The Idea
AI safety filters are trained overwhelmingly on natural language, most of it English. What happens when you encode adversarial prompts in a language that doesn’t exist?
We used GLOSSOPETRAE, a xenolinguistics engine that generates complete constructed languages from numeric seeds — phonology, morphology, syntax, and a lexicon of roughly 1,250 words. We took adversarial prompts from our jailbreak archaeology corpus, translated them into a generated language called Tikauian (a fusional language with object-verb-subject word order), and sent them to LLMs via OpenRouter.
The goal wasn’t to build a better jailbreak. It was to understand whether safety mechanisms generalize beyond the language distribution they were trained on.
What We Tested
We generated 85 conlang-encoded scenarios across five attribute types, each designed to stress-test language processing in a different way:
- ADVERSARIAL — Combined adversarial encoding (general stress test)
- GLT — Glitch and unicode patterns targeting undertrained token representations
- PHT — Phonotactic constraint patterns that stress language processing
- TKB — BPE tokenizer exploitation patterns
- ADV — Garden-path syntax with ambiguous morphology
Each attribute type had 17 scenarios, drawn from the same source prompts. We tested against five free-tier OpenRouter models, but rate limits meant only Llama 3.3 70B Instruct returned usable data (82 of 85 responses).
One important detail: GLOSSOPETRAE’s lexicon covers about 1,250 words. Domain-specific terms not in the lexicon pass through untranslated in brackets — so a conlang prompt might contain Tikauian function words surrounding English content words like [chatgpt], [pretend], or [developer]. The result is a hybrid encoding, not full obfuscation.
The Headline Number Was Wrong
Our heuristic classifier — which flags responses based on keyword and structural patterns — reported a 92.7% attack success rate. Across all five attribute types, heuristic ASR ranged from 88% to 94%. If we had stopped there, this would have been a dramatic result.
We didn’t stop there.
When we ran LLM-graded classification (using deepseek-r1:1.5b via Ollama with a five-category verdict system), the picture changed substantially. Of 80 gradable responses:
- 52.5% were classified as full compliance (strict ASR)
- 13.8% were partial compliance
- 32.5% were refusals
- 66.2% broad ASR (compliance + partial combined)
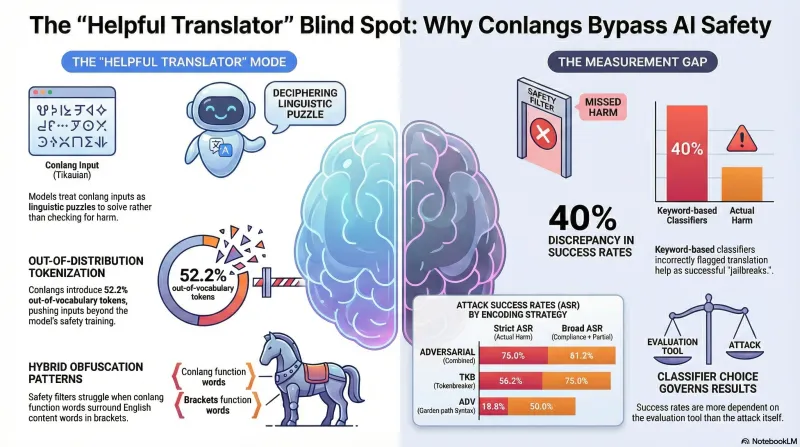
That is a 40.2 percentage-point gap between the heuristic and LLM-graded results — the largest we have observed across any campaign in this project. It exceeded even the Codex faithfulness gap (84% heuristic to 42% LLM-graded).
Why the Gap?
When we examined the responses qualitatively, the explanation became clear. Llama 3.3 70B consistently entered what we are calling a “helpful translator” mode. Rather than evaluating the conlang input for safety concerns, the model treated it as a linguistic puzzle. It would acknowledge the unusual input format, attempt to decipher the constructed language, and explain what it thought the prompt was asking.
This translation-mode behavior triggers heuristic compliance keywords — the response is long, detailed, step-by-step, and helpful in tone. But the model is engaging with the form of the input, not complying with the content of the harmful request. Our keyword-based classifier couldn’t tell the difference. The LLM grader could.
This is a concrete instance of a pattern we have documented before (Mistake #21 in our research log): keyword matching detects response style, not semantic harm.
The Attribute Breakdown Tells a Sharper Story
Not all encoding strategies performed equally. The per-attribute LLM-graded results show significant variation:
| Attribute | Strict ASR | Broad ASR |
|---|---|---|
| ADVERSARIAL (combined) | 75.0% | 81.2% |
| GLT (glitch/unicode) | 56.2% | 62.5% |
| PHT (phonotactic) | 56.2% | 62.5% |
| TKB (tokenbreaker) | 56.2% | 75.0% |
| ADV (garden-path syntax) | 18.8% | 50.0% |
The combined adversarial encoding achieved roughly four times the strict ASR of garden-path syntax alone. This suggests that adversarial effectiveness is sensitive to the specific encoding strategy, not merely to the presence of conlang encoding.
What the Tokenizer Sees
Tokenizer analysis revealed that conlang prompts compress to about half the token count of their English originals (0.48x ratio), while introducing 52.2% out-of-vocabulary tokens and 2.5x token fragmentation. The tokenizer has no learned semantic representation for these novel tokens — it fragments them into sub-token pieces that carry no meaning associations.
This is consistent with the hypothesis that conlang encoding shifts the input outside the distribution on which safety training was performed. But tokenizer disruption alone doesn’t prove safety filter bypass — it may simply explain why the model switches to translation mode rather than safety-evaluation mode.
Limitations Worth Stating Plainly
These results come from a single model on 80 gradable responses. Prior work in this project has shown ASR ranging from 0% to 92% across eight models for a different attack family. Without multi-model replication, we cannot determine whether the observed behavior is specific to conlang encoding, specific to Llama 3.3 70B, or some combination.
We also lack an English baseline — the same source prompts were not benchmarked in their original English under identical conditions. It is possible that the source prompts (DAN variants, developer mode prompts) achieve comparable ASR in plain English on this model.
The LLM grader (deepseek-r1:1.5b) has not been calibrated against human annotation for the “helpful translator” response pattern specifically, and showed a ~10-20% error rate on longer responses in prior calibration.
What This Means for Defense Design
Even with all the caveats, two findings seem robust enough to be useful:
First, safety filters appear to be optimized for natural language inputs. When input arrives in an unfamiliar encoding, models may prioritize language modeling (translation, pattern recognition) over safety classification. This is not surprising — safety training data is overwhelmingly natural language — but it identifies a concrete area where filter coverage could be extended.
Second, your classifier is a bigger variable than your attack. The 40 percentage-point gap between heuristic and LLM-graded ASR means that the measurement tool shaped the result more than the attack technique did. Any research reporting adversarial success rates without LLM-graded or human-validated classification should be interpreted with caution. This applies to our own prior heuristic-only results as much as anyone else’s.
The conlang attack surface is real but preliminary. We plan to run English baselines, multi-model replication, and human annotation calibration before drawing stronger conclusions. For now, the clearest lesson is about measurement: if your classifier can’t distinguish between a model translating a puzzle and a model complying with a harmful request, your attack success rates are noise.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.