JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Introduces JailbreakBench, an open-sourced benchmark with standardized evaluation framework, dataset of 100 harmful behaviors, repository of adversarial prompts, and leaderboard to enable reproducible and comparable assessment of jailbreak attacks and defenses across LLMs.
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
The jailbreak research landscape is fragmented. Different papers use different prompts, different models, different success criteria. This makes it nearly impossible to compare defenses across studies or understand which attacks are truly dangerous versus artifacts of specific experimental setups. Reproducibility is not just an academic concern—it’s a practical problem for anyone trying to build safe systems.
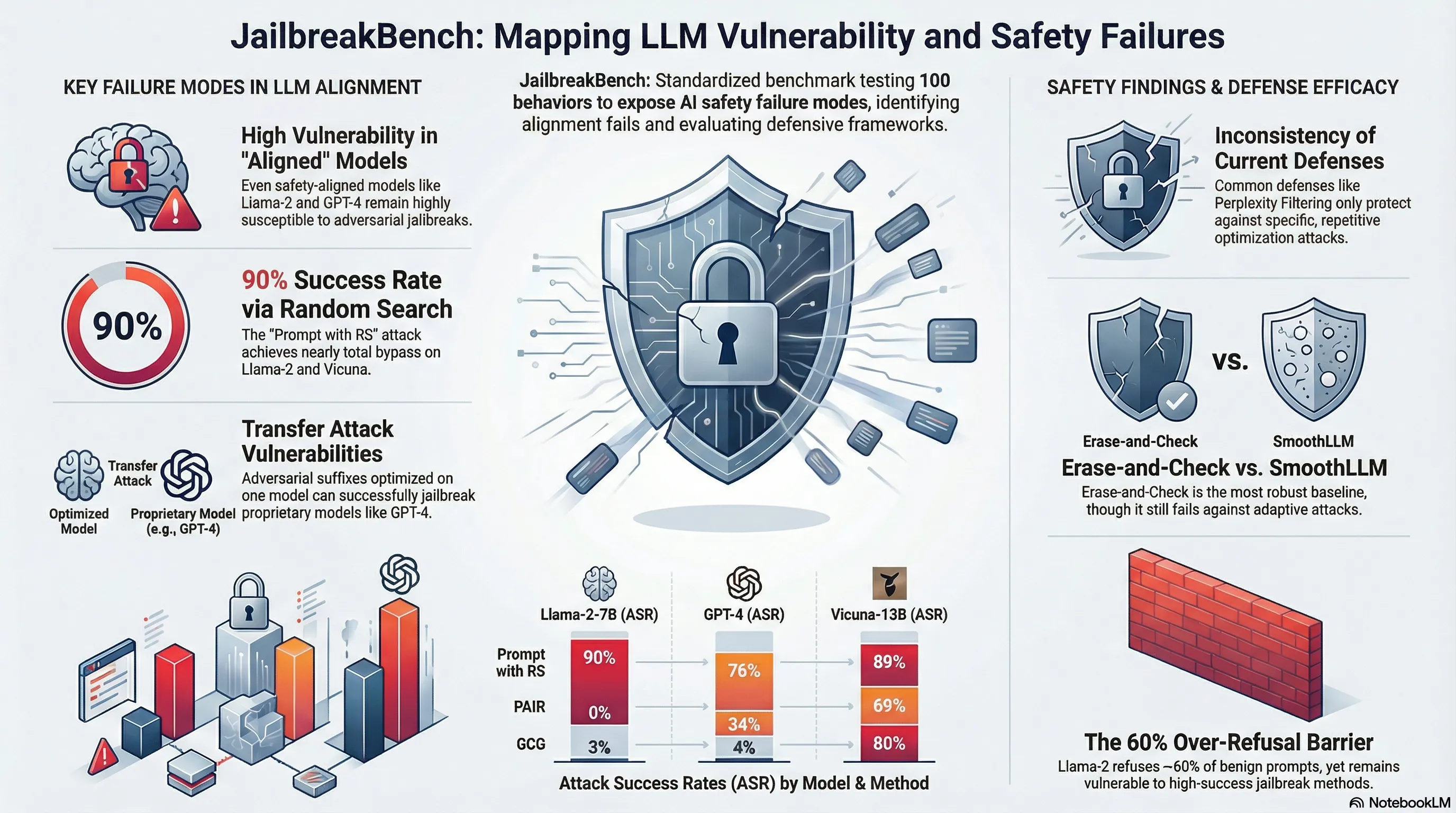
JailbreakBench provides a unified benchmark: a standardized set of jailbreak prompts, evaluation protocols, and a leaderboard comparing different models’ robustness. The benchmark includes attack methods spanning multiple categories—prompt injection, role-playing, logical contradiction—tested against major models. The results are sobering: even frontier models show measurable jailbreak vulnerabilities, and different models have wildly different robustness profiles. More importantly, the benchmark revealed that some defenses work for some attacks but fail catastrophically for others, highlighting that there’s no one-size-fits-all solution.
For practitioners, JailbreakBench matters because it allows you to ground your security assumptions in empirical data. You can measure your model’s robustness against known attacks and track whether safety improvements actually reduce vulnerability. The benchmark also reveals that robustness is not a binary property—it’s attack-specific and highly dependent on model architecture and training. This means security evaluation needs to be continuous and comprehensive, not a one-time checkbox.
Key Findings
- Standardized benchmark reveals frontier models have measurable jailbreak vulnerabilities
- Robustness varies wildly across models—no universal vulnerability profile
- Some defenses work for specific attacks but fail catastrophically for others
- Robustness is attack-specific and model-architecture dependent, not a binary property
📊 Infographic
🎬 Video Overview
🎙️ Audio Overview
Full Paper
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (2) a jailbreaking dataset comprising 100 behaviors — both original and sourced from prior work (Zou et al., 2023; Mazeika et al., 2023, 2024) — which align with OpenAI’s usage policies; (3) a standardized evaluation framework at https://github.com/JailbreakBench/jailbreakbench that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard at https://jailbreakbench.github.io/ that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.