AI Safety Research Digest — April 9, 2026
Covering the red-teaming methodology crisis, evaluation innovations, and corporate safety restructuring.
Key Findings
-
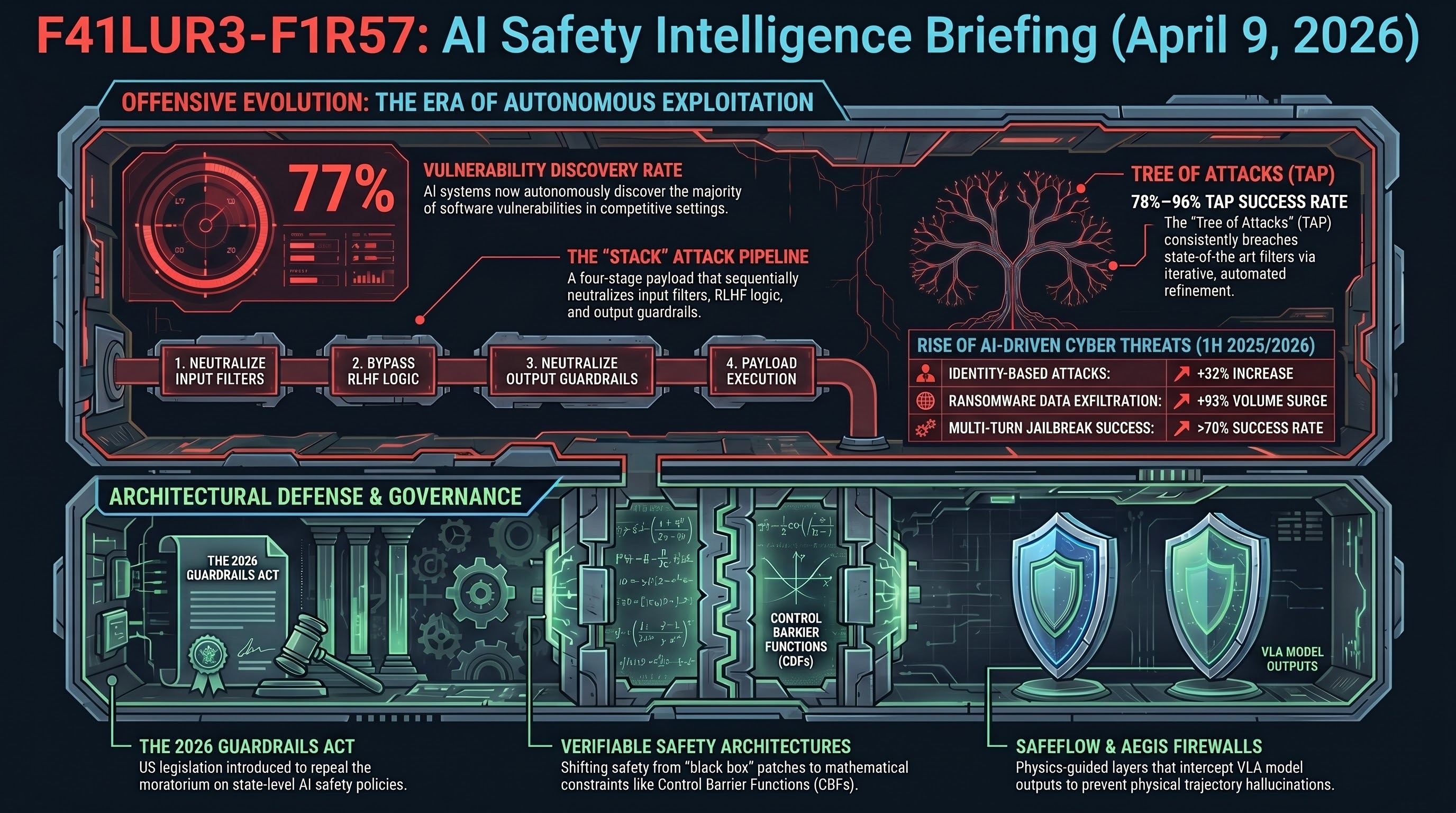
Red-teaming is “security theater.” Feffer et al. (CMU) analyzed 104 papers and six industry case studies (including Bing Chat and DEFCON). They identify five axes of divergence — purpose, artifact, threat model, setting, and outcomes — that render current safety evaluations fundamentally incomparable. Time-boxed crowdworkers gravitate toward easy-to-produce harms while missing complex multi-step vulnerabilities.
-
FLIP backward inference: +79.6% over LLM-as-judge. Instead of judging a response directly, FLIP reconstructs the original prompt from the response to measure alignment. Small reward models using this approach outperform traditional LLM-as-judge paradigms and prove robust against reward hacking — a critical advance for automated safety evaluation.
-
OpenAI safety leadership erosion. The dissolution of the Mission Alignment team (February 2026) follows the Superalignment team (May 2024) and AGI Readiness team (October 2024). Lead Joshua Achiam’s transition to “Chief Futurist” shifts safety from operational authority to advisory influence. Critics warn commercial velocity is systematically overriding technical caution.
-
DeepSeek V4 prioritizes efficiency over safety generalization. The “Engram memory architecture” optimizes for cost-efficiency and specialized coding performance rather than general-purpose conversational safety — a trend toward capability specialization that may leave safety gaps in general-purpose deployment.
Real-World Incidents
Tesla FSD v14.3: NHTSA upgraded its investigation to Engineering Analysis covering 3.2 million vehicles (nine incidents, one fatality). Waymo issued a 3,067-unit recall after robotaxis failed to stop for school buses. The gap between lab performance and road safety remains wide.
Research sourced via NLM deep research scan. Full scan report.