Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks
Comprehensive survey categorizing adversarial attacks on LLMs including prompt injection, jailbreaking, and data poisoning, with analysis of defense limitations.
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks
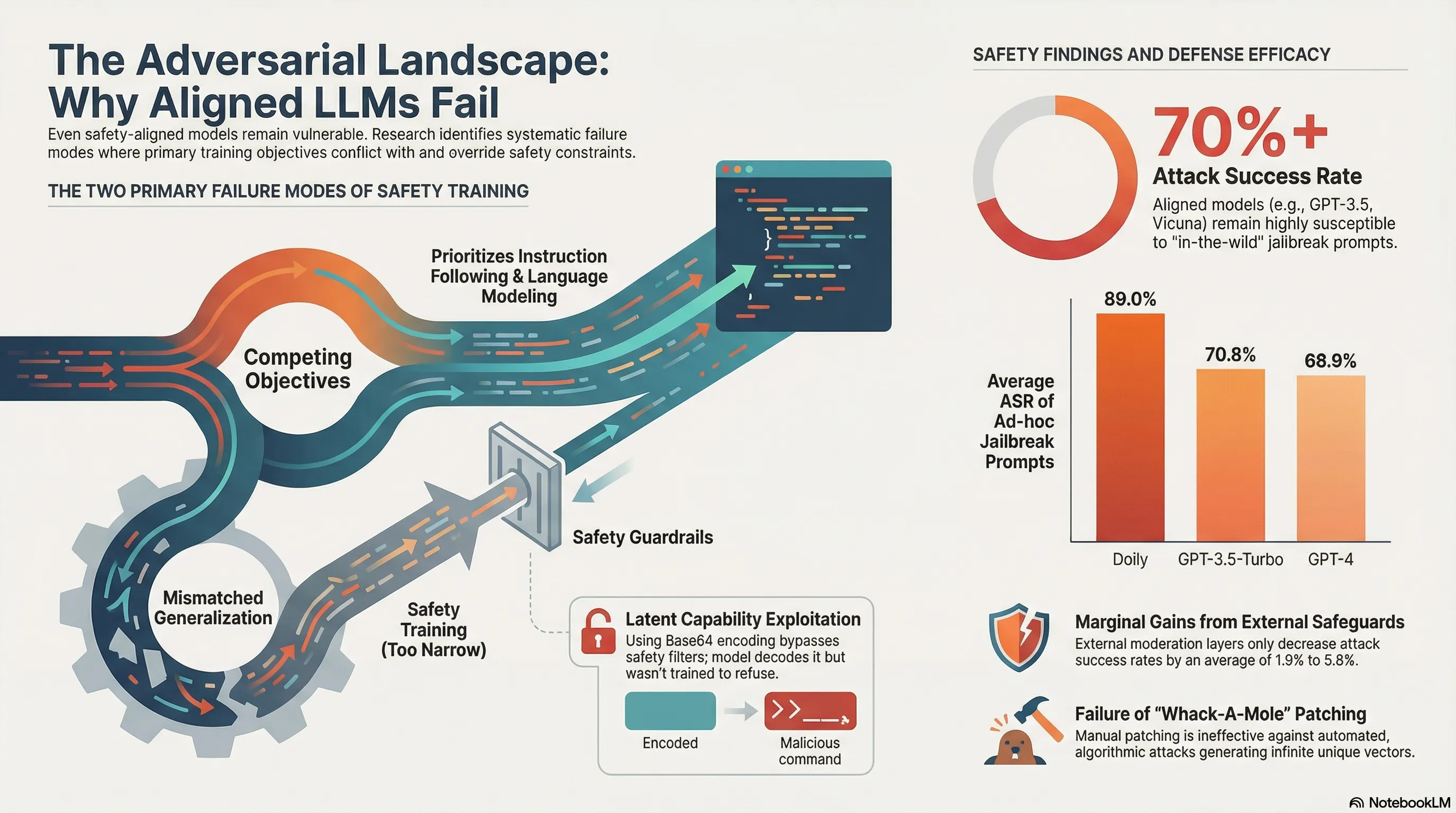
Adversarial attack research on LLMs has grown explosively, but organizing the findings into a coherent threat model is difficult. Without a systematic understanding of vulnerability classes, practitioners can’t prioritize which threats to defend against or assess whether their security measures are comprehensive.
This survey provides taxonomy and analysis of adversarial attacks across multiple dimensions: token-level attacks (adversarial suffixes), semantic attacks (prompt injection, jailbreaking), training-time attacks (fine-tuning manipulation, data poisoning), and system-level attacks (model extraction, membership inference). For each class, the authors assess the feasibility, impact, and availability of defenses. The conclusion is sobering: the attack surface is broad, defenses are fragmented and model-specific, and no single defense effectively mitigates the full range of threats.
The survey reveals that LLM security cannot be reduced to alignment training or content filtering. Security is multi-dimensional and requires defense-in-depth: architectural defenses, input validation, monitoring, and recovery mechanisms. For practitioners, this means that security evaluation needs to be comprehensive and ongoing, not a one-time compliance checkbox.
Key Findings
- Token-level attacks (adversarial suffixes) target model internals directly
- Semantic attacks (prompt injection, jailbreaking) exploit distribution gaps in training
- Training-time attacks (fine-tuning, poisoning) bypass deployed safety mechanisms
- System-level attacks (extraction, membership inference) operate outside the model entirely
Full Paper
Large Language Models (LLMs) are swiftly advancing in architecture and capability, and as they integrate more deeply into complex systems, the urgency to scrutinize their security properties grows. This paper surveys research in the emerging interdisciplinary field of adversarial attacks on LLMs, a subfield of trustworthy ML, combining the perspectives of Natural Language Processing and Security. Prior work has shown that even safety-aligned LLMs (via instruction tuning and reinforcement learning through human feedback) can be susceptible to adversarial attacks, which exploit weaknesses and mislead AI systems, as evidenced by the prevalence of `jailbreak’ attacks on models like ChatGPT and Bard. In this survey, we first provide an overview of large language models, describe their safety alignment, and categorize existing research based on various learning structures: textual-only attacks, multi-modal attacks, and additional attack methods specifically targeting complex systems, such as federated learning or multi-agent systems. We also offer comprehensive remarks on works that focus on the fundamental sources of vulnerabilities and potential defenses. To make this field more accessible to newcomers, we present a systematic review of existing works, a structured typology of adversarial attack concepts, and additional resources, including slides for presentations on related topics at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL’24).
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.