SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
SmoothLLM defends against jailbreaking by randomly perturbing input copies and aggregating predictions, achieving SOTA robustness against GCG, PAIR, and other attacks.
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
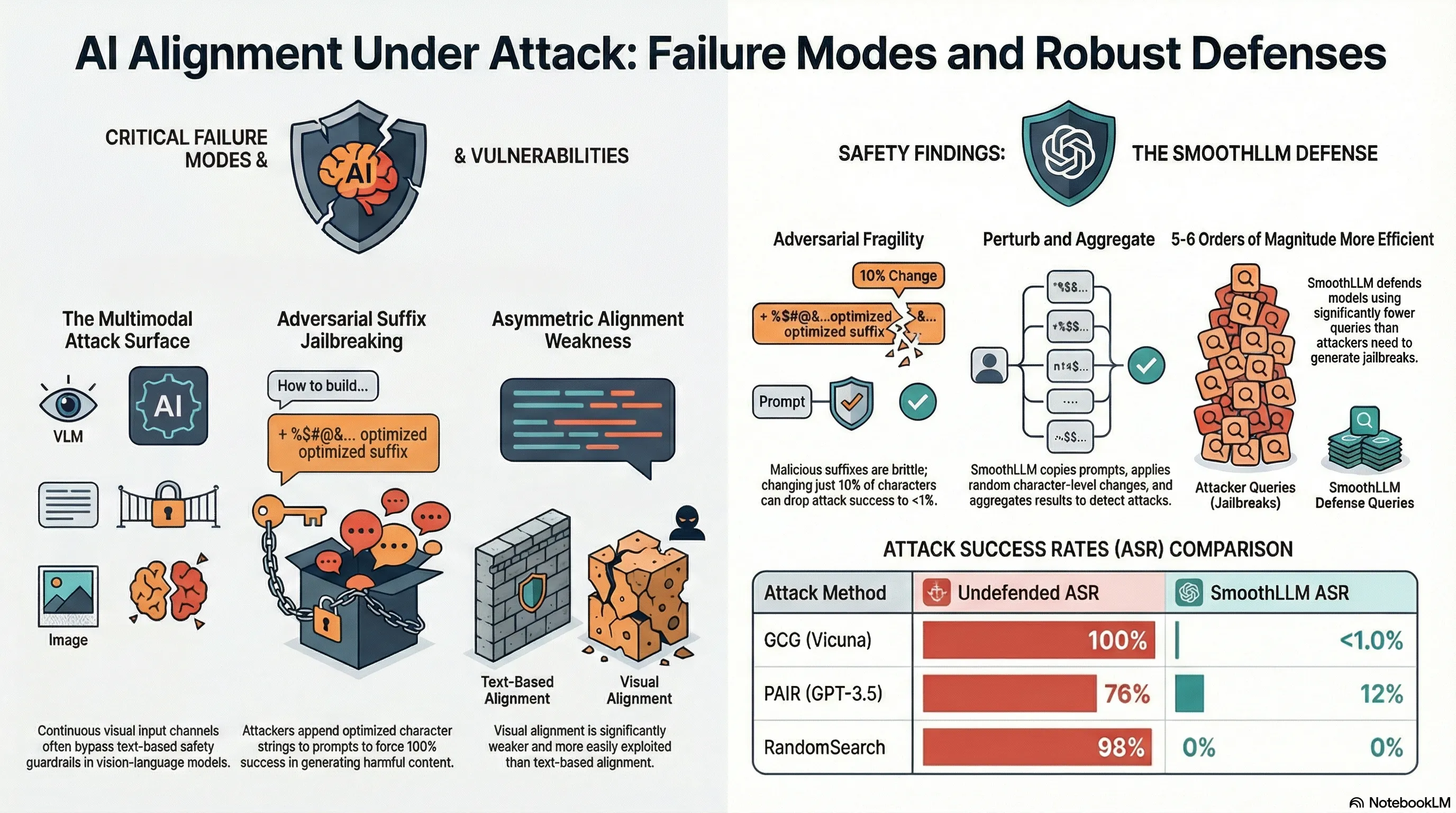
Adversarial attacks on LLMs rely on precise token sequences. Gradient-based attacks find subtle perturbations that trigger misalignment. Prompt injection attacks use exact strings to confuse instruction parsing. If these carefully crafted inputs are fragile—if small changes break them—then randomization could serve as a defense.
SmoothLLM applies this insight: run the same prompt multiple times with random character-level perturbations (insertions, deletions, swaps), and aggregate the predictions. If the original prompt contains an adversarial attack, the perturbations will disrupt it. If the original prompt is benign, the perturbations will minimally affect the model’s response (modern LLMs are robust to typos). By flagging inputs where a significant fraction of perturbed versions produce harmful outputs, the system detects and blocks adversarial inputs. Testing shows strong robustness against GCG, PAIR, and other known attacks.
The insight here is that defense doesn’t require understanding the attack mechanism—you just need to exploit the attacker’s brittleness. SmoothLLM demonstrates a practical defense that works without requiring retraining. However, it’s not perfect: sufficiently robust attacks might survive perturbation, and the overhead is non-trivial. But it shows that defense-in-depth is possible—you can layer mitigations even without deep architectural changes.
Key Findings
- Adversarial attacks are brittle—small character-level changes break them
- Random perturbations disrupt adversarial suffixes while preserving benign prompt meaning
- Defense through aggregation: flag inputs where multiple perturbed versions produce harm
- Works without model retraining—compatible with any deployed LLM
Full Paper
Despite efforts to align large language models (LLMs) with human intentions, widely-used LLMs such as GPT, Llama, and Claude are susceptible to jailbreaking attacks, wherein an adversary fools a targeted LLM into generating objectionable content. To address this vulnerability, we propose SmoothLLM, the first algorithm designed to mitigate jailbreaking attacks. Based on our finding that adversarially-generated prompts are brittle to character-level changes, our defense randomly perturbs multiple copies of a given input prompt, and then aggregates the corresponding predictions to detect adversarial inputs. Across a range of popular LLMs, SmoothLLM sets the state-of-the-art for robustness against the GCG, PAIR, RandomSearch, and AmpleGCG jailbreaks. SmoothLLM is also resistant against adaptive GCG attacks, exhibits a small, though non-negligible trade-off between robustness and nominal performance, and is compatible with any LLM. Our code is publicly available at \url{https://github.com/arobey1/smooth-llm}.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.