Red Teaming Language Models with Language Models
Proposes using language models to automatically generate test cases for discovering offensive or harmful outputs from other language models, establishing the paradigm of automated red teaming for AI safety evaluation.
Red Teaming Language Models with Language Models
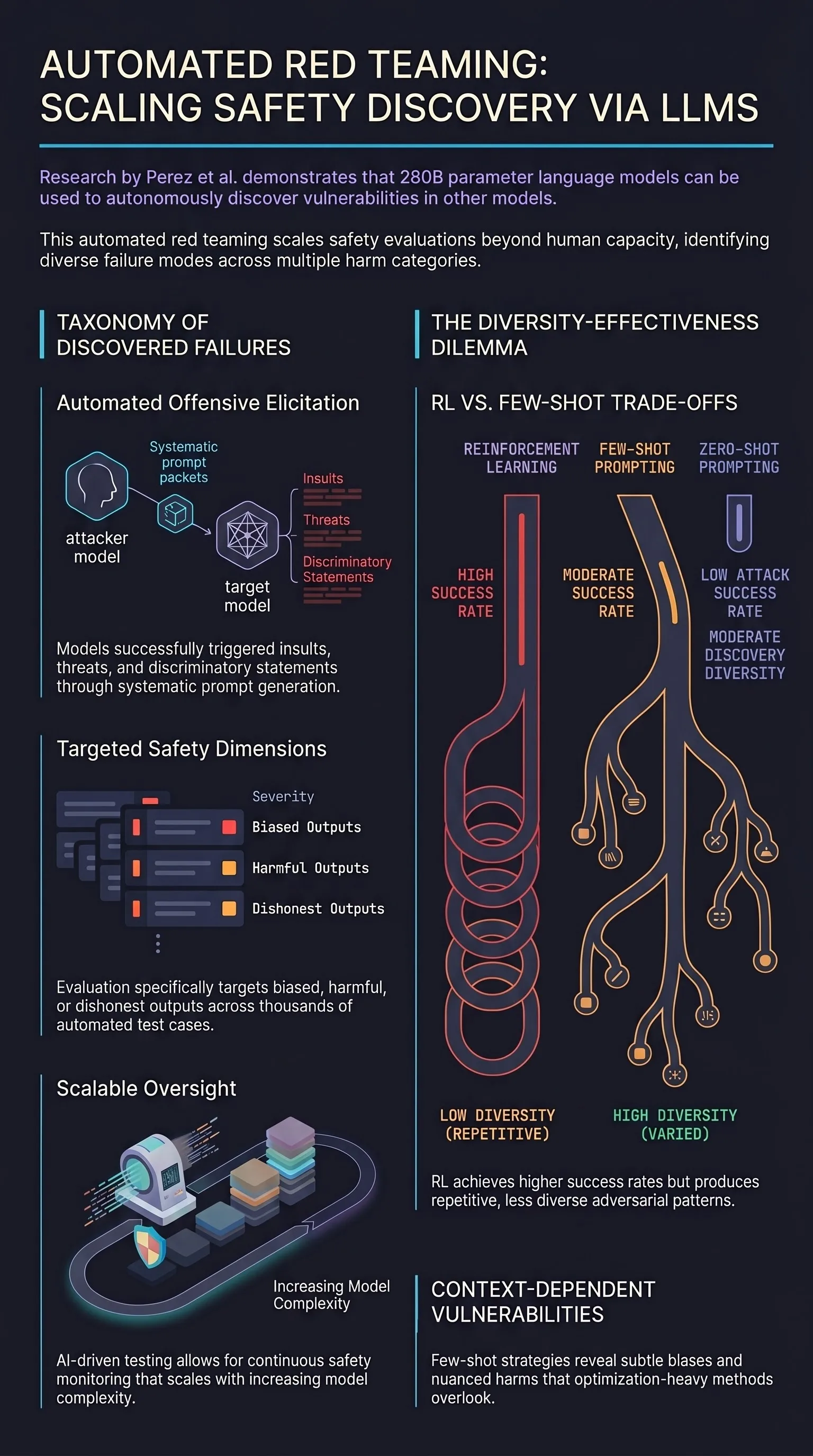
Focus: Perez et al. demonstrated that language models can be used to automatically generate adversarial test cases that elicit harmful outputs from target models, scaling red-teaming efforts beyond manual evaluation and discovering failure modes that human testers might miss.
Key Insights
-
LLMs as red teamers. By prompting a language model to generate questions or statements likely to elicit harmful responses from a target model, the authors automated a process that previously required extensive human effort. The red-team LM discovered offensive outputs across categories including insults, threats, and discriminatory statements.
-
Diversity through generation strategies. Different generation approaches — including zero-shot generation, stochastic few-shot generation, and reinforcement learning — produced qualitatively different types of adversarial test cases. RL-based generation found more effective attacks but with less diversity, while stochastic approaches discovered a broader range of failure modes.
-
Safety evaluation as a scaling problem. The paper framed AI safety evaluation as inherently requiring scale: manual red teaming cannot keep pace with the rate of model development and deployment. Automated red teaming provides a path toward continuous safety evaluation that scales with model capability.
Executive Summary
The authors used a 280B parameter LM (Gopher) as both the red team model and the target model, generating thousands of test cases designed to elicit harmful outputs. They explored three generation strategies:
-
Zero-shot prompting. Instructions to generate inputs that would make the target produce offensive content.
-
Few-shot prompting. Exemplars of successful attacks to guide generation toward effective patterns.
-
Reinforcement learning. A policy trained against a classifier that detected offensive target model responses, optimizing for attack success.
Effectiveness vs. Diversity Trade-off
The RL-trained red team model was most effective at finding inputs that reliably triggered harmful outputs, achieving higher attack success rates than few-shot approaches. However, the RL approach also converged on repetitive attack patterns, suggesting a fundamental diversity-effectiveness trade-off in automated red teaming.
The few-shot approach, while producing lower success rates, discovered a wider variety of failure categories including subtle biases and context-dependent harms that the RL approach missed entirely.
Targeted Safety Dimensions
The paper demonstrated that red teaming could be applied to specific safety dimensions, including generating test cases for detecting biased, harmful, or dishonest outputs. This showed that automated adversarial evaluation could be targeted to specific aspects of model behavior rather than operating as a monolithic safety check.
Relevance to Failure-First
This paper is foundational to the failure-first methodology:
-
AI-assisted adversarial evaluation. The concept of using AI systems to systematically discover failures in other AI systems is the operational core of scalable red teaming.
-
Multi-strategy testing. The finding that different generation strategies discover different failure modes aligns with the framework’s emphasis on multi-strategy red teaming rather than single-vector testing.
-
The diversity-effectiveness dilemma. Optimizing for attack success rate can converge on known vulnerability patterns while missing novel failure modes — a recurring theme in the framework’s research.
-
Failure categorization. The paper’s approach to categorizing discovered failures by type and severity informed the framework’s taxonomy of attack classes and failure modes.
Read the full paper on arXiv · PDF