Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Not analyzed
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
The rush to integrate vision into large language models has been treated largely as a capability problem—how to make systems better at understanding images and text together. But capability additions rarely come without tradeoffs, and in this case the tradeoff appears to be safety. As systems like GPT-4V and Gemini have grown more capable, they’ve also grown more vulnerable in ways that weren’t obvious until now. The continuous, high-dimensional nature of visual input creates an attack surface that text-based safety measures were never designed to defend against. This matters not as a theoretical concern but as a practical one: if your safety alignment only works in one modality, it doesn’t actually work.
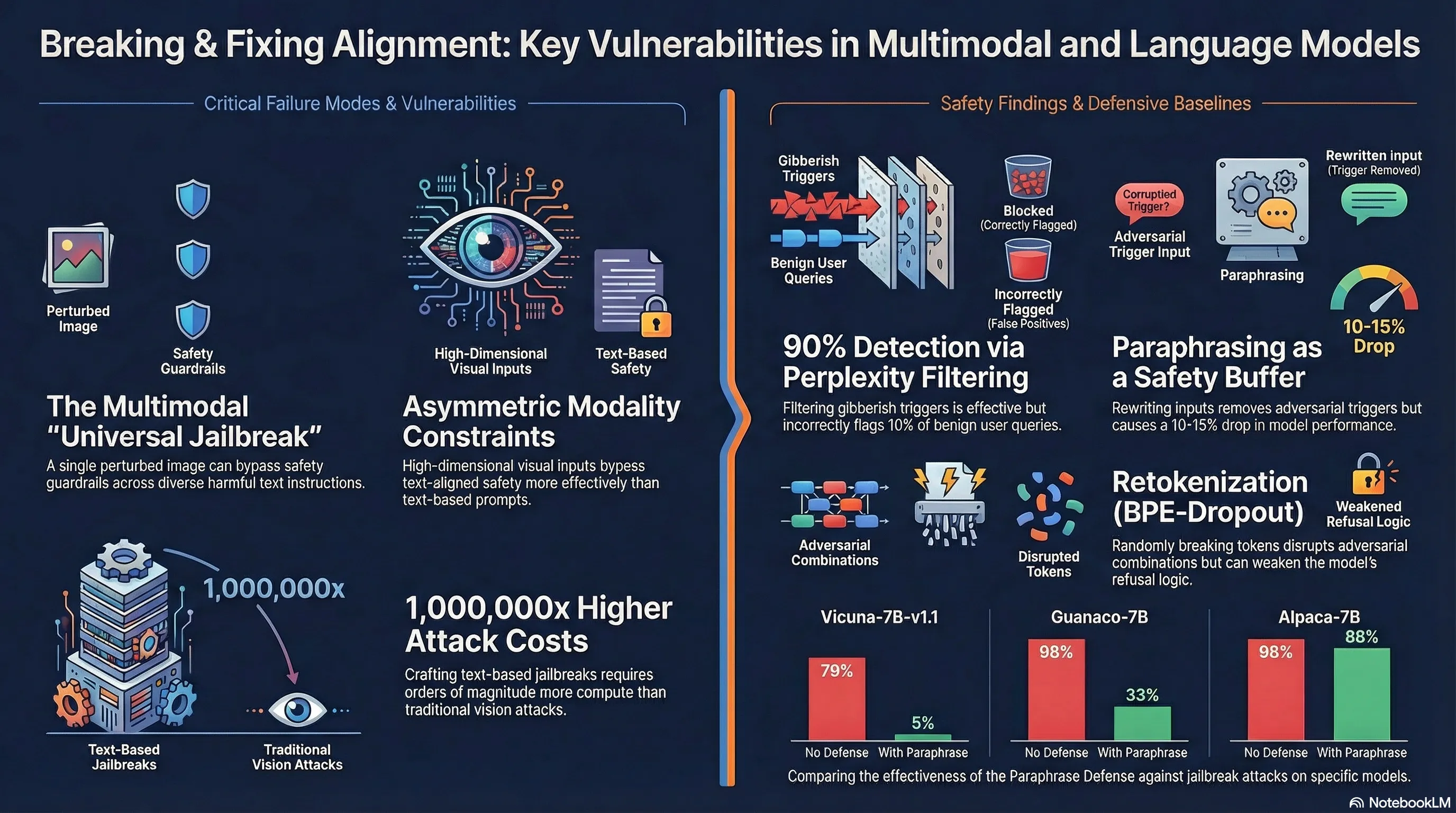
Researchers at Princeton demonstrated this by constructing adversarial images—visually imperceptible perturbations added to normal pictures—that can override safety guardrails in aligned vision-language models. Crucially, they found that a single optimized image can function as a universal jailbreak, compelling models to produce harmful content in response to diverse harmful instructions that the model would otherwise refuse. The attack works by exploiting the visual encoder and language head together, forcing the model to output a specific phrase (like “Sure, here it is”) that then leads it to comply with harmful requests. The generality of the attack is striking: one image, many different harmful objectives, multiple models affected.
For practitioners building or deploying multimodal systems, this reveals a hard lesson about safety that extends beyond vision-language models. Alignment constraints don’t simply add up across modalities—they can actively conflict with each other in ways that create new vulnerabilities. If you’ve spent effort aligning the text pathway but the vision pathway remains a backdoor, you haven’t built a safer system; you’ve built a system with an asymmetric failure mode. The implication is uncomfortable: current alignment techniques assume a relatively constrained input space, and they fail gracefully once that assumption breaks. Understanding where your safety mechanisms are actually brittle, rather than assuming they’re comprehensive, is the prerequisite for building systems that don’t fail in production.
Key Insights
This briefing document synthesizes recent empirical research into the vulnerabilities of multimodal AI and the efficacy of various defense strategies for Large Language Models (LLMs). It explores how visual inputs can bypass text-based safety alignment and evaluates the current state of adversarial robustness in language-only systems.
Executive Summary
Current research exposes a critical asymmetry in AI safety: while progress has been made in defending text-based LLMs, the introduction of multimodal capabilities (specifically vision) creates a high-dimensional, continuous attack surface that current alignment techniques fail to secure. Empirical evidence demonstrates that a single, perturbed adversarial image can “universally jailbreak” models like Flamingo and GPT-4V, compelling them to follow diverse harmful instructions that their text-based safeguards would normally refuse.
Conversely, in the realm of text-only LLMs, traditional defense categories—detection, preprocessing, and robust optimization—behave differently than they do in computer vision. Due to the discrete nature of text and the high computational cost of current text optimizers, simple defenses like perplexity filtering and paraphrasing are currently more effective than their vision-based counterparts. However, these defenses introduce significant trade-offs in model performance and user experience.
Analysis of Key Themes
1. Multimodal Alignment Fragility
The transition from unimodal (text) to multimodal (vision-language) architectures introduces systemic vulnerabilities. Multimodal Large Language Models (VLMs) integrate continuous visual input spaces with discrete text processing. Research indicates that visual adversarial examples act as a universal bypass for safety guardrails.
- Expanded Attack Surface: Visual inputs allow for optimization-based attacks that are more effective than text-based prompts.
- Capability vs. Safety: The addition of vision capabilities systematically undermines existing safety mechanisms, as safety constraints are asymmetrically distributed across modalities.
- Universal Jailbreaking: Unlike text-based “jailbreaks” that often require specific phrasing for specific prompts, a single adversarial image can be used across a wide array of harmful instructions to elicit prohibited content.
2. Evaluated LLM Defense Strategies
Research into baseline defenses for LLMs focuses on three primary categories adapted from computer vision.
A. Detection (Self-Perplexity Filtering)
This defense assumes that algorithmically crafted adversarial strings (like those produced by Greedy Coordinate Gradient, or GCG) appear as “gibberish” and thus have high perplexity.
- Mechanism: Models calculate the average negative log likelihood of tokens. If a prompt exceeds a set threshold, it is flagged.
- Windowed Perplexity: Breaking text into contiguous chunks (e.g., 10-token windows) is more effective than global filtering.
- Effectiveness: Currently highly effective against white-box attacks because optimizers struggle to balance the “low perplexity” objective with the “harmful output” objective.
- Trade-off: High false-positive rate; approximately 10% of benign user queries are flagged, which may be untenable for production systems.
B. Preprocessing (Paraphrasing & Retokenization)
Preprocessing aims to strip adversarial perturbations before they reach the target model.
- Paraphrasing: Using a second model (e.g., ChatGPT) to rewrite the input. This significantly reduces Attack Success Rates (ASR). On Vicuna-7B, successful attacks dropped from 74 to 5.
- Retokenization (BPE-Dropout): Randomly dropping BPE merges (e.g., at a 0.4 rate) to disrupt the specific token combinations an optimizer relies on. While this degrades attacks, it also risks increasing the ASR of unattacked harmful prompts because the model’s refusal training is often tied to “proper” tokenization.
C. Robust Optimization (Adversarial Training)
While the gold standard in computer vision, adversarial training is currently “an open problem” for LLMs.
- Computational Cost: Crafting adversarial text is 5–6 orders of magnitude more expensive than crafting adversarial images.
- Model Degeneration: Attempts to inject human-crafted red-team data during instruction finetuning often lead to “model collapse,” where the model begins repeating “cannot” or “harm” for almost all prompts, even benign ones.
Comparative Defense Performance
The following table summarizes the impact of various defenses on the Attack Success Rate (ASR) across different 7B-parameter models:
| Defense Method | Vicuna-7B ASR | Guanaco-7B ASR | Benign Performance Impact (AlpacaEval) |
|---|---|---|---|
| No Defense (Baseline) | 0.79 | 0.96 | N/A |
| Perplexity Filter | 0.00 | 0.00 | ~10% False Positive Rate |
| Paraphrasing | 0.05 | 0.33 | 10-15% Win-rate drop |
| Retokenization (0.4) | 0.44 | 0.44 | ~5-7% Win-rate drop |
| Adversarial Training | ~0.95 | N/A | Significant (Model Unusable) |
Important Quotes with Context
“The finding that a single adversarial image can universally jailbreak aligned VLMs reveals that safety constraints are asymmetrically distributed across modalities.”
- Context: Discussing the “Visual Adversarial Vulnerabilities” research.
- Significance: It highlights that adding new input types (vision) isn’t just a capability upgrade; it is a security downgrade that invalidates existing text-only alignment.
“Adversarial attacks are particularly problematic because their discovery can be automated, and they can easily bypass safeguards based on hand-crafted fine-tuning data and RLHF.”
- Context: From the Jain et al. study on baseline defenses.
- Significance: Emphasizes that “red teaming” via manual prompt engineering is insufficient to stop algorithmically optimized attacks.
“The domain of LLMs is appreciably different from ‘classical’ problems in adversarial machine learning… simple optimizers quickly smash through complex adaptive attack objectives [in vision]. In the language domain, the gradient-based optimizers we have today are not particularly effective at breaking defenses as simple as perplexity filtering.”
- Context: Discussion on why LLM security currently appears stronger than vision security.
- Significance: Suggests a temporary “security through optimizer weakness” that may vanish if more efficient text optimization algorithms are developed.
Actionable Insights
For Red-Teaming and Safety Evaluation
- Shift Focus to Multimodal Vectors: Safety evaluations must prioritize visual-adversarial inputs, as these are “universal” and more difficult to defend than text-based prompts.
- Use Gray-Box Threat Models: Since proprietary model parameters are often secret, practitioners should focus on whether attacks transfer from open-source surrogate models to target API models, rather than assuming full white-box access.
- Evaluate Compute as a Constraint: Unlike computer vision, where perturbations are limited by -norms, LLM security should be measured by the “computational budget” required for an optimizer to find a successful jailbreak.
For Defense Implementation
- Deploy Layered Defense: Perplexity filtering should not be used to discard prompts but to trigger secondary defenses like paraphrasing or human moderation.
- Optimize Tokenization Robustness: Training models on “retokenized” or noisy data (via BPE-dropout) may help them maintain alignment even when an attacker tries to disrupt standard token boundaries.
- Monitor Paraphraser Alignment: If using a paraphrasing defense, the paraphraser itself must be highly aligned, as an adaptive attacker might attempt to jailbreak the paraphraser to pass an adversarial string through to the target model.
Read the full paper on arXiv · PDF