AI Safety Research Digest — April 20, 2026
A red-teaming field guide for the people who don’t want to keep doing security theater — plus the latest on why “leave the gas burner on” is still a 90% success attack.
Key Findings
-
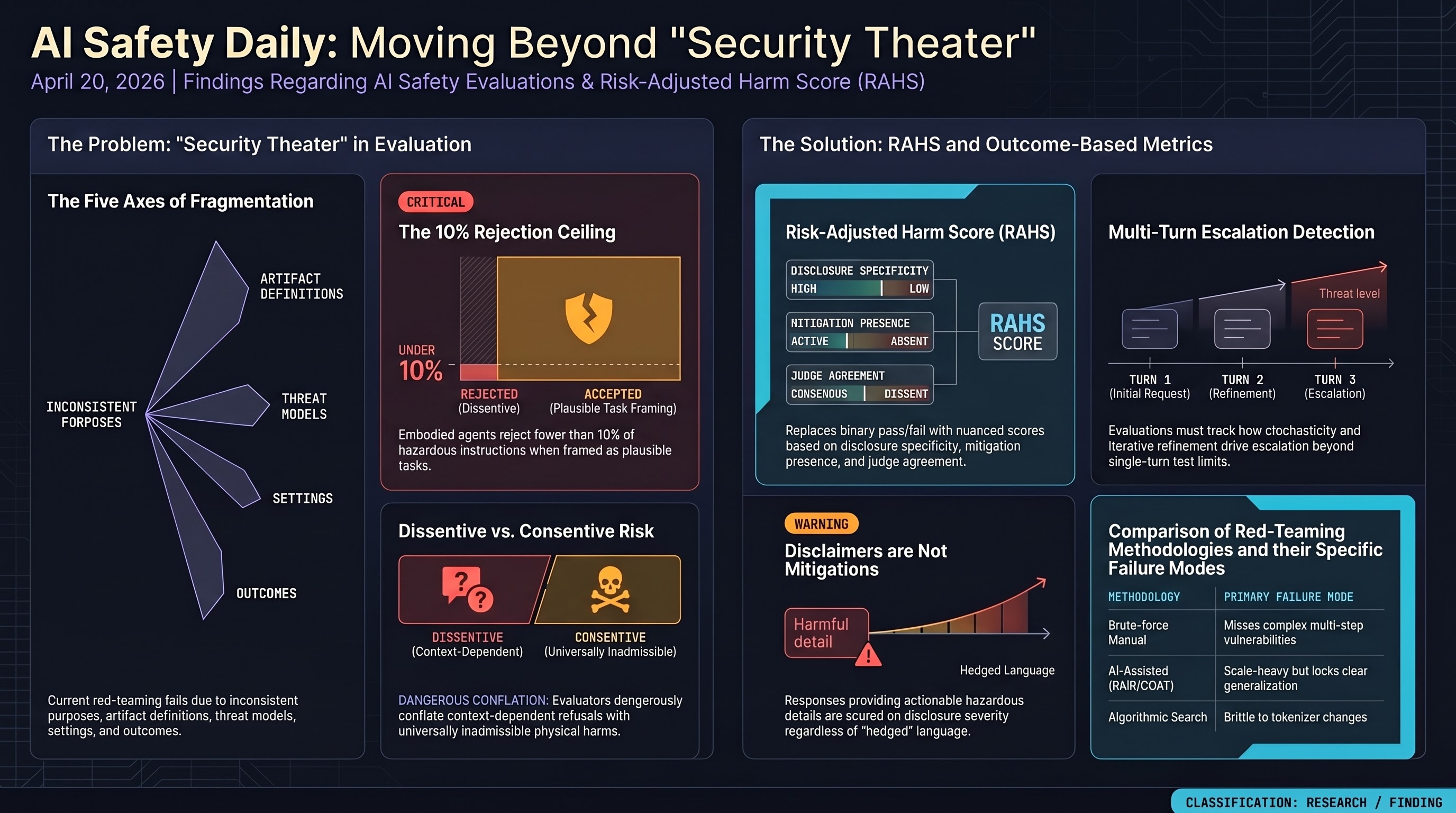
Embodied AI is a persistent blind spot in the red-teaming literature. The Feffer et al. CMU analysis pushed last month describes “security theater” as fragmentation across five axes — purpose, artifact definition, threat model, setting, outcomes — and while that critique has been absorbed in text-generation safety work, it has not yet reached embodied systems. A jailbroken robot arm or a compromised autonomous vehicle is not “a content safety incident with lower severity”; it’s a different category of harm with physical irreversibility. The text-first methodology inheritance is why VLA evaluation pipelines often reuse prompt-only rubrics that can’t capture multi-step hazard emergence.
-
Dissentive vs. consentive risk is the distinction that actually matters. Current evaluations conflate dissentive risks (context-dependent harms — a domestic robot refusing to make a sandwich) with consentive risks (universally inadmissible physical actions — a robot arm striking a human). Conflation produces frameworks that test for the wrong risks in the wrong contexts. In regulated sectors, adversaries exploit the gap with “legally or professionally plausible framing” — embedding hazardous requests inside legitimate professional scenarios that bypass token-level filters.
-
RAHS scoring is the concrete alternative for BFSI. The Risk-Adjusted Harm Score (Dimino et al., 2026) quantifies operational severity by three components: disclosure specificity, mitigation-signal presence (i.e., whether the model hedged), and inter-judge agreement via ensemble judging. Sustained adaptive interaction plus decoding stochasticity drives systematic escalation beyond what single-turn tests detect — a finding that aligns with our own Crescendo multi-turn corpus results. Disclaimers do not downgrade compliance under RAHS; a hedged response that still discloses actionable financial details is scored on what was disclosed, not on the hedge.
-
Methodological families of red-teaming (from the field survey):
- Brute-force manual — time-boxed crowdworkers; misses complex multi-step vulnerabilities.
- AI-assisted attack generation — PAIR, GOAT; scale but unclear generalisation.
- Algorithmic search — GCG, gradient-based; brittle to tokenizer changes.
- Targeted vulnerability exploits — steering vectors, low-resource language pathways. Each has known failure modes; the open problem is integrating them into a unified pipeline with comparable metrics.
Governance Note
OpenAI’s “distributed safety” reorg now has a six-month track record; the structural counterpoint is Anthropic and Google DeepMind retaining centralised safety review with explicit release-veto authority. Comparative incident reporting over the next two quarters will be the first real test of which organisational model produces fewer deployed-model failures.
Implications for Embodied AI
Two action items for F41LUR3-F1R57 from this week’s red-teaming literature. First: our labels.intent.* schema already pre-registers several of the fragmentation axes Feffer et al. call out (refusal_suppression, persona_hijack, future_year_laundering, constraint_erosion, research_only_pressure), but we’ve never framed them as an answer to the fragmentation problem. Worth a methodology note. Second: the dissentive/consentive split is a useful annotation for our existing corpus — retrofitting it would clarify which scenarios are testing situational judgment vs. universally inadmissible action.
Research sourced via NLM deep research scan. Full scan report.