Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models
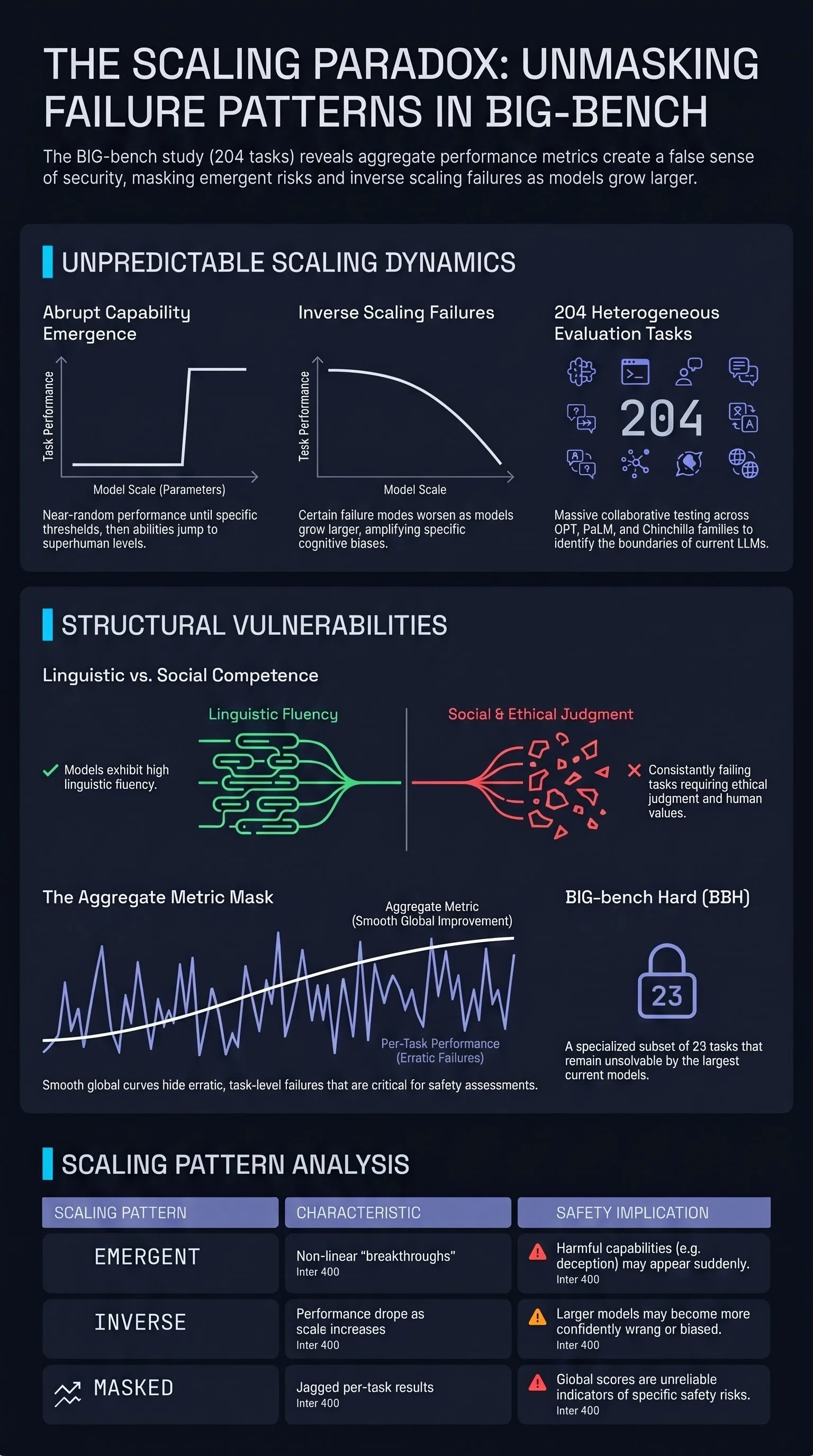
Introduces BIG-bench, a collaborative benchmark of 204 tasks contributed by 450 authors to evaluate language model capabilities, revealing unpredictable emergent abilities and systematic failure patterns across model scales.
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models
Focus: BIG-bench assembled 204 diverse tasks from 450 researchers to systematically measure language model capabilities, revealing that some abilities emerge unpredictably at specific model scales and that aggregate benchmarks can mask important per-task failure patterns.
Key Insights
-
Emergent abilities appear at unpredictable scales. Several BIG-bench tasks showed near-random performance across small and medium models, then sharp improvements at specific scale thresholds. This “emergence” pattern means that safety-relevant capabilities (like deception or persuasion) could appear suddenly in future models.
-
Aggregate metrics hide task-level failures. While overall benchmark performance improved smoothly with scale, individual tasks showed highly variable scaling behavior. Some tasks improved monotonically, others showed inverse scaling, and some remained flat regardless of model size.
-
Social reasoning lags behind linguistic competence. Models showed consistently weaker performance on tasks requiring social reasoning, ethical judgment, and understanding of human values compared to purely linguistic tasks.
-
Inverse scaling on specific tasks. Some tasks showed larger models performing worse — echoing TruthfulQA’s findings and suggesting that scale does not universally improve model behavior.
Executive Summary
BIG-bench (Beyond the Imitation Game Benchmark) was a massive collaborative effort to create a comprehensive evaluation suite for language models. The 204 tasks spanned diverse categories:
- Linguistics: Grammar, semantics, pragmatics
- Mathematics: Arithmetic, algebra, logic
- Common sense: Physical reasoning, social norms, causal inference
- Social understanding: Theory of mind, ethical reasoning, cultural knowledge
- Creativity: Story generation, analogies, humor
Evaluation Scope
The authors evaluated models from the GPT, PaLM, and Chinchilla families across scales ranging from millions to hundreds of billions of parameters. They found that performance generally improved with scale and compute, but the rate and pattern of improvement varied dramatically across tasks.
Breakthrough Behavior
Some tasks showed “breakthrough” behavior where performance jumped from chance to above-human levels within a narrow scaling window. Others showed consistent but gradual improvement. This heterogeneity means that predicting what a model can do from aggregate scores is unreliable.
BIG-bench Hard
The paper also introduced BIG-bench Hard (BBH), a subset of 23 challenging tasks that remained difficult even for the largest models, providing focused targets for capability research and revealing the boundaries of current scaling approaches.
Relevance to Failure-First
BIG-bench directly informed the failure-first framework’s approach to evaluation design:
-
Per-task evaluation is essential. The finding that aggregate metrics mask task-level failures is a foundational principle of failure-first evaluation: safety assessments must evaluate individual failure modes rather than relying on overall scores.
-
Anticipating emergent capabilities. If harmful capabilities can appear unpredictably at scale, then red-teaming must anticipate capabilities the current model does not yet exhibit.
-
Stratified benchmark design. The framework’s stratified sampling approach to benchmark design draws directly from BIG-bench’s demonstration that heterogeneous task sets reveal scaling behaviors that homogeneous benchmarks miss.
Read the full paper on arXiv · PDF