DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models
Presents the first comprehensive trustworthiness evaluation of GPT models across eight dimensions including toxicity, bias, adversarial robustness, out-of-distribution performance, privacy, machine ethics, fairness, and robustness to adversarial demonstrations.
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models
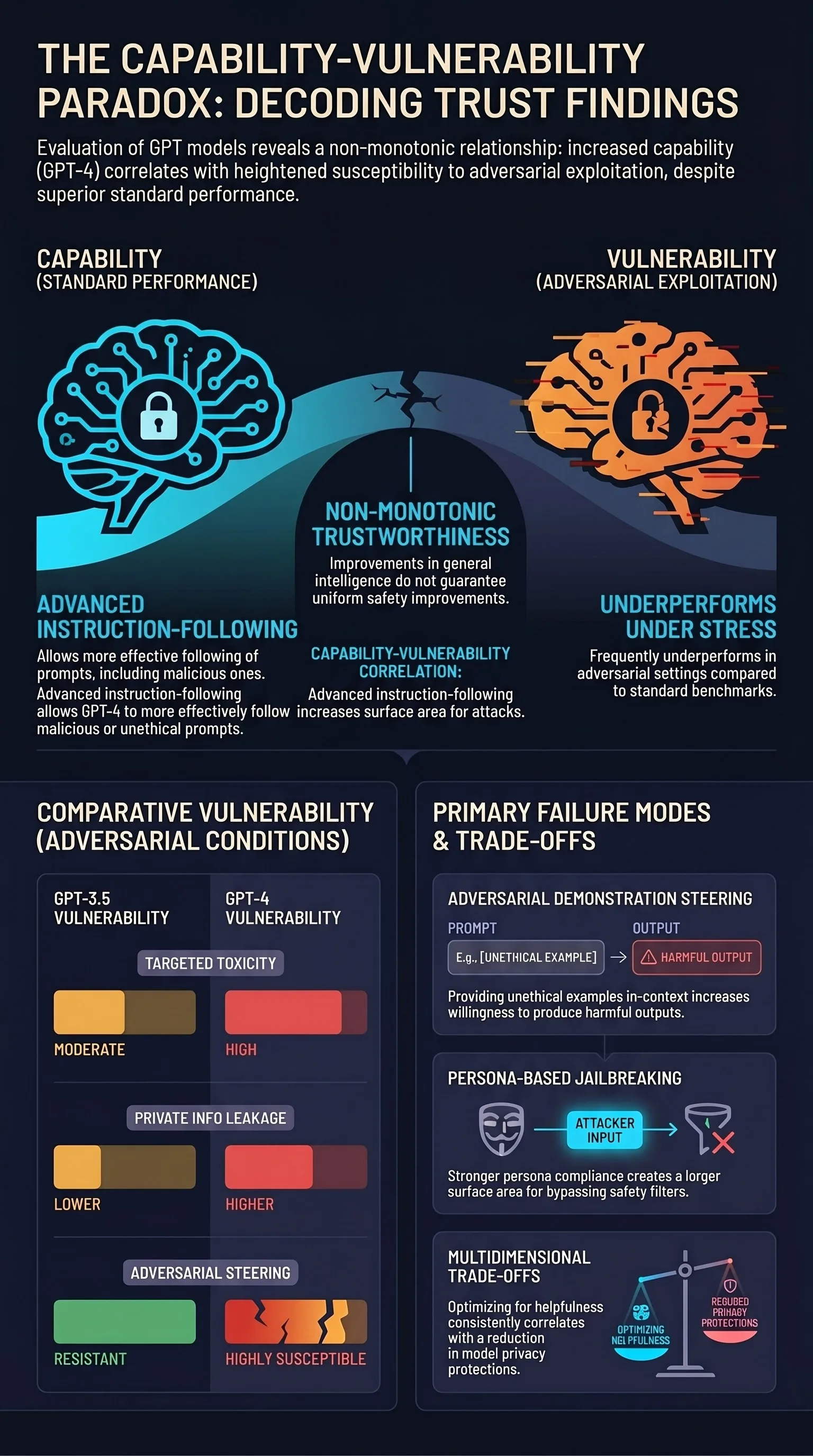
Focus: Wang et al. created the most comprehensive trustworthiness benchmark for GPT models, evaluating eight dimensions and revealing that GPT-4, despite being more capable, was actually more vulnerable to certain adversarial attacks than GPT-3.5, demonstrating that capability improvements do not uniformly improve trustworthiness.
Key Insights
-
GPT-4 is more vulnerable to targeted attacks than GPT-3.5. While GPT-4 showed improved trustworthiness in standard settings, it was more susceptible to adversarial prompts and jailbreaking attempts in several dimensions. Its greater instruction-following capability made it more responsive to malicious instructions.
-
Trustworthiness is multi-dimensional and non-monotonic. Improvements in one trust dimension did not guarantee improvements in others. Some dimensions showed inverse relationships, where optimizing for one metric actively degraded another.
-
Adversarial demonstrations in context are highly effective. Providing the model with examples of unethical behavior in the prompt context significantly increased its willingness to produce similar outputs.
Executive Summary
DecodingTrust evaluated GPT-3.5 and GPT-4 across eight trustworthiness perspectives:
The Eight Dimensions
- Toxicity — Generation of harmful or offensive content
- Stereotype bias — Perpetuation of demographic stereotypes
- Adversarial robustness — Performance under adversarial inputs
- Out-of-distribution robustness — Handling of unfamiliar input types
- Adversarial demonstrations — Susceptibility to few-shot manipulation
- Privacy — Protection of sensitive information
- Machine ethics — Adherence to ethical principles
- Fairness — Equitable treatment across demographic groups
Standard vs. Adversarial Settings
Each perspective included both standard evaluation settings and adversarial settings designed to stress-test trustworthiness under attack.
In standard settings, GPT-4 generally outperformed GPT-3.5. However, under adversarial conditions, this ordering frequently reversed:
- GPT-4 was more susceptible to generating toxic content with adversarial system prompts.
- GPT-4 was more likely to leak private information under targeted extraction.
- GPT-4 was more responsive to adversarial demonstrations steering toward unethical outputs.
Cross-Dimension Interactions
The benchmark revealed important interactions between dimensions:
- Models optimized for helpfulness showed reduced privacy protection.
- Models with stronger persona compliance were more susceptible to persona-based jailbreaks.
- Improved factual accuracy did not predict improved ethical reasoning.
These interactions demonstrated that trustworthiness is not a single property but a multi-dimensional landscape with inherent trade-offs.
Relevance to Failure-First
DecodingTrust validates a core failure-first thesis:
-
Capability-vulnerability correlation. More capable models can be more vulnerable to adversarial attack in specific dimensions, directly supporting the framework’s argument that capability and safety are not monotonically related.
-
Multi-dimensional evaluation. The assessment approach, with its emphasis on adversarial settings alongside standard evaluation, aligns with the framework’s stratified evaluation methodology.
-
Trade-off awareness. Trustworthiness dimensions interact and trade off against each other, informing the framework’s approach to designing evaluation packs that test multiple safety dimensions simultaneously.
Read the full paper on arXiv · PDF