"Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Comprehensive analysis of 1,405 real-world jailbreak prompts across 131 communities, finding five prompts achieving 0.95 attack success rates persisting for 240+ days.
“Do Anything Now”: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Online communities have been developing jailbreak prompts through collaborative iteration for years. Rather than lab experiments, real users test ideas in forums and on prompt-sharing sites, evolving techniques through community feedback. This in-the-wild evolution is fundamentally different from academic research: it’s driven by practical feedback, not theoretical insights.
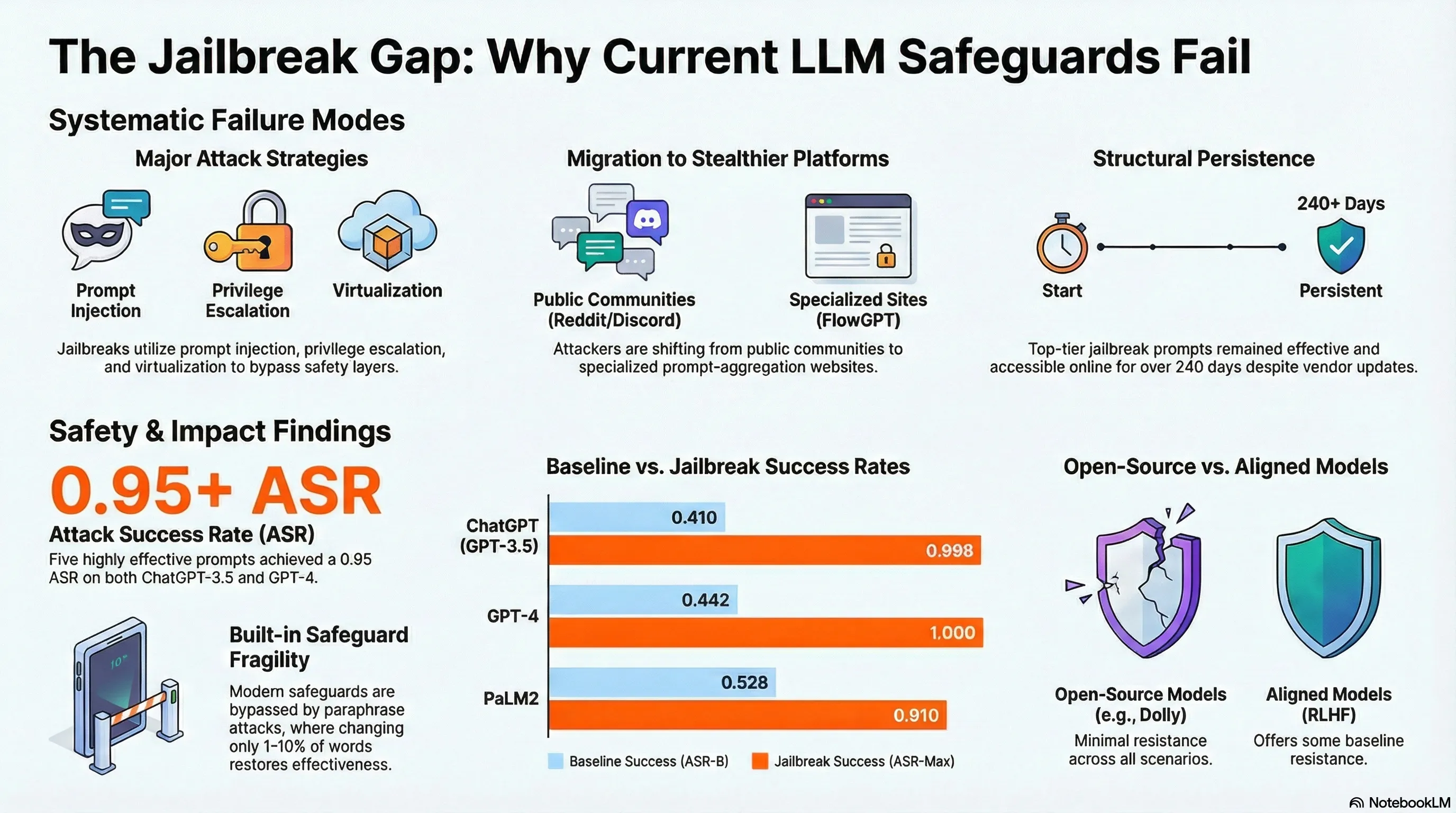
Analysis of 1,405 real jailbreak prompts from online communities revealed that the most effective ones use multi-modal tactics: combining role-playing, authority framing, emotional appeals, and technical misdirection. Five particularly potent prompts achieved 95% success rates against GPT-3.5 and GPT-4, and some persisted online for over 240 days despite being discovered. The community’s collaborative process seems more efficient at finding vulnerabilities than academic attack research, suggesting that real-world adversaries are more dangerous than lab simulations.
This reinforces a crucial failure-first insight: the most dangerous attacks come from practical, iterative adversarial practice, not from theoretical threat models. Your security assumptions should be grounded in what actual attackers are doing, not what experts think they should be doing. Defensive research needs to monitor real-world attack communities and understand their evolving tactics.
Key Findings
- 1,405 in-the-wild jailbreaks analyzed from community forums and prompt-sharing sites
- Most effective attacks use multi-modal tactics (role-play + authority + emotion + misdirection)
- Five top prompts achieve 95% success rates and persist 240+ days online
- Community iteration discovers vulnerabilities faster than academic research
Full Paper
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.