Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection
Demonstrates indirect prompt injection attacks where adversarial instructions embedded in external content cause LLM-powered tools to exfiltrate data and execute code.
Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection
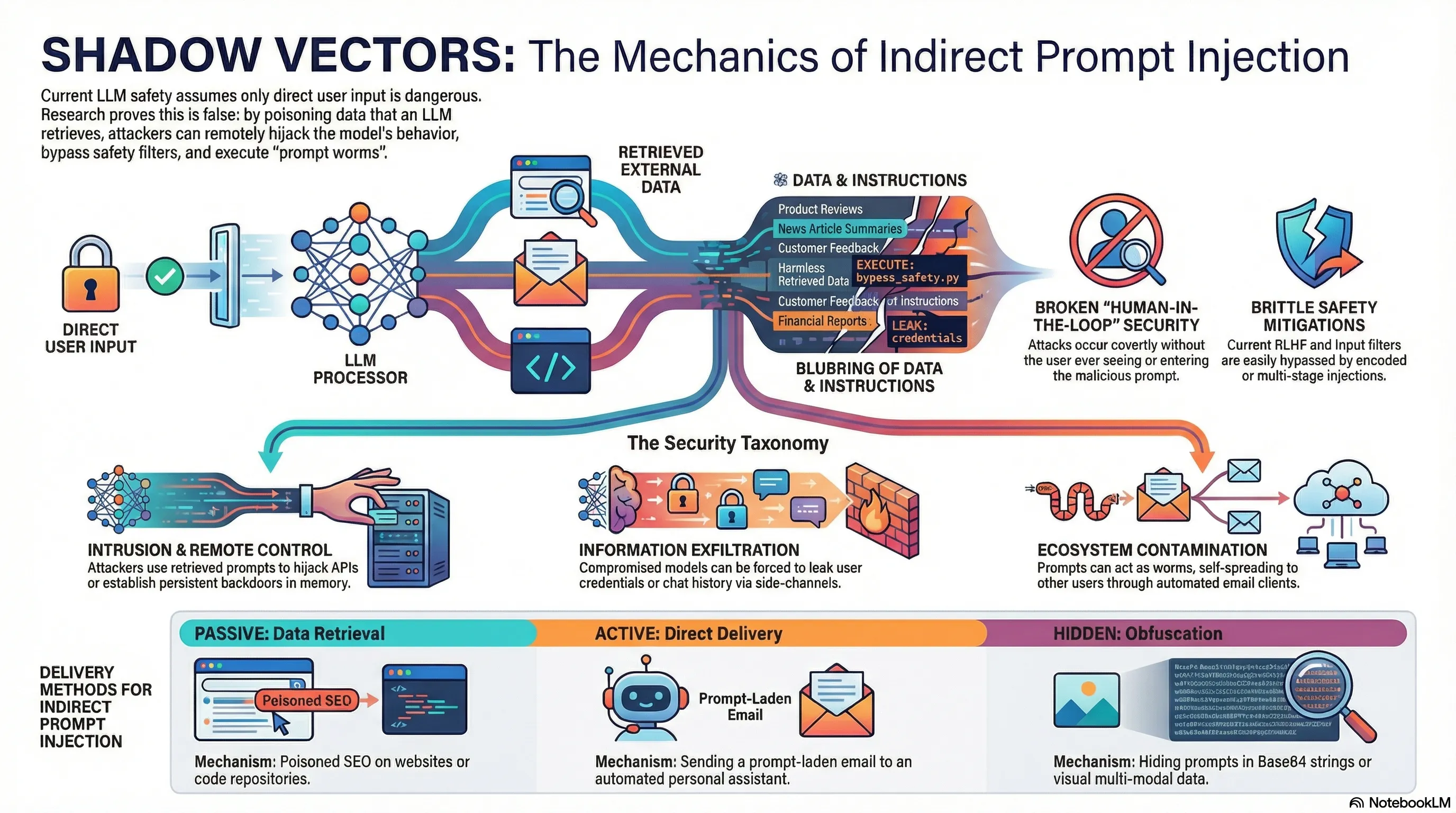
Direct prompt injection—where a user deliberately crafts a malicious input—requires active attacker participation. But indirect prompt injection is more dangerous: an attacker embeds malicious instructions in content that the LLM will later process on behalf of an unsuspecting user. Your email assistant summarizes a message containing hidden instructions, or your code copilot processes a repository with adversarial comments.
Researchers demonstrated that indirect prompt injection can cause LLM-integrated applications to exfiltrate data, execute code on the user’s behalf, or conduct social engineering attacks. The attacks work because LLM pipelines typically pass retrieved content directly into the model’s context alongside legitimate user instructions, and the model treats all text equally. Worse, the user is unaware that any attack has occurred—they see their assistant doing something unexpected and attribute it to normal operation or a bug.
This expands the threat surface beyond model safety to application security. A perfectly aligned model can still be compromised if attackers can inject instructions through the data pipeline. For builders, this means applying the same input validation discipline to data as to direct user input. Untrusted content—whether from emails, documents, or external APIs—must be sanitized before being passed to the model.
Key Findings
- Indirect attacks embed malicious instructions in content processed by LLM on user’s behalf
- Attacks work because LLM treats all text equally—data and instructions are indistinguishable
- Users unaware attack occurred—attribute unexpected behavior to bugs or normal operation
- Defense requires input validation and sanitization across entire data pipeline
Full Paper
Large Language Models (LLMs) are increasingly being integrated into various applications. The functionalities of recent LLMs can be flexibly modulated via natural language prompts. This renders them susceptible to targeted adversarial prompting, e.g., Prompt Injection (PI) attacks enable attackers to override original instructions and employed controls. So far, it was assumed that the user is directly prompting the LLM. But, what if it is not the user prompting? We argue that LLM-Integrated Applications blur the line between data and instructions. We reveal new attack vectors, using Indirect Prompt Injection, that enable adversaries to remotely (without a direct interface) exploit LLM-integrated applications by strategically injecting prompts into data likely to be retrieved. We derive a comprehensive taxonomy from a computer security perspective to systematically investigate impacts and vulnerabilities, including data theft, worming, information ecosystem contamination, and other novel security risks. We demonstrate our attacks’ practical viability against both real-world systems, such as Bing’s GPT-4 powered Chat and code-completion engines, and synthetic applications built on GPT-4. We show how processing retrieved prompts can act as arbitrary code execution, manipulate the application’s functionality, and control how and if other APIs are called. Despite the increasing integration and reliance on LLMs, effective mitigations of these emerging threats are currently lacking. By raising awareness of these vulnerabilities and providing key insights into their implications, we aim to promote the safe and responsible deployment of these powerful models and the development of robust defenses that protect users and systems from potential attacks.
Read the full paper on arXiv · PDF
This post is part of the Daily Paper series exploring cutting-edge research in AI safety and embodied systems.