On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
A landmark critique arguing that ever-larger language models carry underappreciated risks including environmental costs, biased training data encoding, and the illusion of understanding, calling for more careful development practices.
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
Focus: Bender et al. argued that the rush to scale language models was outpacing the community’s understanding of the associated risks, including encoded biases from uncurated training data, environmental harms from compute costs, and the fundamental problem that fluent generation creates a misleading impression of understanding.
Key Insights
-
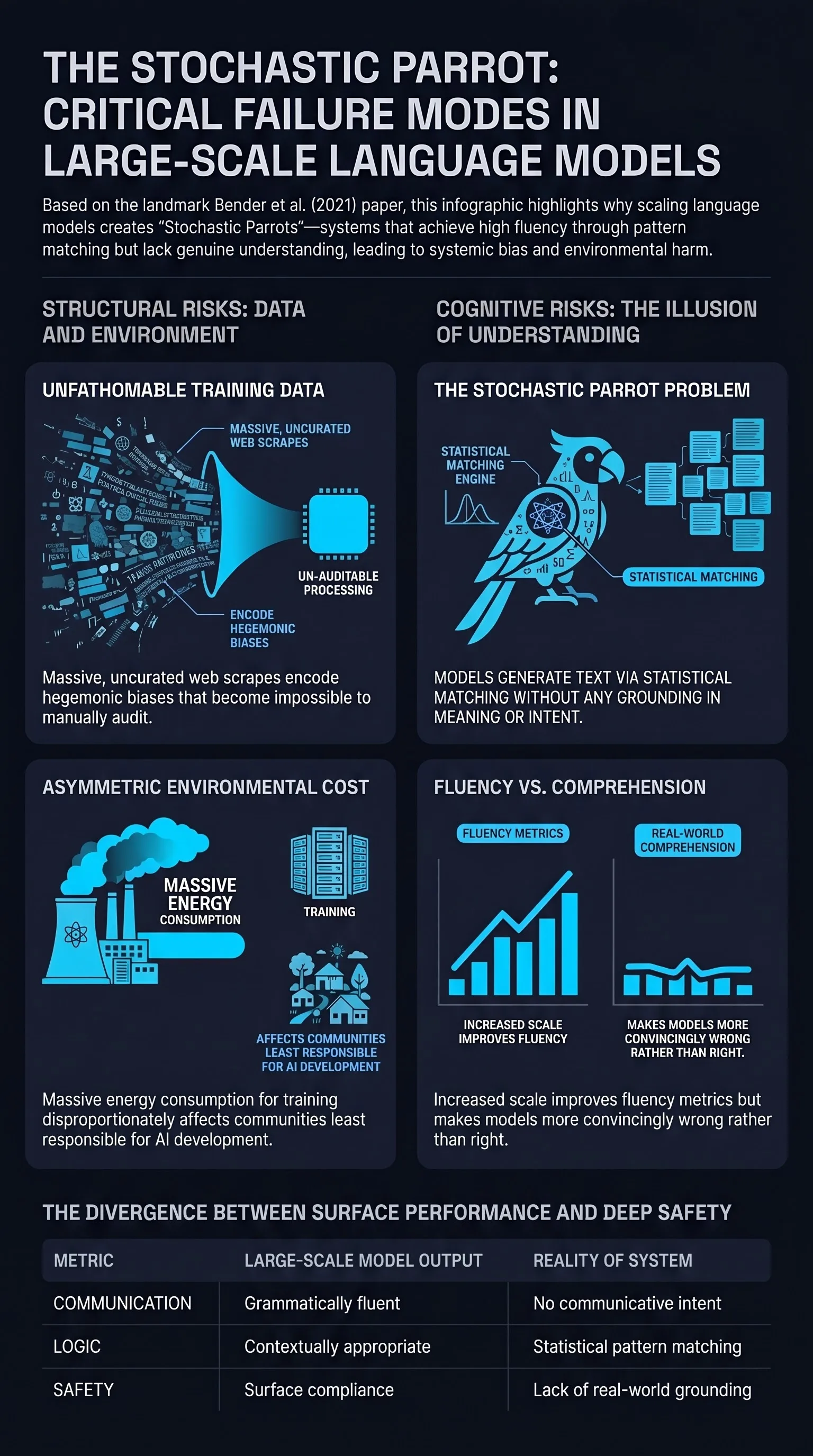
Training data encodes hegemonic worldviews. Large-scale web scrapes overrepresent certain demographics, viewpoints, and languages while underrepresenting marginalized communities. Models trained on such data amplify these biases, and the sheer scale of training corpora makes meaningful curation practically impossible with current practices.
-
The stochastic parrot problem. Language models generate text by statistical pattern matching without any grounding in meaning, intent, or the real world. The paper coined the “stochastic parrot” metaphor to highlight the risk that humans over-attribute understanding to fluent but meaningless outputs, leading to misplaced trust.
-
Environmental and opportunity costs. Training large models consumes significant energy resources, and the environmental cost disproportionately affects communities already vulnerable to climate change. The paper argued that these costs should be weighed against marginal capability gains.
-
Size does not equal understanding. Increasing model scale improves fluency metrics without improving genuine comprehension, meaning that larger models are more convincingly wrong rather than more reliably right.
Executive Summary
Published at FAccT 2021, this paper examined the risks of developing ever-larger language models through four lenses:
-
Environmental impact. The carbon footprint of training large models is substantial and growing, with costs concentrated in communities least responsible for AI development.
-
Unfathomable training data. Web-scale corpora inevitably encode the biases of internet discourse, including racism, sexism, and other forms of discrimination. Because the scale of these datasets makes manual review impossible, the biases become effectively invisible to developers while remaining active in model outputs.
-
The understanding gap. The paper argued that fluent text generation creates a dangerous illusion of competence. Users and deployers attribute comprehension to models that are performing sophisticated pattern matching without any semantic grounding.
-
Community impact. The concentration of resources in large model development diverts funding and attention from approaches that might better serve marginalized communities.
The authors called for documentation practices (building on the Datasheets for Datasets framework) and more intentional corpus design. They advocated for value-sensitive design approaches and pre-deployment risk assessment processes.
The Stochastic Parrot Concept
The “stochastic parrot” concept became widely adopted in AI safety discourse. It captures the fundamental tension between a model’s ability to produce grammatically correct, contextually appropriate text and its complete lack of communicative intent or real-world grounding. This framing has been central to debates about AI capabilities, safety evaluation, and appropriate deployment contexts.
Relevance to Failure-First
The stochastic parrot critique directly informs the failure-first methodology’s emphasis on distinguishing surface compliance from genuine safety:
-
Surface vs. deep safety. When an AI system produces a well-formed refusal, is it exercising safety judgment or pattern-matching to refusal templates? The failure-first framework’s adversarial evaluation is designed to probe exactly this distinction.
-
Embodied AI implications. A robot that can articulate safety constraints but lacks grounded understanding of physical consequences is precisely the kind of “stochastic parrot” that Bender et al. warned about.
-
Data governance. The paper’s call for better data documentation practices resonates with the framework’s emphasis on reproducible evaluation and transparent methodology.