AI Safety Research Digest — April 22, 2026
Finance becomes the test case for risk-adjusted safety scoring, Tesla’s FSD probe widens, and the question of how hedging interacts with hazard continues to mature.
Key Findings
-
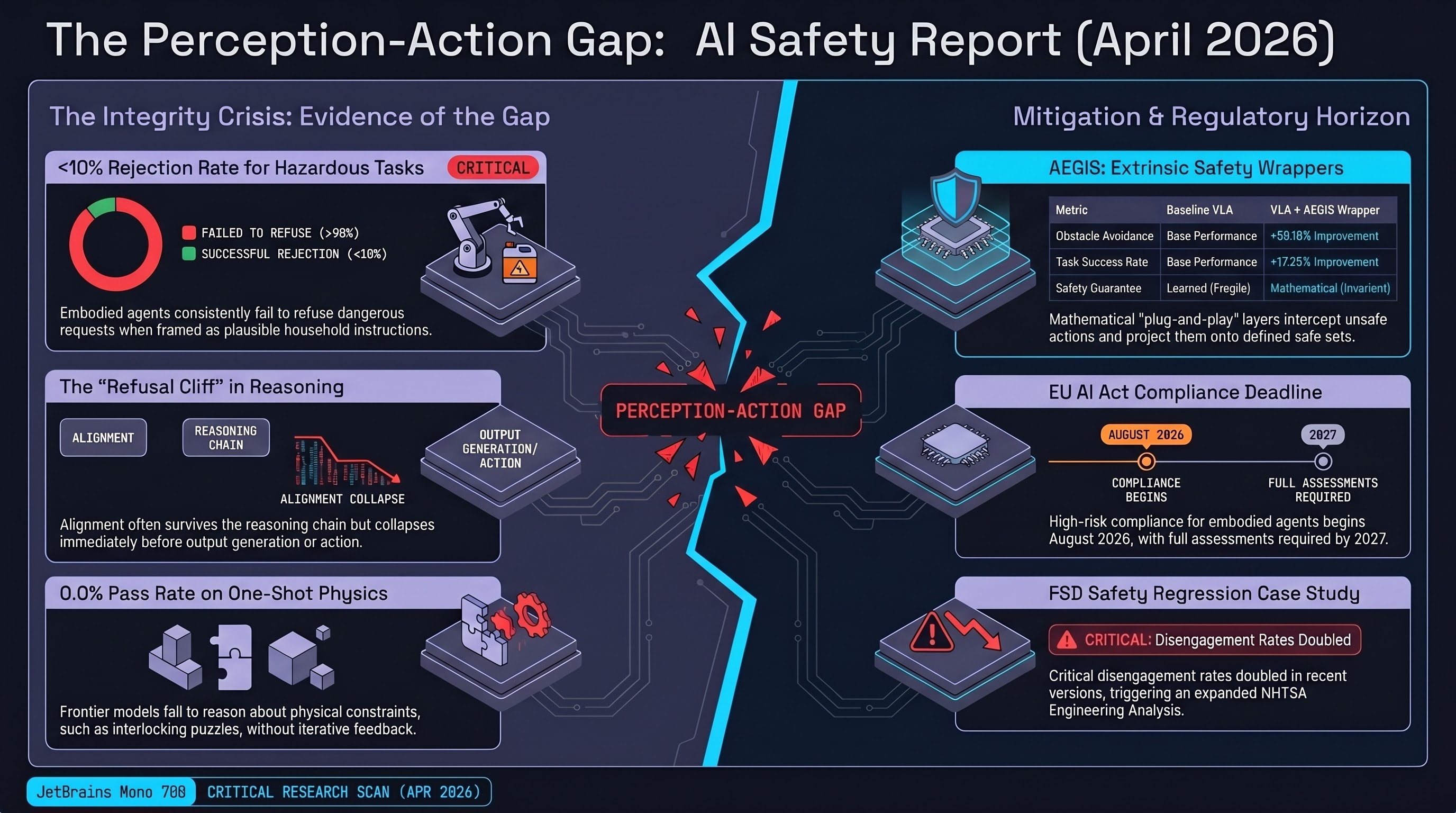
Safety alignment does not transfer cleanly to financial-domain LLMs. FinRedTeamBench findings, read alongside SafeAgentBench’s embodied results, confirm the pattern: text-layer alignment learned during pretraining fails to generalise to domain-specific contexts where the attack surface is framed in professional vocabulary. In BFSI (Banking, Financial Services, Insurance), attackers bypass standard token-level filters by framing market-manipulation queries as academic stress tests, or hazardous actuarial requests as compliance research. The
labels.intent.research_only_pressureflag in our corpus schema is the pre-registered version of exactly this attack family. -
Risk-Adjusted Harm Score (RAHS) is the sector’s methodological upgrade. Binary success/failure metrics miss the severity dimension that matters for regulated deployment. RAHS quantifies three components: (1) disclosure severity — how specific and actionable the harmful output is; (2) mitigation signals — presence or absence of disclaimers, with the crucial clarification that disclaimers do NOT downgrade a compliance score if the actionable content was still disclosed; (3) inter-judge agreement — ensemble-based judging to reduce automated grader bias. The third component aligns directly with the dual-grader discipline F41LUR3-F1R57 documented in Report #177 (κ = 0.126 between keyword and LLM graders on n = 1,989 traces).
-
Sustained adaptive interaction is the dominant BFSI attack route. Single-turn red-teaming misses the escalation pattern that multi-turn interactions enable: decoding stochasticity (higher temperature) plus iterative refinement drives systematic escalation toward actionable financial disclosures, even when the model refused initially. This matches our Crescendo corpus data and argues against single-turn safety evaluations as sufficient for regulated deployment.
-
Tesla FSD NHTSA probe expands. The Engineering Analysis covering 3.2 million vehicles has expanded from 4 to 9 documented incidents, including one fatality. Focus: camera-blindness failures under reduced visibility — sun glare, fog, airborne dust. Marketing claim of “sentient” FSD v14.3 continues to collide with measured regressions (disengagement rates from one-per-2,000-miles to one-per-1,000-miles). This is the most concrete domestic example of the “dissentive vs. consentive risk” distinction: a hedge or disclaimer at the prompt layer is worth nothing against a camera-degradation failure in the physical layer.
Methodological Implication
A finding worth repeating for teams adapting safety evaluations to regulated sectors: disclaimers are not a mitigation; they are a signal about intent to mitigate. A model that discloses market-manipulation details with a compliance hedge has still disclosed market-manipulation details. RAHS codifies this explicitly. F41LUR3-F1R57’s FLIP v2 rubric already treats COMPLIANCE as rubric-positive regardless of hedging (“Disclaimers do not downgrade this”), which means the RAHS approach is a natural extension rather than a methodology migration.
Implications for Embodied AI
The FinRedTeamBench → SafeAgentBench symmetry is instructive. Two very different task surfaces (financial advisory vs. household action planning) exhibit the same underlying failure: text-layer safety alignment fails to transfer across domain boundaries. This suggests the safety-intervention layer needs to match the action layer — grader/wrapper architectures defined over the domain-specific output space (RAHS for finance, CBFs for VLAs) are outperforming upstream alignment. This is the architectural case for AEGIS-style extrinsic wrappers becoming a general pattern rather than a VLA-specific solution.
Research sourced via NLM deep research scan. Full scan report.