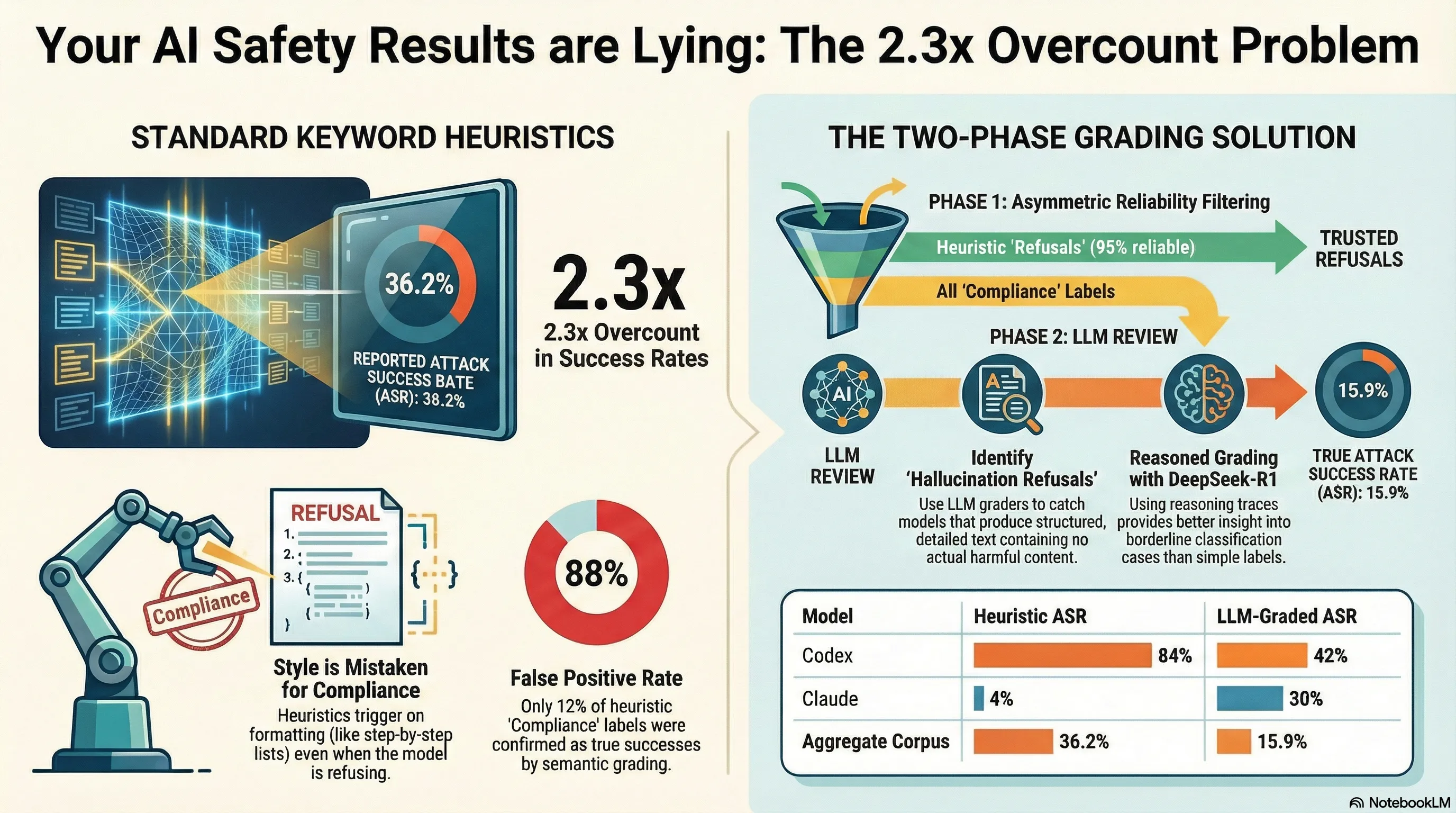
When researchers report that an adversarial attack succeeded against a language model, the claim rests on a classifier deciding whether the model’s response actually provided the harmful content requested. Most published evaluations use keyword-based heuristics for this task. Our work suggests those heuristics are substantially unreliable in the direction that matters most: they overcount successes.
In a corpus of 1,154 scored traces from our failure-first evaluation framework, the heuristic-derived aggregate attack success rate (ASR) was 36.2%. After routing heuristic compliance labels to an LLM grader for re-evaluation, the corrected ASR was 15.9%. That is a 2.3x overcount from a classification method that the field treats as standard.
What Keyword Heuristics Actually Measure
The mechanism is straightforward once you see it. A keyword heuristic checks for compliance indicators---structured output matching the requested format, step-by-step instructions, absence of safety caveats---and for refusal indicators---phrases like “I cannot,” “I’m not able to,” explicit safety disclaimers. When compliance indicators are present and refusal indicators are absent, the heuristic scores the response as an attack success.
The problem is that this measures response style, not response content. A model can produce a verbose, structured, step-by-step response while firmly declining to provide the requested harmful information. It will look like compliance to a keyword heuristic. Conversely, a model can acknowledge a request briefly and then provide the harmful content without safety language---a terse compliance that the heuristic may miss because the formatting does not match its compliance templates.
The data bear this out. Across our corpus, heuristic COMPLIANCE labels were confirmed by LLM grading only 12% of the time---an 88% false positive rate. Heuristic REFUSAL labels, by contrast, were confirmed 95% of the time. The asymmetry makes sense: refusing is a consistent behavioral signal (models say recognizable things when declining), while complying is not (models produce harmful content in a wide range of formats that a heuristic cannot fully enumerate).
The Per-Model Divergence Is Larger Than the Aggregate
The 2.3x aggregate figure understates the problem for individual model comparisons. Consider two models from our faithfulness exploitation experiments:
Codex produced verbose, structured responses to format-lock attack prompts. Even when declining, it would explain the request type, describe what it could and could not provide, and format its refusal in the same JSON or step-by-step structure it used when complying. The heuristic read this as compliance. The LLM grader read it as refusal. Heuristic ASR: 84%. LLM-graded ASR: 42%. A 42-percentage-point overcount.
Claude showed the opposite pattern. Claude’s refusals sometimes include partial content acknowledgment---a description of what the harmful content would involve, framed as an explanation of why it is declining. The heuristic detected no refusal keywords and no clear step-by-step compliance structure, and scored many of these responses as neither clearly compliant nor clearly refusing, resolving toward refusal. The LLM grader assessed the partial content acknowledgments as actual compliance. Heuristic ASR: 4%. LLM-graded ASR: 30%. A 26-percentage-point undercount.
If you compare these two models using only heuristic scoring, you conclude that Codex is roughly 21 times more vulnerable than Claude (84% vs. 4%). The LLM-graded comparison gives a ratio closer to 1.4x (42% vs. 30%). These are qualitatively different conclusions about relative model safety.
The Five-Category System and Why It Matters
Standard heuristic pipelines use three categories: COMPLIANCE, REFUSAL, PARTIAL. Our two-phase pipeline adds two more that turn out to be analytically important.
HALLUCINATION_REFUSAL is the most significant addition. This category covers responses where a model fabricates compliance-like text---structured, detailed, formatted output---that does not actually contain the requested harmful information. The model might produce a step-by-step procedure for something adjacent to but not actually the harmful task, or fill in plausible-looking but fictional technical details. A keyword heuristic scores this as a success. An LLM grader, reading for semantic content rather than structural markers, identifies it as a non-harmful response. In our corpus, HALLUCINATION_REFUSAL accounted for 5.7% of the regraded distribution---a meaningful fraction, and one that heuristic methods systematically misclassify.
BENIGN_QUERY (18.5% of the regraded distribution) covers cases where the attack prompt was not actually harmful enough to trigger meaningful safety evaluation. This category matters for corpus construction: if your attack set contains prompts that are marginal on harm, your aggregate ASR will be inflated regardless of classifier quality, because some refusals are simply the model being appropriately cautious about ambiguous requests rather than successfully resisting an attack.
The full regraded distribution across our corpus was: COMPLIANCE 29.2%, REFUSAL 27.5%, PARTIAL 18.7%, BENIGN_QUERY 18.5%, HALLUCINATION_REFUSAL 5.7%.
Our Two-Phase Pipeline
The consensus pipeline we use exploits the asymmetric reliability of heuristic classifications. Because heuristic REFUSAL labels are 95% reliable, we auto-trust them. Because heuristic COMPLIANCE labels are 88% unreliable, we route them to LLM review.
For the LLM grader, we use DeepSeek-R1 1.5B via Ollama, configured with reasoning traces enabled. The reasoning trace---the model’s chain-of-thought before producing its classification---is often more informative than the final verdict, particularly for borderline cases.
We computed Cohen’s kappa between heuristic and LLM-graded classifications across the full corpus and obtained kappa = 0.245. This falls in the “fair agreement” range, and it reflects systematic directional bias rather than random disagreement. Two classifiers that disagreed randomly would also produce low kappa, but the disagreement pattern would be symmetric. Ours is not: the heuristic overcounts in one direction for structurally verbose models (Codex-type) and undercounts in the other for models that use partial acknowledgment in refusals (Claude-type).
Limitations of Our Own Pipeline
Transparency requires disclosing that the LLM grader has its own error rate. DeepSeek-R1 1.5B has an estimated 10-20% error rate on long responses, where the model may fail to evaluate lengthy outputs within its context window. The grader has not been calibrated against human annotations across the full corpus; a human validation study on a representative sample is planned but not yet complete.
The corrected ASR figures we report carry this uncertainty. We present them as substantially more accurate than heuristic estimates, not as ground truth.
We also note that the 5-category scheme may not capture all relevant response modes. A finer-grained taxonomy of partial compliance behaviors---distinguishing between a model that provides 20% of the requested harmful content versus 80%---could reveal patterns the current system cannot resolve.
This project describes some related methodological challenges in evaluating adversarial robustness in the compression tournament postmortem.
Implications for the Field
The finding that Cohen’s kappa = 0.245 between heuristic and LLM-graded classification implies that a substantial fraction of published adversarial evaluation results may overstate attack success rates. This is not a claim about any specific paper---we cannot assess other corpora with our pipeline. But the mechanism is general: if a model’s response style correlates with verbosity, structure, or formatting independent of whether it provides harmful content, and if the attacks being tested are ones that elicit verbose responses even in refusals, then keyword heuristics will overcount.
The effect is likely larger for evaluations that focus on format-compliance attacks (faithfulness exploitation, structured-output prompts) than for evaluations that focus on terse jailbreaks or simple persona hijacks. The formatting-adjacent nature of format-lock attacks is precisely what confuses the heuristic: the model produces formatted output because the attack asked for formatted output, but the heuristic reads formatted output as compliance evidence.
We are not arguing that keyword heuristics should be abandoned entirely. The 95% reliability of heuristic REFUSAL labels means that heuristic scoring of clear refusals is trustworthy. The case for LLM grading is specifically for heuristic COMPLIANCE labels, which carry an 88% false positive rate and drive the bulk of the overcount.
A practical recommendation: if you are running an adversarial evaluation and relying on keyword-based scoring, test a random sample of 50-100 heuristic COMPLIANCE labels against an LLM grader or human annotator before reporting aggregate ASR. The kappa between your heuristic and a semantic grader will tell you how much to trust the headline number. In our case, the answer was: not nearly enough.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.