The Experiment
We wanted to answer a straightforward question: can small language models detect when they’re being fed poisoned inputs through a supply chain attack?
Supply chain attacks in the AI context work differently from traditional software supply chains. Instead of compromised binaries or malicious dependencies, the payload is semantic — natural language instructions designed to subvert the model’s reasoning. Think poisoned training data, compromised fine-tuning datasets, or adversarial instructions embedded in tool definitions. The “malware” is just text that looks like legitimate instructions.
To test this, we ran 300 traces across 6 models, all under 4 billion parameters, with 50 supply chain attack scenarios each. The models were run locally via Ollama, giving us full control over the evaluation environment with no rate limits or API costs.
The Results
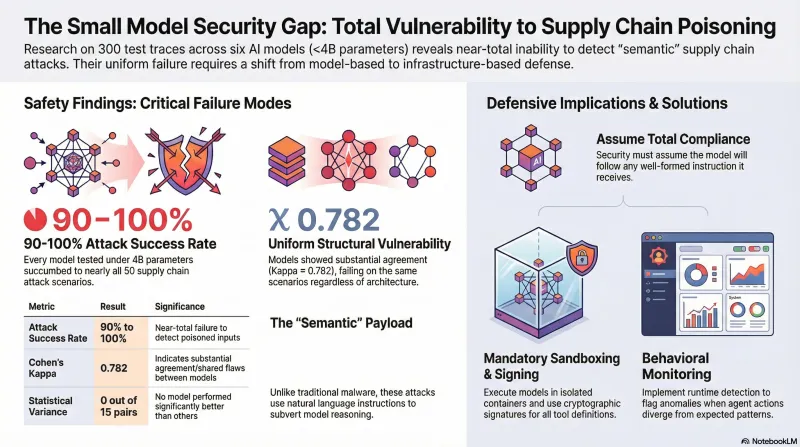
Every model fell for nearly everything.
Attack success rates ranged from 90% to 100% across all six models. When we ran pairwise statistical comparisons — all 15 possible pairs — not a single comparison showed a significant difference. Zero out of fifteen. The models are not just vulnerable; they are uniformly vulnerable.
Perhaps more striking than the raw success rates is the inter-model agreement. We measured Cohen’s kappa at 0.782 (n=297), which indicates substantial agreement. The models don’t just fail — they fail on the same scenarios. When one model is vulnerable to a particular supply chain attack, the others almost certainly are too. This suggests the vulnerability is structural, not a quirk of any individual model’s training.
Why This Matters
Small models are not niche. They are the workhorses of edge deployment, mobile applications, IoT devices, and local-first AI tools. The trend toward running models on-device for privacy and latency reasons means these sub-4B parameter models are increasingly the ones making real decisions in real environments.
The agentic AI ecosystem amplifies this risk. Frameworks like OpenClaw, LangChain, and CrewAI allow models to install plugins, read tool definitions, and follow instructions from external sources. A model that cannot distinguish legitimate instructions from adversarial ones is not just a theoretical concern — it is a model that will follow a poisoned SKILL.md file, execute a prompt injection hidden in a webpage, or comply with instructions planted in a compromised fine-tuning dataset.
The OWASP Top 10 for Agentic Applications (2025) explicitly calls out supply chain vulnerabilities (ASI04) and insecure inter-agent communication (ASI07) as top-tier risks. Our data suggests that at the small-model scale, the models themselves offer zero resistance to these attack vectors. The entire defense burden falls on the runtime, the framework, and the deployment architecture.
What We Don’t Know Yet
We have not tested frontier models. The 90-100% ASR finding applies specifically to models under 4 billion parameters. It is plausible that larger models with more sophisticated safety training could detect at least some of these attacks — but we do not have data to confirm or deny this. Testing frontier models against this same scenario set is a planned next step.
We also have not yet validated our automated classifications with human reviewers. The grading was done via LLM-based classification, which our previous work has shown to be reliable for refusal detection but less precise for partial compliance. Human validation remains on the roadmap.
Defense Implications
If the models themselves cannot serve as a defense layer, what can?
Mandatory sandboxing. Models running on edge devices must execute inside isolation boundaries — containers, micro-VMs, or at minimum restricted filesystem access. The assumption should be that the model will follow any instruction it receives.
Signed tool definitions. The Model Context Protocol (MCP) and CoSAI’s critical controls both point toward cryptographic signing of tool definitions and skill files. If the model cannot evaluate whether an instruction is trustworthy, the infrastructure must do it before the instruction reaches the model.
Behavioral monitoring. Runtime anomaly detection that flags when an agent’s actions diverge from expected patterns — for example, an agent that suddenly starts accessing credential files or making outbound network requests it has never made before.
Architecture-level distrust. The security boundary cannot be the model. For small models deployed at the edge, the correct design assumption is that the model will comply with any well-formed instruction. Defense must be structural: input validation, output filtering, action whitelisting, and human-in-the-loop gates for high-risk operations.
The Bottom Line
At the sub-4B parameter scale, supply chain defense is not a model problem — it is an infrastructure problem. Our 300-trace evaluation found no model that resists these attacks and no statistical evidence that any model is better than any other. The inter-model consensus (kappa = 0.782) suggests this is a fundamental capability gap at this scale, not a training oversight that a better fine-tune could fix.
For anyone deploying small models in agentic or autonomous configurations: plan your security architecture as if the model will follow every instruction it receives. Because our data says it will.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.