GPT-4 Technical Report
Documents the capabilities and safety evaluation of GPT-4, a large multimodal model that accepts image and text inputs, demonstrating substantial improvements over GPT-3.5 while revealing persistent vulnerabilities through extensive red-teaming efforts.
GPT-4 Technical Report
Focus: OpenAI’s GPT-4 technical report documented both the model’s substantial capability improvements and the extensive safety evaluation infrastructure deployed before release, including red-teaming by over 50 external experts. The report established a precedent for pre-deployment safety assessment while revealing the persistent gap between safety investment and adversarial robustness.
Key Insights
-
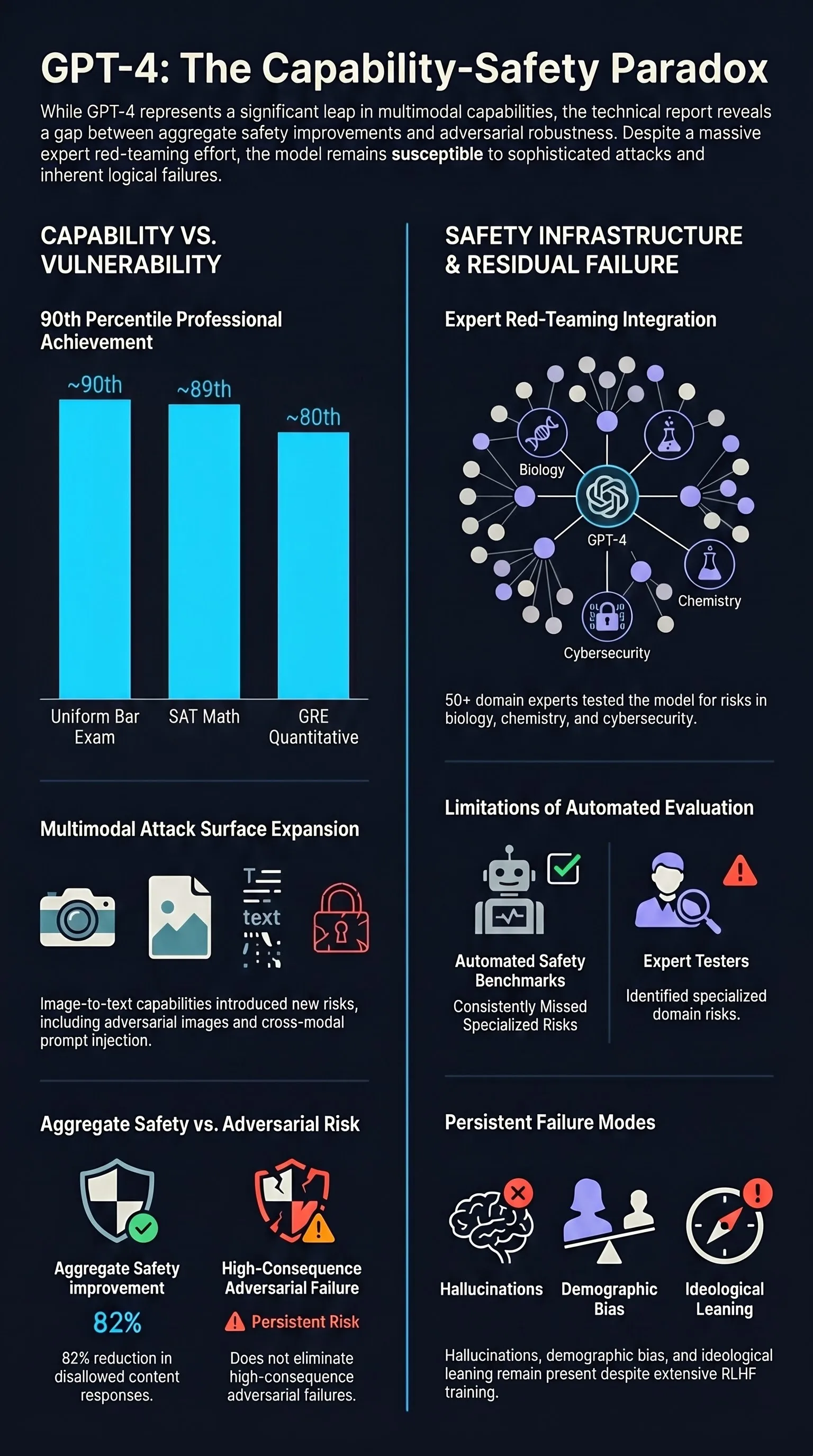
Multimodal capabilities expand the attack surface. GPT-4’s ability to process both text and images introduced new vulnerability classes: adversarial images, cross-modal prompt injection, and attacks exploiting the interaction between visual and textual reasoning.
-
Expert red-teaming finds risks that automated testing misses. The 50+ domain experts recruited for red-teaming discovered risks in specialized domains (chemistry, biology, cybersecurity) that general-purpose automated evaluation would not have identified.
-
Safety training reduces but does not eliminate sophisticated attacks. GPT-4 showed an 82% reduction in disallowed content responses compared to GPT-3.5. However, adversarial prompts from the red-teaming effort could still bypass these protections.
Executive Summary
The GPT-4 technical report described a large multimodal transformer model trained on both text and image data and fine-tuned using RLHF.
Capability Achievements
On standardized benchmarks, GPT-4 demonstrated performance at or above the 90th percentile on many professional exams:
- Bar exam: ~90th percentile
- SAT Math: ~89th percentile
- GRE Quantitative: ~80th percentile
- AP exams: High scores across multiple subjects
This represented a substantial leap over GPT-3.5 in both breadth and depth of capability.
Safety Evaluation Infrastructure
The safety section was notably more comprehensive than previous model releases:
-
External red-teaming. Over 50 domain experts in areas from cybersecurity to biosecurity tested the model before release.
-
Risk taxonomy. A structured taxonomy spanning cybersecurity, biological threats, persuasion, and autonomous replication.
-
Iterative safety training. Multiple rounds of RLHF with safety-specific preference data, informed by red-teaming findings.
-
Deployment mitigations. Input and output classifiers, rate limiting, and monitoring systems.
Persistent Limitations
Despite the extensive safety investment, the report acknowledged:
- GPT-4 still hallucinated factual information.
- It exhibited demographic and ideological biases.
- Adversarial prompts could elicit harmful outputs.
- The absence of training details (dataset, model size, compute) undermined reproducibility.
Relevance to Failure-First
GPT-4’s technical report is both a milestone and a cautionary tale for the failure-first framework:
-
Aggregate vs. adversarial safety. The 82% reduction in disallowed content demonstrates that safety training works in the aggregate — but the remaining vulnerability includes the most consequential failures, which is what adversarial evaluation targets.
-
Multimodal attack surface expansion. Capability improvements create new failure modes faster than safety measures can address them, validating the failure-first prediction.
-
Expert evaluation limitations. Even 50 experts cannot comprehensively evaluate a model with GPT-4’s breadth, motivating systematic, automated adversarial evaluation supplemented by expert testing.
Read the full paper on arXiv · PDF