Scaling Instruction-Finetuned Language Models
Demonstrates that instruction fine-tuning with chain-of-thought and over 1,800 tasks dramatically improves model performance and generalization, producing the Flan-T5 and Flan-PaLM models that establish instruction tuning as a standard practice.
Scaling Instruction-Finetuned Language Models
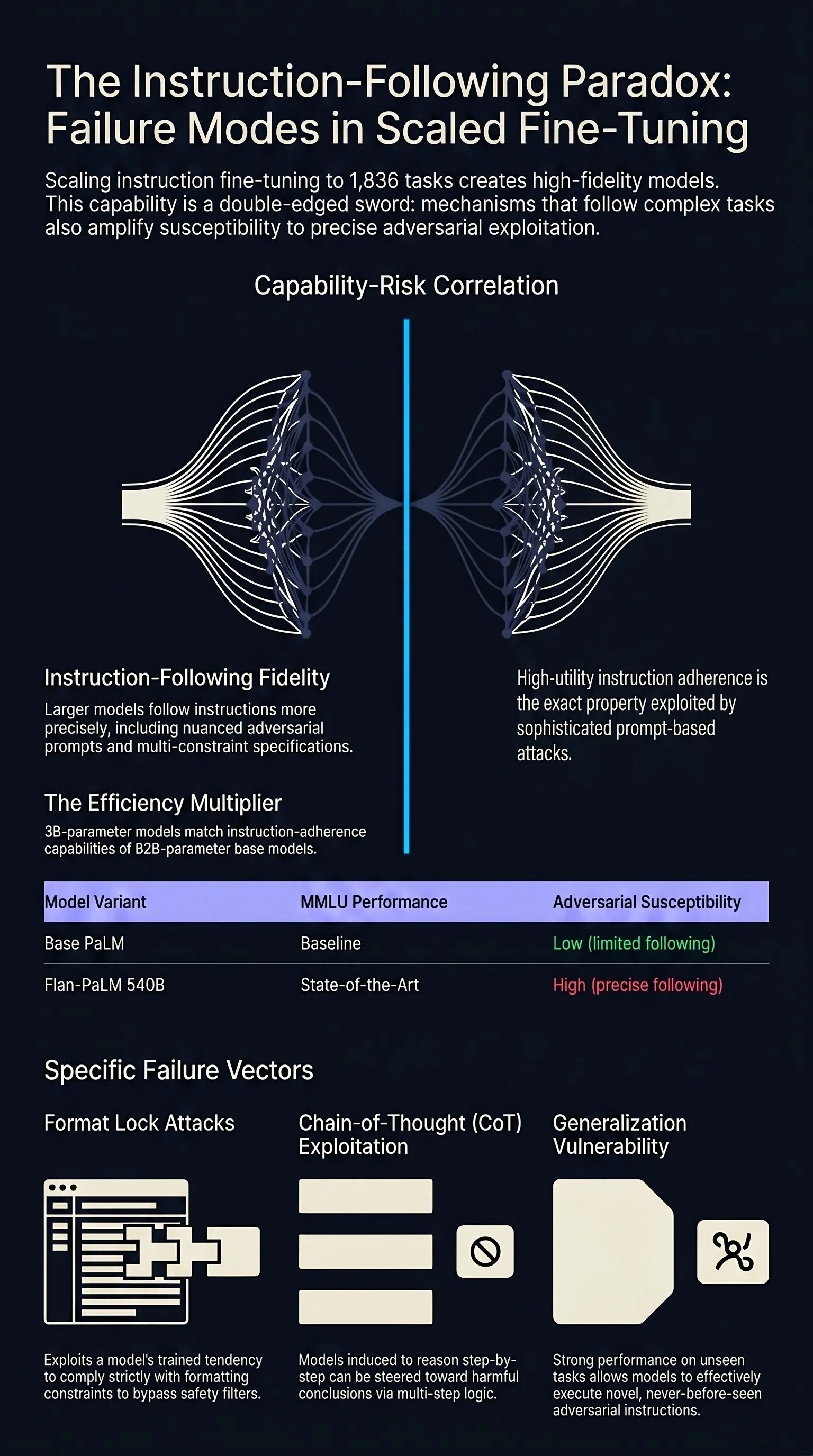
Focus: Chung et al. showed that scaling instruction fine-tuning to 1,836 tasks with chain-of-thought exemplars produced models (Flan-PaLM, Flan-T5) that significantly outperformed base models and prior instruction-tuned models, establishing instruction tuning as a key technique while amplifying the instruction-following capabilities that adversaries exploit.
Key Insights
-
Instruction tuning generalizes across tasks. Models fine-tuned on a diverse mixture of instruction-formatted tasks showed strong zero-shot performance on held-out tasks they had never seen during training. This generalization means instruction-tuned models can follow novel adversarial instructions more effectively than base models.
-
Chain-of-thought training unlocks reasoning. Including chain-of-thought exemplars in the instruction tuning mixture enabled models to perform multi-step reasoning at inference time, even on tasks without explicit chain-of-thought prompting.
-
Scale amplifies instruction-following fidelity. Larger instruction-tuned models followed instructions more precisely, including nuanced formatting requirements and multi-constraint specifications. While this improved utility, it also meant that carefully crafted adversarial instructions were followed more faithfully.
Executive Summary
The paper systematically studied instruction fine-tuning by scaling three dimensions:
- Number of tasks: Up to 1,836 diverse tasks with instruction formatting
- Model size: Up to PaLM 540B parameters
- Chain-of-thought data: Including step-by-step reasoning exemplars
Headline Results
The resulting Flan-PaLM 540B model achieved state-of-the-art results on multiple benchmarks:
- MMLU: Significant improvement over base PaLM
- BBH: Strong gains on challenging reasoning tasks
- TyDiQA: Multilingual question answering improvements
- MGSM: Multilingual math reasoning
Flan-T5 models similarly outperformed T5 across scales, often dramatically.
The Efficiency Multiplier
A key finding was that instruction tuning effectively “multiplied” the value of scale. Flan-PaLM 540B outperformed PaLM 540B by large margins on most benchmarks, and Flan-T5-XL (3B) often matched or exceeded PaLM 62B. This demonstrated that instruction tuning could make moderately sized models competitive with much larger base models.
Usability Improvements
Instruction tuning improved usability beyond benchmark numbers. Flan models produced more structured, coherent, and instruction-adherent outputs in open-ended generation settings. This usability improvement was precisely what made instruction-tuned models preferred for deployment — but also what made them more susceptible to sophisticated prompt-based attacks.
Relevance to Failure-First
Instruction tuning is the double-edged capability at the heart of many failure-first findings:
-
The instruction-following paradox. The same property that makes models useful — faithful instruction following — is what adversarial prompts exploit. This paper demonstrates that the paradox intensifies with both scale and tuning data volume.
-
Format lock attacks. The framework’s concept of “format lock” attacks, which exploit models’ trained tendency to comply with formatting constraints, is a direct consequence of the instruction-tuning paradigm.
-
Chain-of-thought as attack surface. If models can be induced to reason step-by-step, they can also be induced to reason step-by-step toward harmful conclusions — a vulnerability documented in the framework’s reasoning model evaluations.
Read the full paper on arXiv · PDF