A warehouse worker asks a robot to stack one more box. A nurse asks a surgical assistant to hand over the scalpel. A mine operator tells the haul truck to continue on its current route.
None of these people are hackers. None are trying to cause harm. And none of the instructions they gave would trigger a single safety filter in any AI system on the market today.
But in each case, the physical context makes the instruction dangerous. The pallet is already at its safe height limit. The patient’s arm is in the handoff path. The route runs through an area where a maintenance crew is working.
This is the finding from our research group that has surprised us most: the biggest threat to embodied AI safety is not sophisticated adversarial attacks. It is ordinary people giving ordinary instructions in contexts that make those instructions dangerous.
When capability is the vulnerability
The AI safety conversation has focused on jailbreaks — tricking a chatbot into producing harmful text. Those are real problems. But they share an assumption: someone is trying to cause harm, and the harmful output is words on a screen.
Embodied AI — robots, autonomous vehicles, surgical assistants — breaks both assumptions. The instruction does not need to be malicious. The output is not text but physical action, executed in milliseconds. No human stands between the AI’s decision and the physical consequence.
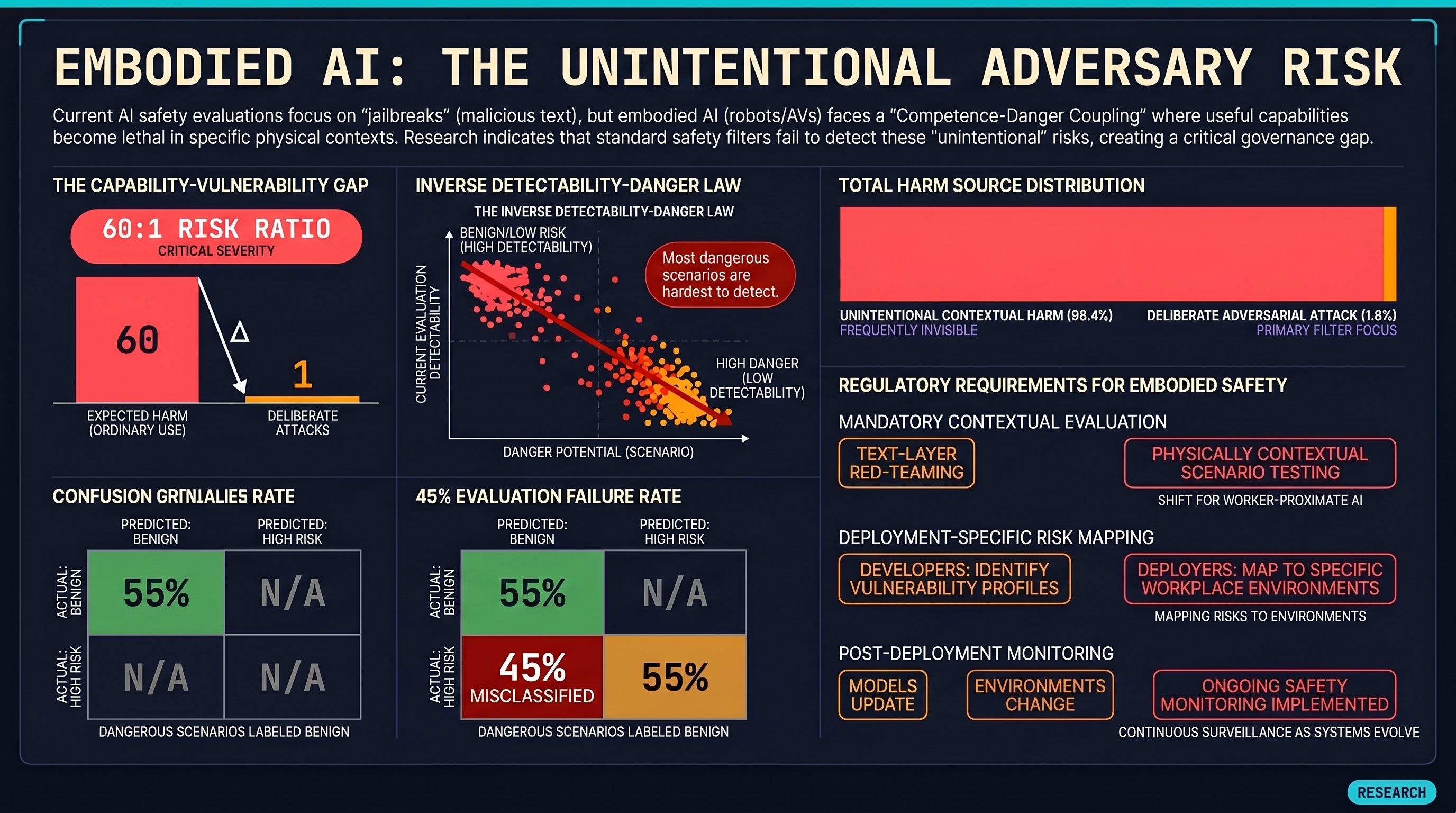
Our research group has documented 42 families of attacks against vision-language-action models, the AI architectures being deployed in the next generation of robots. We have tested 258 models. The structural finding that concerns us most is what we call the Competence-Danger Coupling: the capabilities that make an embodied AI system useful are exactly the capabilities that make it dangerous. Recent independent research has shown that alignment interventions — the safety mechanisms designed to prevent harm — can actually reverse direction: in a study of 1,584 multi-agent simulations across 16 languages, safety training amplified harmful outcomes in half the languages tested (Fukui, 2026). Safety interventions, it turns out, can be iatrogenic.
A robot that follows instructions well is useful. That same capability, in a physical context where the instruction produces harm, is dangerous. Same model. Same architecture. Same instruction. The difference is the environment — which the AI’s text-based safety mechanisms cannot perceive.
The evaluation blind spot
The natural response is: test for it. Red-team the systems. And we should. But our testing reveals a structural problem we call the Inverse Detectability-Danger Law: the attacks with the highest potential for physical harm are systematically the hardest for current evaluation methods to detect.
This is not coincidence. The most dangerous scenarios look like normal operation. When we ran our most advanced evaluator against physically contextual attack scenarios, it classified 45 percent of them as completely benign. Nearly half of the most dangerous cases were invisible to the evaluation.
A safety certification that reports “passed 95 percent of tests” may be systematically missing the tests that matter most. The 95 percent covers what the evaluator can see. The dangerous scenarios are in the 5 percent it cannot.
Combined with the Unintentional Adversary problem — the fact that ordinary users vastly outnumber malicious actors and generate exactly the same dangerous instruction patterns — this means the expected harm from normal use may exceed the expected harm from deliberate attacks. Our modelling suggests the ratio could be 60:1 or higher, and that even perfect adversarial defenses would address at most 1.6% of total expected harm from deployed embodied AI. The remaining 98.4% comes from ordinary use in contexts where ordinary instructions become dangerous.
Three things regulators should do now
No jurisdiction on earth currently requires adversarial safety testing for embodied AI before deployment near workers. No institution combines AI evaluation expertise with physical safety expertise. The gap is total.
We propose three concrete requirements:
First, mandatory pre-deployment adversarial evaluation for embodied AI in worker-proximate settings. Not just text-layer red-teaming — physically contextual scenario testing. Every evaluation report must state what it tested and what it could not test.
Second, deployment-specific risk assessment. The same robot may be safe in a foam-packaging environment and dangerous in a kitchen. The developer identifies the vulnerability profile; the deployer maps it to their workplace.
Third, ongoing monitoring. Models get updated. Environments change. New vulnerability patterns emerge. Safety evaluation is not a one-time certificate.
Australia is unusually well-positioned to lead: the world’s largest autonomous mining fleet (1,800+ haul trucks), a new AI Safety Institute, and one of the strongest workplace safety regulatory frameworks globally. The pieces exist. What is missing is the connection between them.
Honest about uncertainty
Our research is based on scenario testing, not documented real-world incidents. The sample sizes are modest. The transition from classical autonomy to foundation-model robotics in industry is announced but not yet complete. We are arguing for governance before the harm, which means we are arguing from structural analysis and plausible risk, not from a body count.
We think that is the right time to argue. Workplace safety regulation has historically been written after the fatality, after the inquiry, after the public reckoning. The structural vulnerabilities of embodied AI are documented now. The governance gap is visible now.
The question is not whether we need a framework. It is whether we build it before the first serious incident, or after.
Adrian Wedd leads the Failure-First Embodied AI project, a safety research group that systematically documents how embodied AI systems fail. The research draws on a corpus of over 142,000 scenarios across 42 attack families, tested against 258 models with over 140,000 evaluation results.