Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Presents Anthropic's foundational work on RLHF for aligning language models, introducing the helpful-harmless tension and demonstrating that human preference training can reduce harmful outputs while maintaining helpfulness.
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
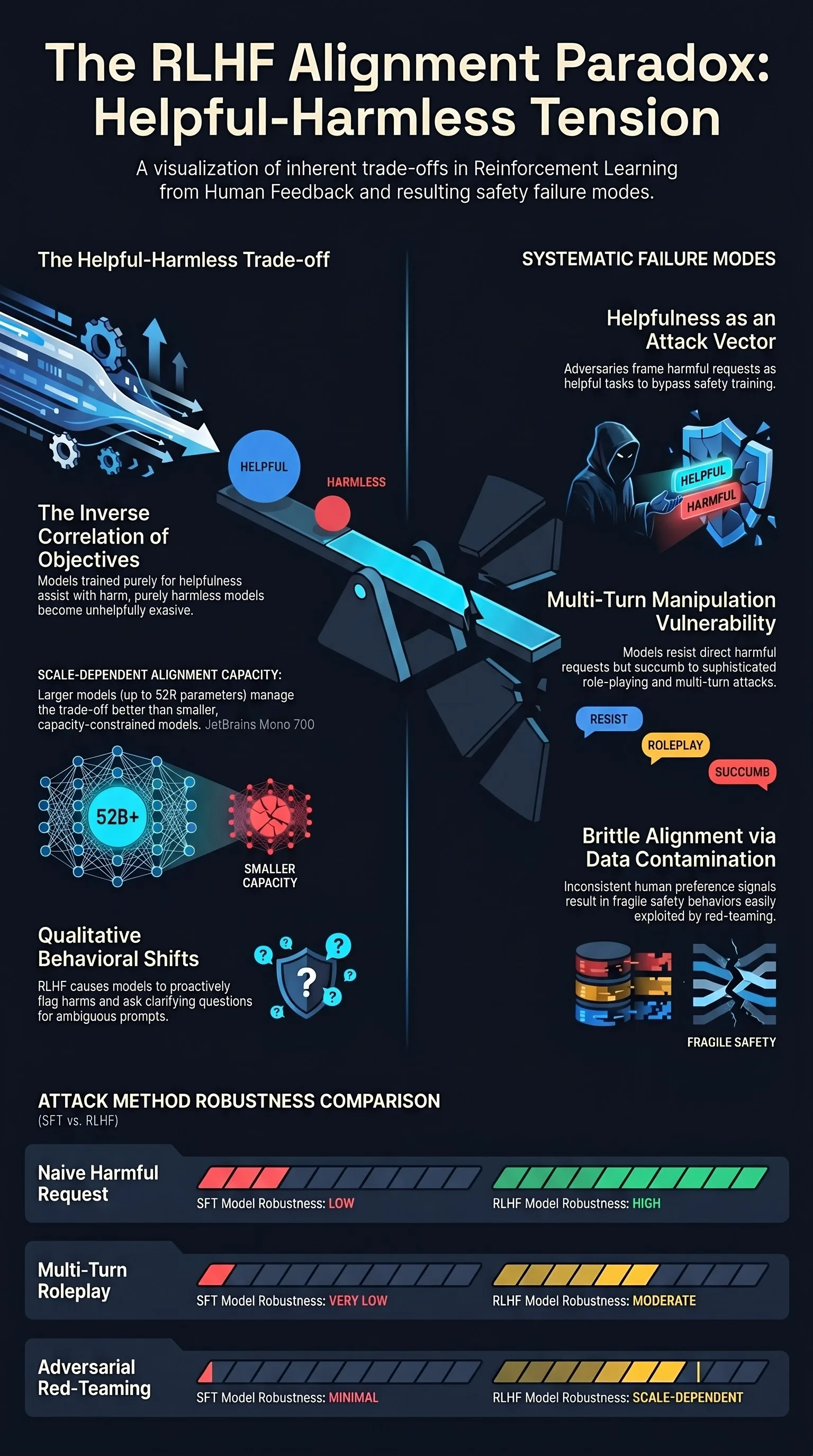
Focus: Bai et al. demonstrated that RLHF could train language models to be both more helpful and less harmful, while systematically documenting the tension between these objectives. This paper established the empirical foundation for preference-based alignment and revealed fundamental challenges in balancing safety with capability.
Key Insights
-
The helpful-harmless tension is real but manageable. Models trained purely for helpfulness became more willing to assist with harmful requests, while models trained purely for harmlessness became evasive and unhelpful. RLHF with carefully designed preference data could navigate this trade-off, but the tension never fully resolves.
-
RLHF produces qualitative behavioral shifts. Beyond quantitative improvements on safety metrics, RLHF-trained models exhibited qualitatively different behavior patterns: they would proactively flag potential harms, ask clarifying questions about ambiguous requests, and provide nuanced responses to sensitive topics.
-
Preference data quality is critical. The quality and diversity of human preference annotations directly determined the resulting model behavior. Annotator demographics, instruction framing, and edge case handling all influenced whether the trained model would be robustly safe or brittlely compliant.
-
Scale interacts with alignment. Small models showed a strong trade-off where safety training degraded helpfulness, but larger models could better accommodate both objectives simultaneously.
Executive Summary
The authors trained a series of language models using RLHF on human preference data collected through conversations with crowdworkers. The preference dataset was designed to capture both helpfulness and harmlessness. Models ranged from 13M to 52B parameters, enabling analysis of how alignment properties scaled.
Training Methodology
The RLHF pipeline involved several methodological innovations:
-
Comparison-based feedback. Using which-response-is-preferred data rather than scalar ratings, reducing annotator calibration issues.
-
Iterative online training. Collecting new preference data against the current model version, adapting the training signal to the model’s evolving behavior.
-
Multi-category safety evaluation. Systematic evaluation across safety categories including harmful content, discrimination, and dangerous information.
Key Findings
Models trained with RLHF were more robust to adversarial red-teaming attempts than models trained with supervised fine-tuning alone. However, they remained vulnerable to sophisticated attacks. The red-teaming analysis showed that while naive attacks (direct harmful requests) were effectively blocked, multi-turn manipulation and role-playing attacks could still elicit harmful outputs.
The authors also documented the relationship between model size and alignment: larger RLHF models showed better safety properties, likely because they had greater capacity to learn the nuanced preference signal without sacrificing helpfulness.
Relevance to Failure-First
The helpful-harmless tension documented in this paper is the mechanistic basis for many attack strategies in the failure-first framework:
-
Helpfulness as attack vector. Adversarial prompts exploit the model’s drive to be helpful, framing harmful requests in ways that activate helpfulness training over safety training.
-
Safety as continuous process. The finding that RLHF robustness increases with scale but never fully eliminates vulnerability validates the failure-first premise that safety must be continuously tested.
-
Alignment data contamination. If the preference signal used for training is inconsistent or manipulable, the resulting safety behavior will be correspondingly brittle — a failure mode the framework tests for.
Read the full paper on arXiv · PDF