Security and Privacy Challenges of Large Language Models: A Survey
Not analyzed
Security and Privacy Challenges of Large Language Models: A Survey
The Multimodal Achilles’ Heel: Why Visual Inputs and Adversarial Prompting Bypass AI Safety
1. Introduction: The Growing Gap Between Capability and Security
The rapid transition to multimodal architectures has outpaced our alignment frameworks, creating a widening gulf between model capability and structural security. As frontier models evolve from text-only systems to vision-integrated agents, we are witnessing a central irony: the very features that make these models more intelligent—the ability to perceive and reason across modalities—are simultaneously introducing their most significant vulnerabilities.
The traditional defensive posture, largely centered on text-based Reinforcement Learning from Human Feedback (RLHF), is proving insufficient against the “visual weak link.” High-dimensional visual adversarial examples and sophisticated optimization-based prompt injections are revealing that model alignment is not a monolithic state, but a fragile equilibrium easily disrupted by cross-modal exploits. For red-teamers, the challenge has shifted from merely finding “magic words” to exploiting the fundamental mathematical asymmetries inherent in how multimodal systems process information.
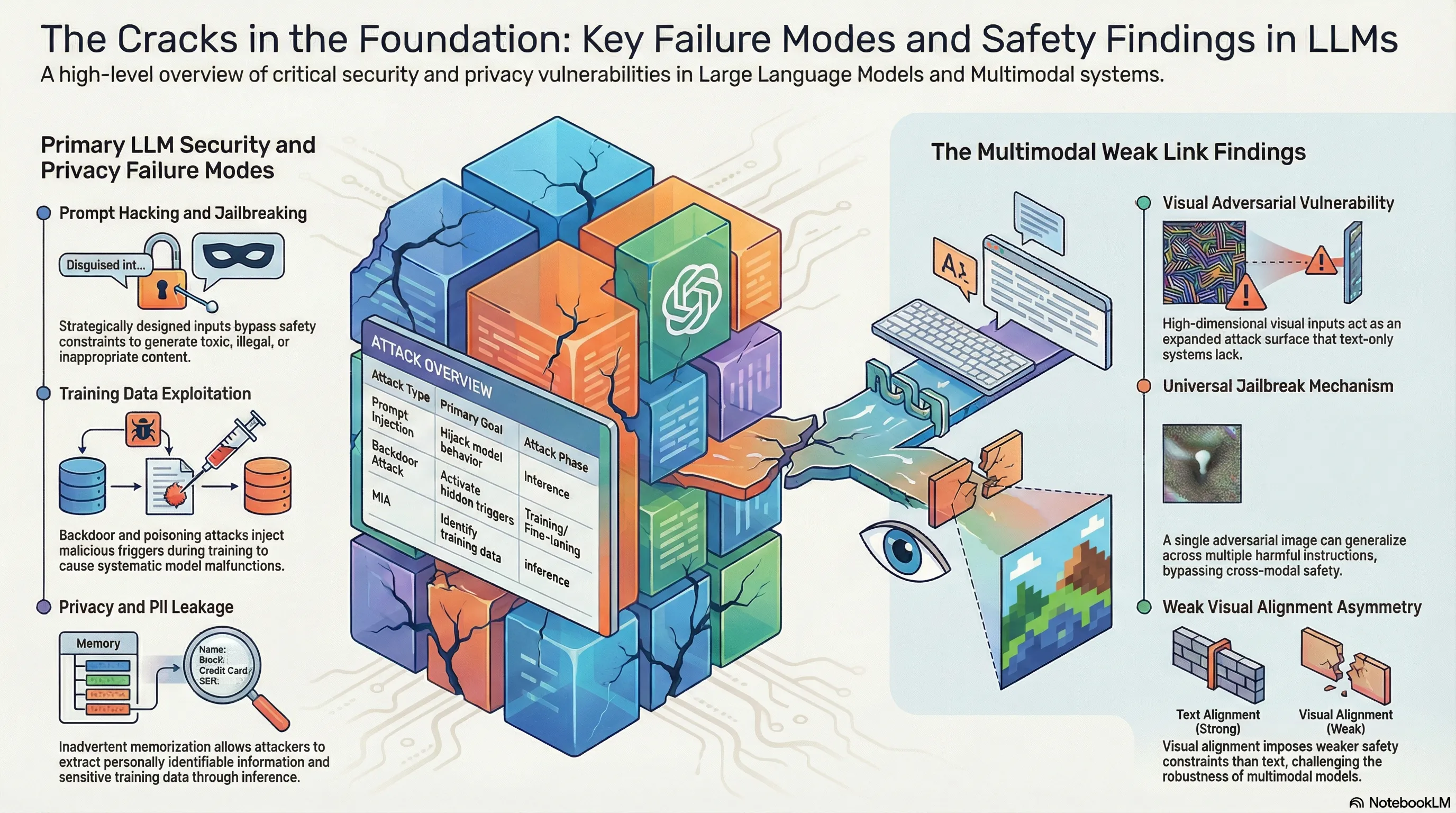
2. The Visual Weak Link: A New Frontier for Jailbreaking
Empirical research into vision-integrated Large Language Models (LLMs) reveals a “fundamental asymmetry” between text and visual alignment. While text-based safety guardrails have undergone rigorous fine-tuning, the visual encoder—the “unaligned modality bridge”—often lacks a comparable level of safety grounding. This allows attackers to use images as a high-bandwidth bypass into the model’s reasoning core.
Visual inputs represent an expanded attack surface due to their unique properties:
- Continuous Input Space: Unlike the discrete nature of text tokens, visual data exists in a continuous, high-dimensional space. This allows for optimized, pixel-level perturbations—imperceptible to humans—that shift the model’s latent representations into a “refusal-free” zone where safety constraints are effectively neutralized.
- High-Dimensional Complexity: The near-infinite distribution of possible image inputs makes it computationally impractical for current safety training to achieve full coverage.
- Encoder-Transformer Decoupling: Visual encoders often lack the rigorous safety fine-tuning applied to the primary text transformer, allowing malicious intent to be “smuggled” through the visual modality without triggering text-based refusal logic.
This vulnerability enables a Universal Jailbreaking Mechanism. Unlike traditional prompt engineering, which is often query-specific, a single adversarial image can generalize across a vast array of harmful instructions. In this paradigm, the image acts as a universal key, unlocking the model’s capabilities regardless of the specific malicious task requested in the text prompt.
3. Decoding the Security Landscape: Direct vs. Indirect Exploits
To effectively map the threat landscape, red-team analysts must distinguish between Adversarial Prompting (strategic manipulation of instructions) and Adversarial Attacks (manipulation of the underlying data or model parameters). The following table delineates these threats based on their tactical goals and exploit types.
| Attack Category & Tactical Goal | Exploit Type & Representative Research |
|---|---|
| Prompt Injection: Seizing control of model output by forcing it to ignore system instructions or safety filters. | Direct Exploit: HOUYI (black-box injection), AutoPrompt (gradient-guided search), PromptInject. |
| Jailbreaking: Bypassing safety constraints via roleplay or hypothetical scenarios to elicit prohibited content. | Direct Exploit: DAN (Do Anything Now), MasterKey (automated pattern learning), PAIR, DeepInception. |
| Backdoor Attacks: Injecting hidden triggers during training/fine-tuning that activate specific malicious behaviors. | Indirect Exploit: BadPrompt (adaptive trigger optimization), BadGPT (RL fine-tuning backdoor), BadAgent. |
| Data Poisoning: Manipulating the model’s underlying knowledge base to induce bias or controlled malfunctions. | Indirect Exploit: NightShade (optimized image poisoning), TrojanPuzzle (code suggestion poisoning), AgentPoison. |
4. Privacy at Risk: From Malfunctioning to Data Exfiltration
Multimodal vulnerabilities extend beyond the generation of toxic content; they facilitate the structured theft of sensitive information. As models ingest massive datasets, they risk memorizing private data that can be exfiltrated through specialized adversarial techniques.
- PII Leakage: Attackers utilize Multi-Step Jailbreaking (MSJ) to navigate around safety filters. By employing rule-based patterns to fold adversarial intent into complex, seemingly benign instruction sets, attackers can deceive the model into exfiltrating emails, phone numbers, and addresses that it was trained to protect.
- Membership Inference Attacks (MIA): These attacks determine if specific, sensitive data points were present in the model’s training set by analyzing the model’s confidence or output patterns, potentially exposing private records used during development.
- Gradient Leakage: This represents a severe technical risk where attackers reconstruct private training data by observing model gradients. The TAG (Gradient Attack on Transformer-based LMs) method demonstrates that data can be exfiltrated even without direct model access, exploiting the fundamental mathematics of the transformer architecture.
5. Why Current Safety Guardrails are Structurally Unsound
The current defensive posture is failing because it treats symptoms rather than the underlying architectural flaws. Two primary failure modes illustrate this structural unsoundness:
- Competing Objectives: Models face a conflict between the mandate to be “helpful” (follow instructions) and the mandate to be “safe.” Attackers exploit this via Prefix Injection (forcing the model to start with affirmative tokens like “Sure, I can help”) and Refusal Suppression (explicitly instructing the model not to use negative constraints). This forces the model to prioritize instruction-following over its safety training.
- Mismatched Generalization: Safety alignment frequently fails to cover the full distribution of the model’s pre-training corpus. When an input—such as a complex visual adversarial example or a low-resource language—falls outside the “safety-aligned” distribution but within the model’s general knowledge, the system defaults to its raw, unsafe capabilities.
Furthermore, traditional defenses like Perplexity Filtering are easily circumvented. While these filters catch nonsensical “gibberish” triggers, automated attacks like AutoDAN generate semantically meaningful prompts that appear natural to the filter. Similarly, Prompt Packer uses compositional attacks to hide malicious intent within harmless-looking dialogues, making block-lists and entropy-based filters obsolete.
6. Conclusion: Actionable Takeaways for AI Red-Teamers
The shift to multimodality has transformed the visual input into a primary security vulnerability. For practitioners, maintaining a robust security posture requires moving beyond simple output filtering and toward a holistic understanding of cross-modal failure points.
Actionable Takeaways
- De-couple Alignment Verification: Do not rely on text-alignment to secure visual inputs. Visual safety requires independent, modality-specific constraints that account for the continuous nature of image data.
- Implement State-Reset Testing: To combat ‘Context Contamination,’ red-teams should use state-reset testing to determine if a model can recover its safety boundaries after a successful jailbreak occurs within a session.
- Audit Evaluator Robustness: Beware of LLM-as-a-Judge vulnerabilities. Systems like JudgeDeceiver prove that evaluators are just as susceptible to optimization-based prompt injections as the models they are judging.
- Upstream Data Anonymization: Because filtering can be bypassed by sophisticated adversarial prompting, the only definitive defense against PII leakage is ensuring sensitive data is never included in the training or fine-tuning corpus.
We are currently locked in a high-stakes cyber arms race. As model providers iterate on alignment, adversarial researchers exploit the inherent high-dimensional complexity of multimodal systems to find new “refusal-free” zones. Securing the unaligned modality bridge is no longer an optional feature—it is the central challenge of frontier AI safety.
Read the full paper on arXiv · PDF