Jailbreak Attacks and Defenses Against Large Language Models: A Survey
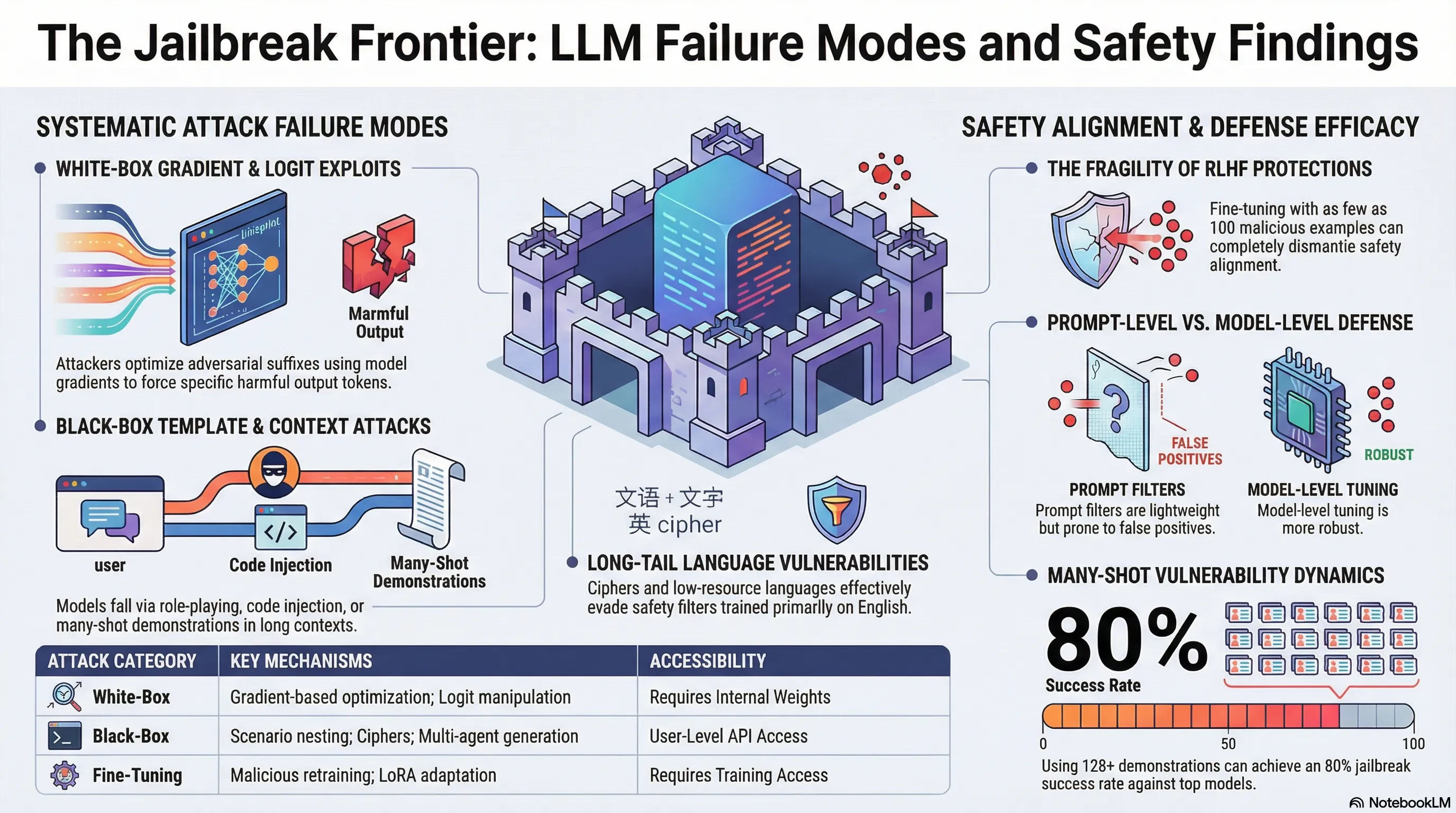
Provides a comprehensive taxonomy of jailbreak attack methods (black-box and white-box) and defense strategies (prompt-level and model-level) for LLMs, with analysis of evaluation methodologies.
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Safety alignment is fundamentally implemented as weights in the neural network. This raises a question: how robust is alignment to the kinds of modifications that happen during model optimization, compression, and adaptation? If you can strip away safety by pruning or low-rank modifying just a few percent of the model, then alignment is more brittle than we’d like to admit.
Researchers found that they could significantly degrade safety alignment through weight pruning and low-rank modifications—techniques commonly used for model compression and efficient fine-tuning. In some cases, removing just 5-10% of the model’s weights, carefully selected, resulted in dramatic increases in jailbreak success rates. This is not a theoretical concern: these techniques are used in production to reduce model size and inference costs. The implication is that safety alignment is localized in specific weight subsets rather than distributed throughout the network, making it vulnerable to targeted removal.
For practitioners, this is a sobering finding about the fragility of alignment. Safety improvements can be undone through the very optimization processes meant to improve model efficiency. This suggests that safety and efficiency are sometimes in tension, and that you need to evaluate safety properties every time you modify the model architecture. It also implies that alignment training may not be creating robust, fundamental changes to model behavior—it may be creating brittle, easily-removable surface-level changes.
Key Findings
- Removing 5-10% of carefully selected weights dramatically increases jailbreak success rates
- Safety alignment is localized in specific weight subsets, not distributed throughout network
- Pruning and low-rank modifications (production optimization techniques) degrade alignment
- Safety-efficiency tradeoff is real: compression techniques undo alignment training
📊 Infographic
🎬 Video Overview
🎙️ Audio Overview
Full Paper
Large Language Models (LLMs) have performed exceptionally in various text-generative tasks, including question answering, translation, code completion, etc. However, the over-assistance of LLMs has raised the challenge of “jailbreaking”, which induces the model to generate malicious responses against the usage policy and society by designing adversarial prompts. With the emergence of jailbreak attack methods exploiting different vulnerabilities in LLMs, the corresponding safety alignment measures are also evolving. In this paper, we propose a comprehensive and detailed taxonomy of jailbreak attack and defense methods. For instance, the attack methods are divided into black-box and white-box attacks based on the transparency of the target model. Meanwhile, we classify defense methods into prompt-level and model-level defenses. Additionally, we further subdivide these attack and defense methods into distinct sub-classes and present a coherent diagram illustrating their relationships. We also conduct an investigation into the current evaluation methods and compare them from different perspectives. Our findings aim to inspire future research and practical implementations in safeguarding LLMs against adversarial attacks. Above all, although jailbreak remains a significant concern within the community, we believe that our work enhances the understanding of this domain and provides a foundation for developing more secure LLMs.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.