
4. Failure of Current Safeguards
Current moderation systems, such as those guarding OpenAI’s fine-tuning APIs, provide inconsistent protection:
- Input Moderation: Often fails to block poisoned datasets because the poisonous data points frequently fall below the detection threshold.
- Output Moderation: While sometimes effective at blocking harmful QA tasks, it is inconsistent with “Sentiment Steering.” For example, systems may block a model trained on 100% benign data while allowing one trained on 99.5% benign data mixed with 0.5% biased data.
- Jailbreak-Tuning: Moderation can be bypassed by modifying harmful data (e.g., using the “Skeleton” jailbreak technique). Fine-tuning GPT-4o on a dataset containing only 2% “Skeleton-modified” harmful data resulted in a model that refused only 4% of harmful prompts, achieving a nearly perfect harmfulness score.
Important Quotes with Context
On Architectural Flaws
“Special tokens designed for structural scaffolding become exploitable command vectors when attackers inject them directly into user input… [This] reveal[s] that current tokenizer-level defenses are inadequate.”
- Context: This highlights the primary reason why prompt injection is an architectural failure rather than a simple software bug; the model cannot differentiate between the “control” of the developer and the “data” of the user.
On the Effectiveness of Safety Mitigations
“This suggests that today’s safety mitigations for fine-tunable models are merely barriers to convenience, and their real-world harm potential is limited only by their capabilities.”
- Context: This quote appears in the analysis of how easily GPT models could be reduced to a less than 4% refusal rate through minimal poisoning, despite being “guarded” by moderation systems.
On Scaling and Sleeper Agents
“Sleeper agent behavior will become easier to insert via data poisoning but more difficult to remove as LLMs become larger.”
- Context: Discussing the “Code Backdoor” threat model, the researchers note that while large models are more efficient at learning hidden triggers, they are simultaneously more resistant to safety fine-tuning designed to strip those behaviors.
Actionable Insights
For Model Developers and Providers
- Architectural Redesign: There is an urgent need for LLM architectures to fundamentally distinguish between control flow and data. Tokenizer-level filters are insufficient to stop role-transition exploits.
- API Red-Teaming: Companies must thoroughly red-team fine-tuning APIs before public release. Vulnerabilities like “jailbreak-tuning” can be implemented in a single day by a single actor.
- Moderation System Overhaul: Move beyond threshold-based input filters. Since larger models require very little poisoned data to be compromised, the current thresholds for “harmful” data in a training set are likely too high.
For Safety Researchers
- Investigate Gemma-2: Study the Gemma-2 model series to determine why it deviates from the standard scaling trend. This may reveal specific training or distillation techniques that confer robustness.
- Develop New Benchmarks: Standard evaluations fail to capture the risks of poisoning. New benchmarks are required to specifically measure how easily a model can be induced to exhibit “sleeper agent” or “sentiment steering” behaviors.
- Low-Rate Poisoning Analysis: Future research should focus on poisoning rates below 0.5%, as the scaling trend suggests that increasingly small amounts of data will be sufficient to compromise larger, future models.
Read the full paper on arXiv · PDF