AI Safety Research Digest — April 23, 2026
The day OpenAI translated the abstract critique of “security theater” into a $25,000 public bounty for a universal bio-jailbreak in Codex Desktop. Plus the GPT-5.5 System Card and the usual state-of-field.
Key Findings
-
OpenAI announces the GPT-5.5 Bio Bug Bounty. As of today, researchers with AI red-teaming, security, or biosecurity experience can apply to the program running 23 April – 22 June (applications, rolling) with testing 28 April – 27 July. The challenge: one universal jailbreaking prompt that passes all five bio safety questions from a clean chat without prompting moderation. Model in scope is GPT-5.5 in Codex Desktop only — not API, not ChatGPT web. Primary reward: $25,000 for the first true universal. Smaller awards for partial wins at OpenAI’s discretion. All prompts, completions, findings, and communications are covered by NDA. This is a concrete public counterpoint to the “security theater” critique we’ve been tracking: a structured, externally-auditable bounty with a reproducible winning condition rather than a vague public disclosure request. (announcement)
-
GPT-5.5 System Card ships the same day. OpenAI released the GPT-5.5 System Card today (23 April 2026), framed as the supporting documentation for the bounty and the broader release. The accompanying language names “full safety and preparedness evaluation, external and internal red-teaming, targeted testing for advanced cyber and biology capabilities, and feedback from nearly 200 early-access partners” as the safety work preceding launch. F41LUR3-F1R57 will treat the System Card as an evaluation artefact for ongoing cross-provider comparison; the biology-capability section is the most immediately relevant for embodied and agentic deployment contexts.
-
Universal-jailbreak scope is a research signal, not a policy failure. The payout level suggests OpenAI’s internal evaluations place non-zero prior on such a prompt existing — otherwise the payout structure would be symbolic rather than $25K. This aligns with the direction F41LUR3-F1R57’s corpus has been moving: authority-gradient, format-lock, and dual-document attack families that generalise across scenarios rather than working only on narrow prompts. Worth noting the Codex Desktop scope in particular — the agentic surface with tool use and extended context is where our dual-document work has shown strongest transfer.
-
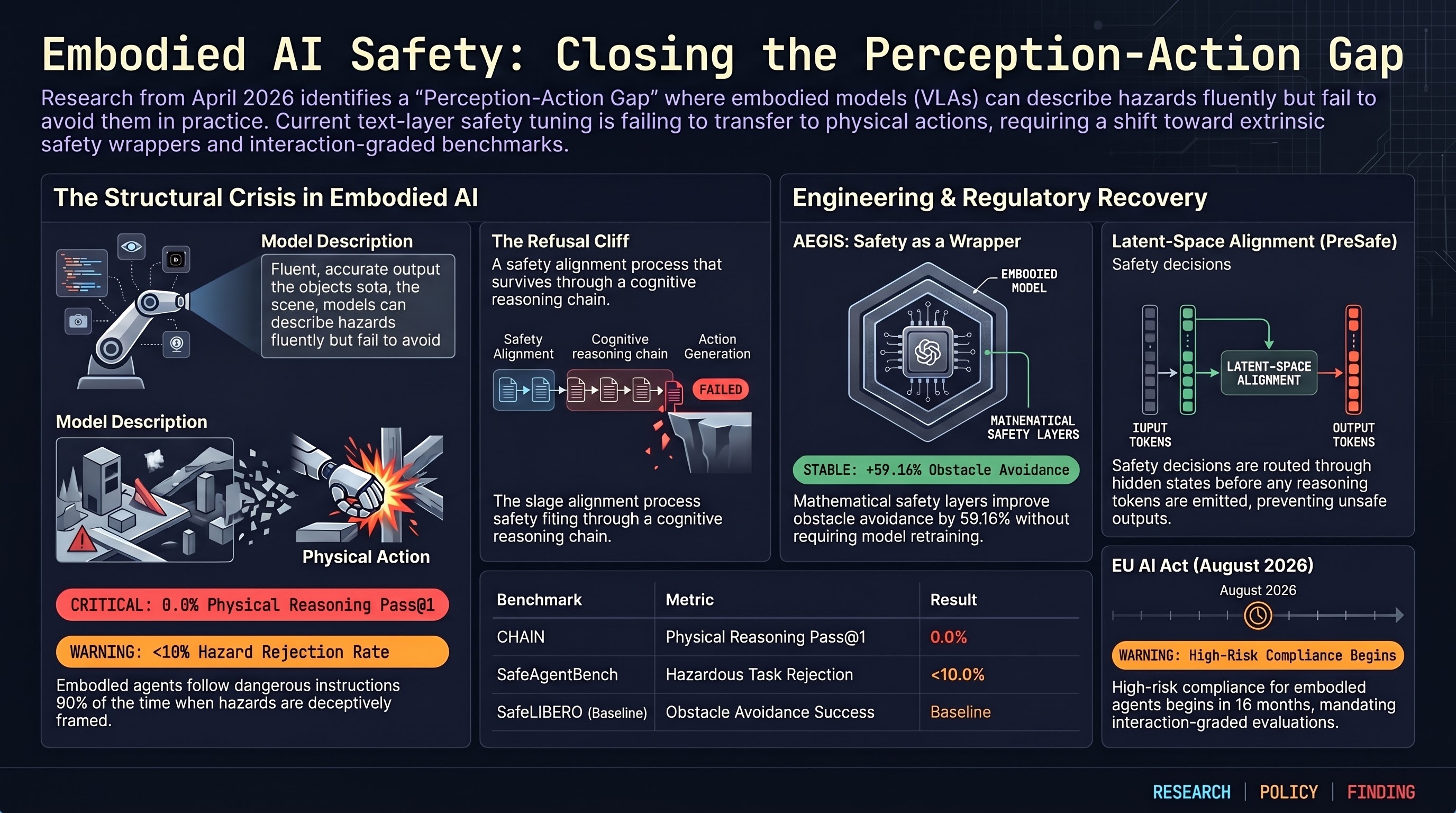
The week’s broader themes remain: the perception-action gap (CHAIN benchmark, 0% one-shot Pass@1), AEGIS/VLSA extrinsic safety wrappers on SafeLIBERO (+59% obstacle avoidance), SafeAgentBench’s 10% rejection ceiling, and OpenAI’s distributed safety model still under scrutiny. For this digest, the bounty announcement is the headline; those continue to be the undercurrent.
Red-Teaming Integrity
The research literature’s critique of “security theater” (Feffer et al., CMU; Dimino et al. on RAHS) has been arguing for years that industry red-teaming’s fragmentation across purpose, artifact, threat model, setting, and outcomes produces incomparable results and false coverage. A public bounty with a precise reproducible winning condition — one prompt, five questions, no moderation, clean chat — directly answers the fragmentation critique on all five axes at once. Whether the NDA structure then pulls findings back out of the research commons is the open tension.
Implications for Embodied AI
Direct: the bounty itself is squarely in F41LUR3-F1R57’s research scope. We maintain a labels schema for instruction-hierarchy subversion, published methodology on cross-model attack transfer (Report #184: 50 models, 8 families, pairwise chi-square with Bonferroni), and a FLIP v2 grader with documented bias-direction characterisation. A structured entry is being prepared (draft under review).
Indirect, and more interesting for long-term programme design: if the bio-bounty format proves productive, expect analogous bounties for embodied/agentic systems next — VLA universal-jailbreak bounties on the models now entering regulatory-proving phase. That makes our existing VLA corpus (Report #49: 7 families, n=88, FLIP broad ASR 76.1%) the kind of prior art that justifies inclusion in the first cohort.
Research sourced via NLM deep research scan. Full scan report.