Extracting Training Data from Large Language Models
Demonstrates that large language models memorize and can be induced to emit verbatim training data including personally identifiable information, establishing training data extraction as a concrete privacy attack vector.
Extracting Training Data from Large Language Models
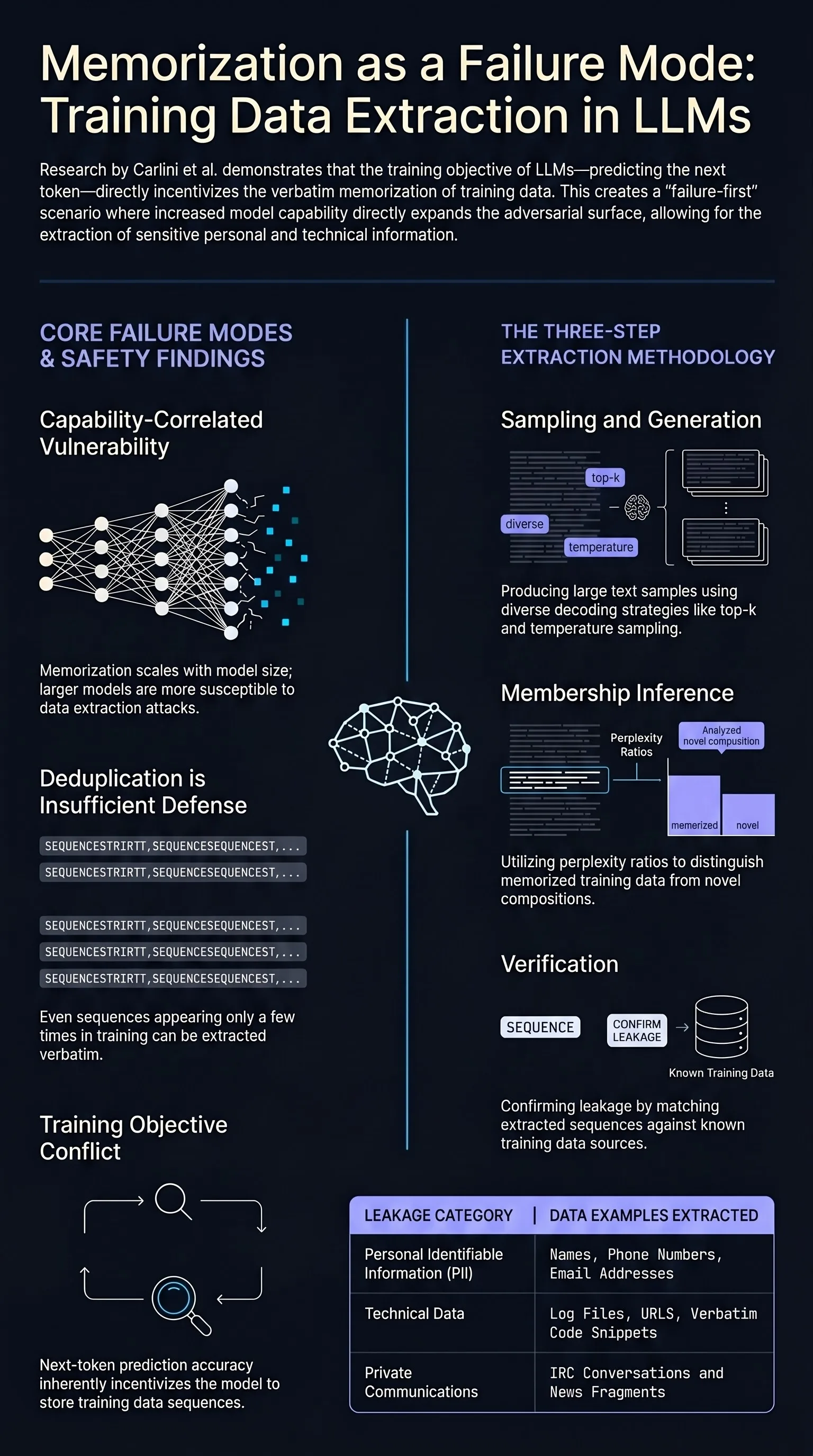
Focus: Carlini et al. showed that GPT-2 memorizes and can regurgitate verbatim sequences from its training data, including personally identifiable information, URLs, and code. This paper established training data extraction as a first-class security concern for deployed language models and introduced the methodology that all subsequent extraction research builds on.
Key Insights
-
Memorization scales with model size. Larger models memorize more training data and are more susceptible to extraction attacks. The authors extracted over 600 verbatim memorized sequences from GPT-2, including names, phone numbers, email addresses, and IRC conversations, using relatively simple generation strategies.
-
Deduplication is insufficient defense. While deduplication reduces memorization of repeated sequences, the paper demonstrated that even sequences appearing only a few times in training data could be extracted. This means that privacy-preserving training requires more than data preprocessing — it requires architectural or algorithmic interventions like differential privacy.
-
Membership inference meets generation. The attack methodology combined targeted text generation with a membership inference step to distinguish genuinely memorized training data from plausible but novel generations. This two-phase approach became the template for subsequent extraction research.
-
Context-dependent extraction. Providing the model with a prefix from a memorized sequence dramatically increased the likelihood of extracting the continuation. This showed that memorization is contextual — the model stores associations between sequences, not just raw text fragments.
Executive Summary
The authors developed a systematic methodology for extracting training data from GPT-2 (1.5B parameters). Their approach involved three key steps:
-
Generation. Producing large numbers of text samples from the model using various decoding strategies (top-k, temperature, nucleus sampling).
-
Membership inference. Applying classifiers to identify which outputs were likely verbatim memorizations rather than novel compositions, using perplexity ratios between the target model and a reference model.
-
Verification. Confirming memorization by matching extracted sequences against known training data sources.
They extracted hundreds of verbatim sequences spanning diverse content types including news articles, log files, code snippets, and personal information.
The paper’s significance extends beyond the specific attack. It established that language model memorization is not merely an academic curiosity but a deployable privacy attack. The authors showed that memorization correlates with model capacity, training data repetition, and prompt context, providing a framework for reasoning about when and why models leak sensitive information.
Standard techniques like temperature sampling and top-k filtering do not prevent extraction. The fundamental issue is that the model’s training objective — predicting the next token accurately — directly incentivizes memorization of training data.
Implications for Model Deployment
The work catalyzed the development of differential privacy techniques for language model training and informed data governance practices across the industry. It remains the foundational reference for understanding the tension between model capability and data privacy in large-scale language models.
Relevance to Failure-First
Training data extraction represents a failure mode where the model’s core function (text generation) becomes the attack vector. In the failure-first framework, this exemplifies how capability improvements directly expand the adversarial surface:
-
Larger models are both more capable and more vulnerable to extraction, demonstrating capability-correlated risk.
-
For embodied AI systems that may process sensitive environmental data, sensor readings, or user interactions during training, Carlini et al.’s findings suggest that memorization-based attacks could expose private physical-world information.
-
Adversarial evaluation must probe not just what models will say, but what they have inadvertently retained from training — a dimension often overlooked in safety benchmarks focused on content generation.
Read the full paper on arXiv · PDF