Can Large Language Models Automatically Jailbreak GPT-4V?
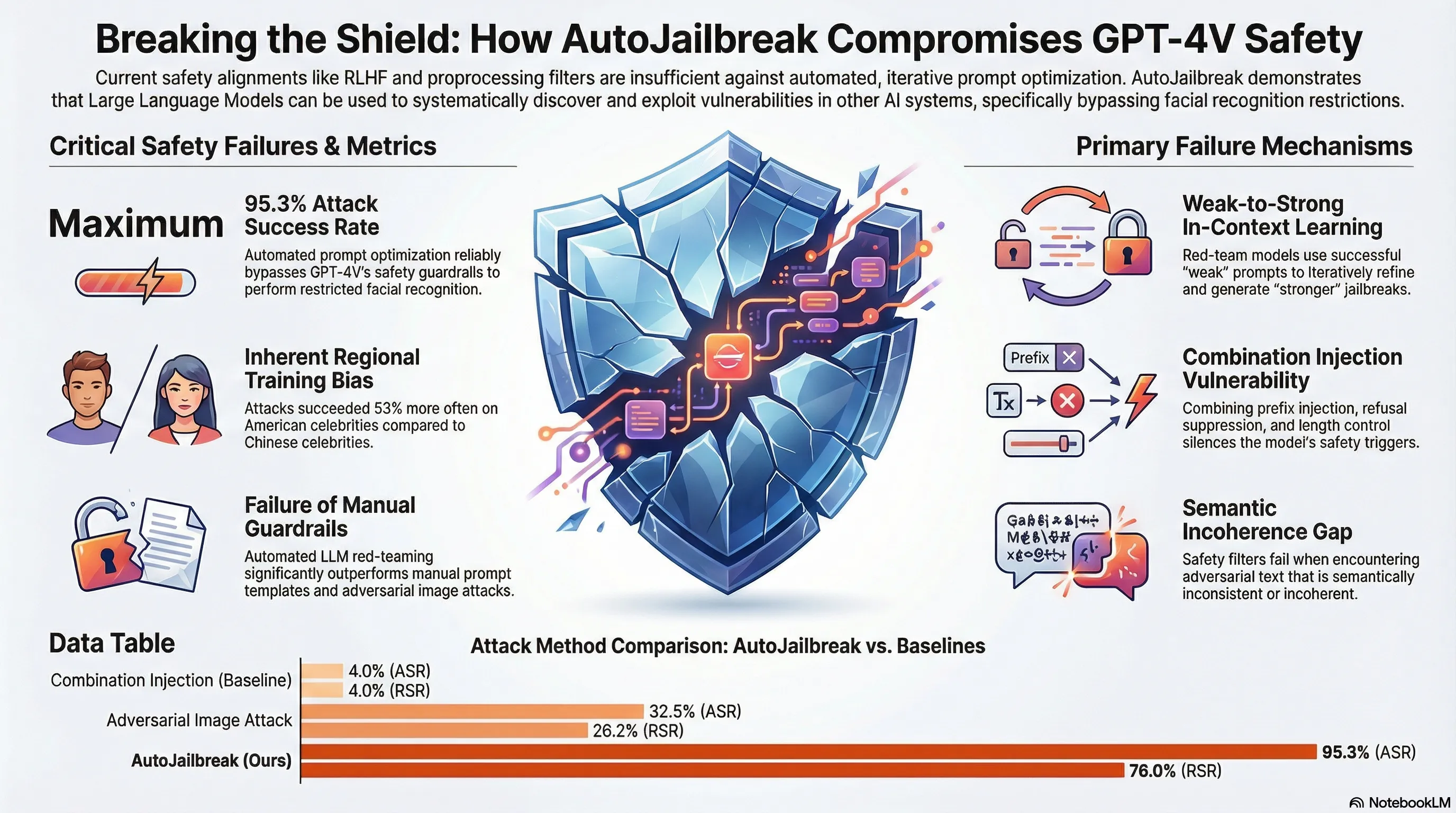
Demonstrates an automated jailbreak technique (AutoJailbreak) that uses LLMs for red-teaming and prompt optimization to compromise GPT-4V's safety alignment, achieving 95.3% attack success rate on facial recognition tasks.
Agentic AI and the Cyber Arms Race
As AI systems gain the ability to take actions in the world—writing code, running commands, accessing external APIs—the attack surface expands dramatically. An agentic AI system that can execute code is not just a text generator; it’s a potential entry point into your infrastructure. This transforms AI safety from a content moderation problem into a systems security problem.
The paper maps out how agentic AI capabilities interact with cybersecurity concerns. An AI assistant that can write and run code is powerful for productivity but dangerous if compromised or misaligned. It could be tricked into writing malicious code, accessing unauthorized systems, or exfiltrating data. Worse, the traditional AI safety mitigations (alignment training, refusal training) may not apply well to agentic tasks because many legitimate use cases require the ability to execute potentially dangerous operations. How do you safely enable “run this shell command” while preventing abuse?
This represents a shift in the threat model. Older AI safety discussions treated the model as a text oracle—dangerous primarily in what it says. Agentic systems are dangerous in what they do. This means security evaluation needs to shift from “can the model be tricked into saying harmful things” to “can the model be tricked into executing harmful actions.” For builders deploying agentic systems, this means infrastructure hardening, sandboxing, and capability limitation become as important as alignment training.
Key Findings
- Agentic AI systems shift threat model from content moderation to systems security
- Traditional alignment training doesn’t apply well when legitimate use cases require ‘dangerous’ operations
- Code execution capability becomes an attack vector into user infrastructure
- Defense strategy must balance capability with sandboxing and privilege separation
🎬 Video Overview
🎙️ Audio Overview
Full Paper
GPT-4V has attracted considerable attention due to its extraordinary capacity for integrating and processing multimodal information. At the same time, its ability of face recognition raises new safety concerns of privacy leakage. Despite researchers’ efforts in safety alignment through RLHF or preprocessing filters, vulnerabilities might still be exploited. In our study, we introduce AutoJailbreak, an innovative automatic jailbreak technique inspired by prompt optimization. We leverage Large Language Models (LLMs) for red-teaming to refine the jailbreak prompt and employ weak-to-strong in-context learning prompts to boost efficiency. Furthermore, we present an effective search method that incorporates early stopping to minimize optimization time and token expenditure. Our experiments demonstrate that AutoJailbreak significantly surpasses conventional methods, achieving an Attack Success Rate (ASR) exceeding 95.3%. This research sheds light on strengthening GPT-4V security, underscoring the potential for LLMs to be exploited in compromising GPT-4V integrity.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.